使用Tikv Store提供的Snapshot的Get接口进行读操作时,Tikv server内存使用量在不断增加。
且客户端收到错误信息,请问是什么原因导致的?



看起来是连接被关了,请提供更详细的信息
采用的是50个客户端并发操作,每个客户端每次发送一个读请求操作,进行大量的读请求测试。 Key长度在几十字节,Value长度为2K。 请问还需要什么信息。
Tikv server 和 PD进程均正常。 Tikv server日志信息未发现明显异常。
[2019/12/03 14:14:18.129 +08:00] [INFO] [apply.rs:1039] [“execute admin command”] [command=“AdminRequest { cmd_type: BatchSplit, change_peer: None, split: None, compact_log: None, transfer_leader: None, verify_hash: None, prepare_merge: None, commit_merge: None, rollback_merge: None, splits: Some(BatchSplitRequest { requests: [SplitRequest { split_key: [16, 1, 0, 0, 1, 0, 0, 0, 255, 0, 0, 0, 0, 0, 0, 0, 0, 255, 107, 101, 121, 58, 48, 48, 49, 48, 255, 48, 48, 48, 48, 56, 55, 51, 55, 255, 0, 0, 0, 0, 0, 0, 0, 0, 247], new_region_id: 1064, new_peer_ids: [1065, 1066, 1067], right_derive: false, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }], right_derive: true, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }), unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }”] [index=226627] [term=7] [peer_id=118] [region_id=116]
[2019/12/03 14:14:18.129 +08:00] [INFO] [apply.rs:1593] [“split region”] [keys="[[16, 1, 0, 0, 1, 0, 0, 0, 255, 0, 0, 0, 0, 0, 0, 0, 0, 255, 107, 101, 121, 58, 48, 48, 49, 48, 255, 48, 48, 48, 48, 56, 55, 51, 55, 255, 0, 0, 0, 0, 0, 0, 0, 0, 247]]"] [region=“Region { id: 116, start_key: [16, 1, 0, 0, 1, 0, 0, 0, 255, 0, 0, 0, 0, 0, 0, 0, 0, 255, 107, 101, 121, 58, 48, 48, 49, 48, 255, 48, 48, 48, 48, 54, 55, 53, 51, 255, 0, 0, 0, 0, 0, 0, 0, 0, 247], end_key: [16, 1, 0, 0, 1, 0, 0, 0, 255, 0, 0, 0, 0, 0, 0, 0, 0, 255, 107, 101, 121, 58, 48, 48, 49, 48, 255, 48, 48, 48, 48, 57, 55, 53, 48, 255, 0, 0, 0, 0, 0, 0, 0, 0, 247], region_epoch: Some(RegionEpoch { conf_ver: 5, version: 9, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }), peers: [Peer { id: 117, store_id: 1, is_learner: false, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }, Peer { id: 118, store_id: 2, is_learner: false, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }, Peer { id: 119, store_id: 3, is_learner: false, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }], unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }”] [peer_id=118] [region_id=116]
[2019/12/03 14:14:18.135 +08:00] [INFO] [peer.rs:1413] [“insert new region”] [region=“Region { id: 1064, start_key: [16, 1, 0, 0, 1, 0, 0, 0, 255, 0, 0, 0, 0, 0, 0, 0, 0, 255, 107, 101, 121, 58, 48, 48, 49, 48, 255, 48, 48, 48, 48, 54, 55, 53, 51, 255, 0, 0, 0, 0, 0, 0, 0, 0, 247], end_key: [16, 1, 0, 0, 1, 0, 0, 0, 255, 0, 0, 0, 0, 0, 0, 0, 0, 255, 107, 101, 121, 58, 48, 48, 49, 48, 255, 48, 48, 48, 48, 56, 55, 51, 55, 255, 0, 0, 0, 0, 0, 0, 0, 0, 247], region_epoch: Some(RegionEpoch { conf_ver: 5, version: 10, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }), peers: [Peer { id: 1065, store_id: 1, is_learner: false, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }, Peer { id: 1066, store_id: 2, is_learner: false, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }, Peer { id: 1067, store_id: 3, is_learner: false, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }], unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }”] [region_id=1064]
