为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
###【TiDB 版本】
3.0.5
###【问题描述】
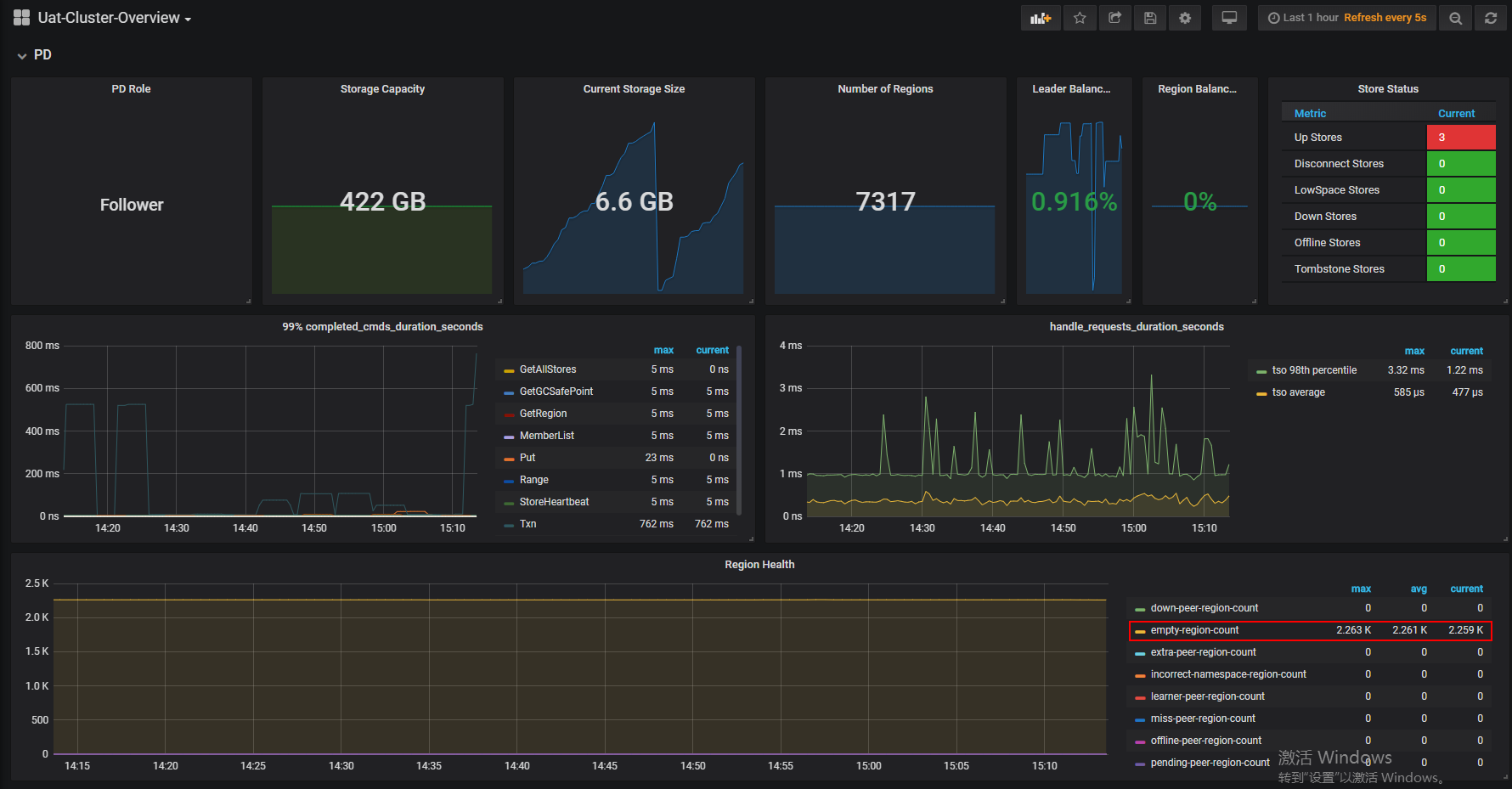
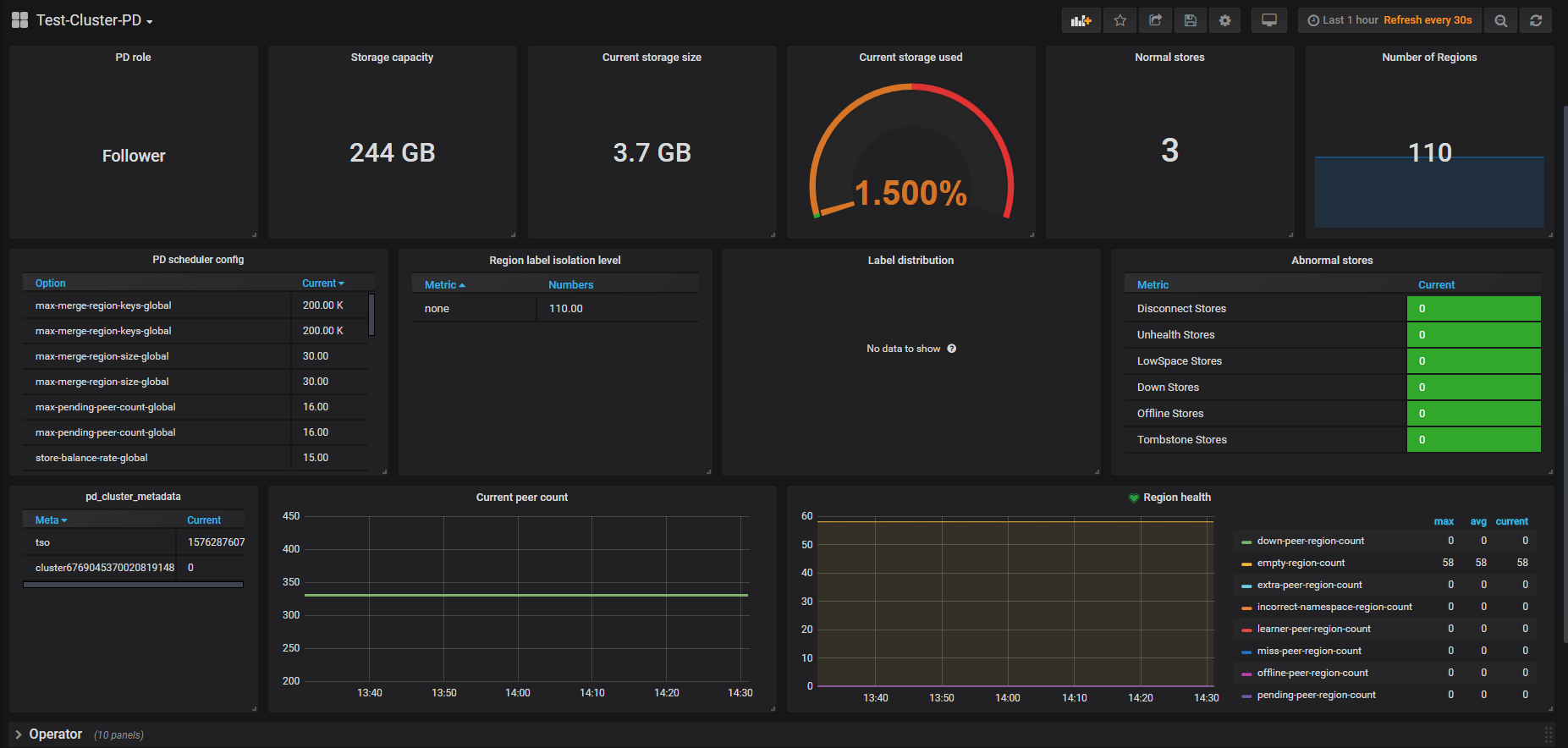
Cluster-Overview --> PD --> Region Health --> empty-region-count
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
###【TiDB 版本】
3.0.5
###【问题描述】
Cluster-Overview --> PD --> Region Health --> empty-region-count
这个应该是说集群中空的 region 数量,这部分 region 理论上可以被 merge 。
这个问题对集群来说会有什么样的影响呢? 我应该如何处理这样的问题?
没什么影响,虽然是空的,但还是健康的,最终是会合并的。
如果集群中存在很多空表,或者存在非常多的 truncate 、drop 或者 delete 全表的操作,那就会产生空 region ,但问题也没有,最终可以 merge 。
就是 region 越多,集群的负载也会变高,但你这边总 region 数才几千,所以造成的影响也没有。
了解了谢谢老师
![]()
![]()
![]()
请问合并的周期怎么设置?等了一天都还没有合并, 还有region感觉太多了,有办法设置region的min size吗?版本v3.0.7
region 默认大小是 96M,小 region 太多可以设置 region merge 参数, 设置下 这三个参数 max-merge-region-size,max-merge-region-keys,merge-schedule-limit ,再从监控看 region 的数量变化,如果 region 本身大小已经合理,使用 merge 功能也不会减少 region 个数,从性能考虑,建议扩容 TiKV 存储节点。
