【系统版本 & kernel 版本】
CentOS Linux release 7.6.1810 (Core)
4.20.10-1.el7.elrepo.x86_64
【TiDB 版本】
3.0.5
【我做了什么】
1 创建一张存放 3000万数据的 分区表
CREATE TABLE `dd_range` (
`seller_date` date NOT NULL COMMENT '销售日期',
`id` varchar(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL
PRIMARY KEY (`id`,`seller_date`)
)
PARTITION BY RANGE ( year(`seller_date`) ) (
PARTITION p0 VALUES LESS THAN (2016),
PARTITION p1 VALUES LESS THAN (2020),
PARTITION p2 VALUES LESS THAN (2026)
);
MySQL [sbtest]> show tables;
+--------------------------------+
| Tables_in_sbtest |
+--------------------------------+
| dd_range |
| table_1 |
+--------------------------------+
2 rows in set (0.00 sec)
MySQL [sbtest]>
MySQL [sbtest]>
MySQL [sbtest]>
MySQL [sbtest]> SELECT COUNT( 1 ) num FROM dd_range PARTITION(p0);
+----------+
| num |
+----------+
| 30000000 |
+----------+
1 row in set (7.71 sec)
MySQL [sbtest]>
MySQL [sbtest]>
MySQL [sbtest]> SELECT COUNT( 1 ) num FROM dd_range PARTITION(p0) GROUP BY id HAVING count( 1 ) > 1;
Empty set (18.22 sec)
MySQL [sbtest]>
MySQL [sbtest]>
MySQL [sbtest]>
2 测试分页查询的数据是否会有重复数据, 分页查询 100万数据; 写入到 dist/all.txt文件中
def local_write_file(self):
for i in range(0, 100):
offset = 10000
sql = "SELECT id FROM dd_range PARTITION(p0) LIMIT %d, %d" % ((i * offset), offset)
# 执行SQL语句
self.cursor.execute(sql)
# 获取所有记录列表
rows = self.cursor.fetchall()
# 将所有内容写入到本地
for row in rows:
self.save_file('./dist/', 'all.txt', row[0] + '
')
print (sql)
# 关闭数据库连接
self.db.close()
生成的文件结果
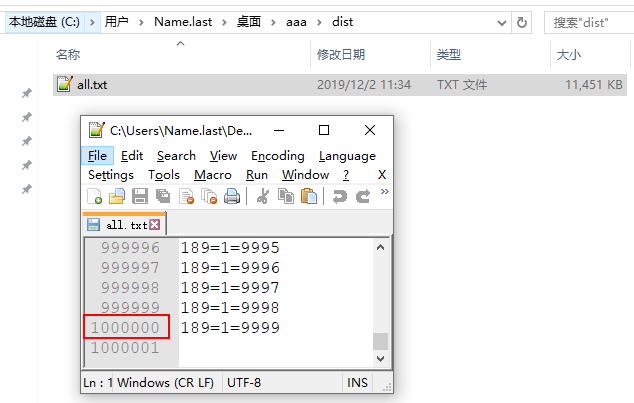
3 将文件中的数据导入到一张新的 空表中 table_1
CREATE TABLE `table_1` (
`id` varchar(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
MySQL [sbtest]>
MySQL [sbtest]>
MySQL [sbtest]> SELECT COUNT( 1 ) num FROM table_1;
+---------+
| num |
+---------+
| 1000000 |
+---------+
1 row in set (0.64 sec)
MySQL [sbtest]>
MySQL [sbtest]>
MySQL [sbtest]> SELECT
-> COUNT( t2.num )
-> FROM
-> ( SELECT COUNT( 1 ) num FROM table_1 GROUP BY id HAVING count( 1 ) > 1 ) t2;
+-----------------+
| COUNT( t2.num ) |
+-----------------+
| 10000 |
+-----------------+
1 row in set (3.68 sec)
MySQL [sbtest]>
MySQL [sbtest]>
MySQL [sbtest]>
【问题】
为什么我查询出来的数据会有 10000条的重复数据