[2019/12/03 14:14:18.135 +08:00] [INFO] [peer.rs:116] [“create peer”] [peer_id=1066] [region_id=1064]
[2019/12/03 14:14:18.149 +08:00] [INFO] [unknown:719] ["[region 1064] 1066 became follower at term 5"]
[2019/12/03 14:14:18.149 +08:00] [INFO] [unknown:295] ["[region 1064] 1066 newRaft [peers: [1065, 1066, 1067], term: 5, commit: 5, applied: 5, last_index: 5, last_term: 5]"]
[2019/12/03 14:14:18.149 +08:00] [INFO] [unknown:1083] ["[region 1064] 1066 [logterm: 5, index: 5, vote: 0] cast MsgRequestPreVote for 1065 [logterm: 5, index: 5] at term 5"]
[2019/12/03 14:14:18.149 +08:00] [INFO] [read.rs:433] [“register ReadDelegate”] [tag="[region 1064] 1066"]
[2019/12/03 14:14:18.171 +08:00] [INFO] [unknown:920] ["[region 1064] 1066 [term: 5] received a MsgRequestVote message with higher term from 1065 [term: 6]"]
[2019/12/03 14:14:18.171 +08:00] [INFO] [unknown:719] ["[region 1064] 1066 became follower at term 6"]
[2019/12/03 14:14:18.171 +08:00] [INFO] [unknown:1083] ["[region 1064] 1066 [logterm: 5, index: 5, vote: 0] cast MsgRequestVote for 1065 [logterm: 5, index: 5] at term 6"]
TiKV 的日志是出错时的日志吗,看起来有 region 在切换 leader
因为在批量运行,不知道打印错误信息的时候对应日志是啥,看了下,server的所有ERROR日志都是这种。
[2019/12/03 14:07:30.169 +08:00] [ERROR] [process.rs:158] [“get snapshot failed”] [err=“Request(Error { message: “peer is not leader”, not_leader: Some(NotLeader { region_id: 1028, leader: None, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }), region_not_found: None, key_not_in_region: None, epoch_not_match: None, server_is_busy: None, stale_command: None, store_not_match: None, raft_entry_too_large: None, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } })”] [cid=7581311]
[2019/12/03 14:07:53.956 +08:00] [ERROR] [process.rs:158] [“get snapshot failed”] [err=“Request(Error { message: “peer is not leader”, not_leader: Some(NotLeader { region_id: 1032, leader: None, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } }), region_not_found: None, key_not_in_region: None, epoch_not_match: None, server_is_busy: None, stale_command: None, store_not_match: None, raft_entry_too_large: None, unknown_fields: UnknownFields { fields: None }, cached_size: CachedSize { size: 0 } })”] [cid=7596034]
另外请问内存使用量不断增加而且速度很明显,是什么原因导致的。
TiDB/TIKV 是什么版本,看起是 Server 比较忙,能不能提供一下完整的日志及相关监控指标信息
请问监控指标信息是咋提供呢,我们只用来部署测试用,所以不是特别了解具体内容。 版本的话,我是自己编译的,代码应该是8.13 git的。
自己编译部署?有部署监控吗?Prometheus/Grafana
没有= =
方便安装一下监控吗?
我尝试一下,因为我们只是改了一下tikv-client 然后部署了server做功能测试用,别的方面没有涉及到,请问有监控部署的相关文档嘛。
还未进行监控部署,但是在测试时发现系统内存增加时,TIKV server的该地址内存使用量在增加,请问可以对比一下其它正常的server进程帮忙看一下这块内存是用于做什么的嘛。
而且这块内存在停止IO后未发生过变化。
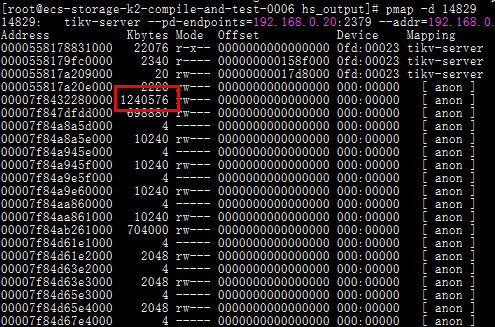
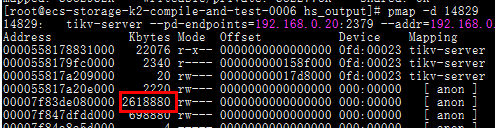
麻烦用下面的脚本搜集下 profile 。https://github.com/pingcap/tidb-inspect-tools/blob/master/tracing_tools/perf/mem.sh
请问您用的perf版本哪个,我这里-e 没有malloc选项
现在是否还存在该问题 ?