此前已经按中文官方文档设置过这三个参数,但是空region没合并,监控里面的empty-region-count每次删除表再导数据只会增加不会减少。
pd 相关参数有调整过吗?可以使用如下文档:http://pingcap.com/docs-cn/stable/reference/tools/pd-control/#下载安装包 ,用 pd-ctl 看下配置,默认 1 h 后才会进行 region merge,跟这个参数 split-merge-interval 有关。
发现监控页面左上角的instance可以选两台机器,两台看到的empty region数还不一样,然后我重启了一台,重启后的机器就没有metric上报了,怀疑是脑裂了,早上的时候还能选三台
看左上角第一个 dashboard,PD role,只有 Leader 的数据才是最新的,通过左上角的下拉列表选到 leader PD 上,数据才是可信的。 不存在脑裂哈。
发现是namespace-classifier设置为table的问题,看了下源码,少于1m认为是空region? 估计空region都是系统自带的表。想改下配置看下效果,然后不知道怎么用tidb-ansible的命令改,修改完pd.yml后执行ansible-playbook rolling_update.yml 没改成功。请问有tidb-ansible详细文档吗?
namespace-classifier 默认是 table,默认情况下,region merge 不会进行表表合并,所以在客户有大量的 drop/truncate table, create table, drop database 的时候需要开启该参数(namespace-classifier = " default"),具体可以在中控节点修改 pd.yml 然后执行 ansible-playbook rolling_update.yml --tags=pd 来使修改生效。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。