为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.5
- 【问题描述】:
alertname = tidb_tikvclient_backoff_total 频繁告警
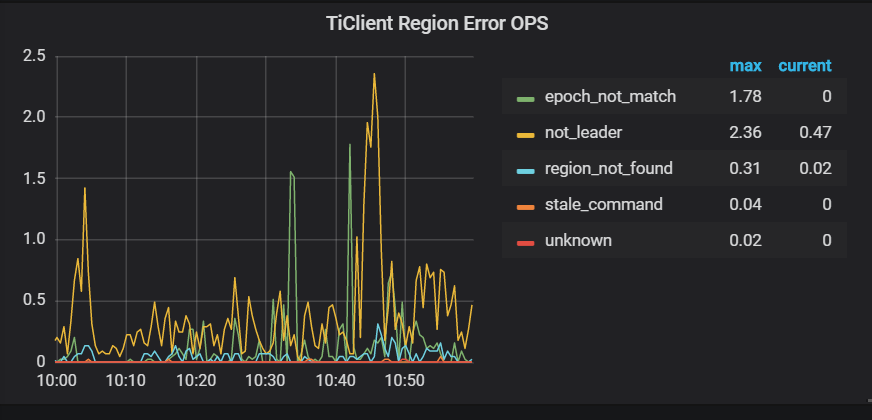
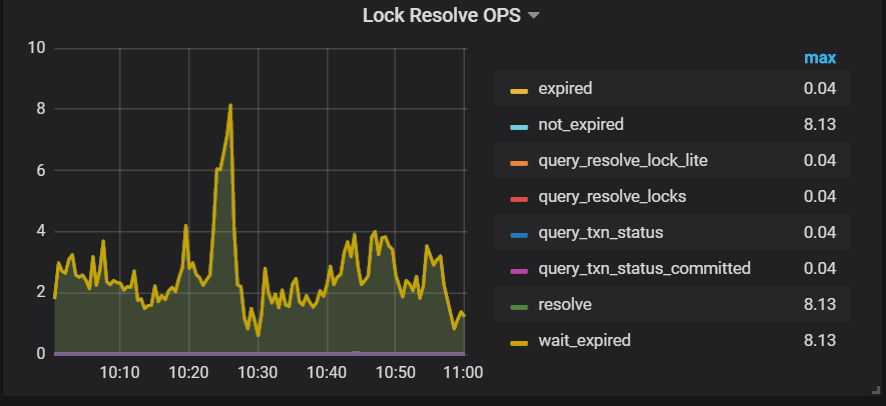
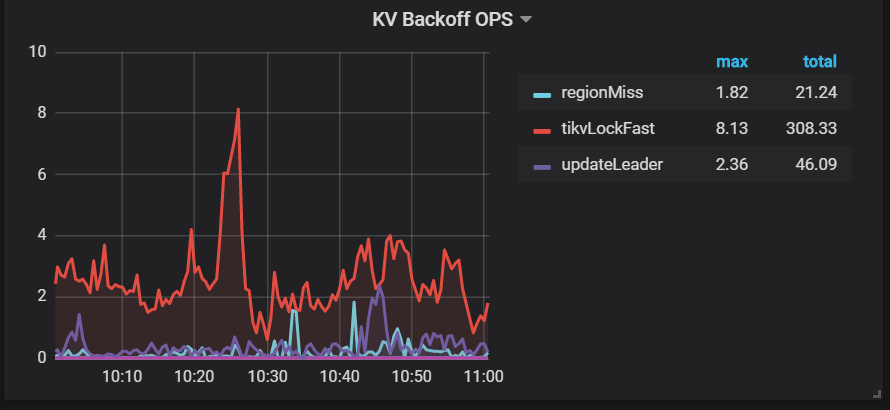
grafana监控情况:
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
alertname = tidb_tikvclient_backoff_total 频繁告警
grafana监控情况:
你好,根据第二三个监控,基本能对应 backoff 与 lock resolve 相关,也就是存在事务冲突。 麻烦检查 tidb.log 查找冲突,根据 startts 和 conflict_startts 找到冲突的 SQL
您好:TiDB集群的数据是通过DM将MySQL的数据增量同步到tidb,只有部分select操作。 在此情况下也会存在事务的冲突么?
你查看下 tidb.log ,grep -i conflict 看下。
tidb为3个节点:
分别查询三个节点上的日志:
node1: [2019/11/12 05:10:19.532 +08:00] [WARN] [session.go:418] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412485319233372170, conflictStartTS=412485319259586576, conflictCommitTS=412485319259586577, key={tableID=31, indexID=1, indexValues={412485319194050571, 1065140, }} primary={tableID=31, indexID=1, indexValues={412485319194050571, 1065140, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/12 05:10:19.660 +08:00] [WARN] [session.go:657] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412485319259586583, conflictStartTS=412485319259586578, conflictCommitTS=412485319272693761, key={tableID=33, handle=1260877} primary={tableID=31, indexID=1, indexValues={412485319233372170, 1065142, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/12 23:14:20.012 +08:00] [WARN] [session.go:418] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412502369210204178, conflictStartTS=412502369223311377, conflictCommitTS=412502369223311383, key={tableID=31, indexID=1, indexValues={412502369183989803, 1067739, }} primary={tableID=31, indexID=1, indexValues={412502369183989803, 1067739, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/13 02:34:19.583 +08:00] [WARN] [session.go:418] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412505514820239366, conflictStartTS=412505514846453769, conflictCommitTS=412505514846453770, key={tableID=31, indexID=1, indexValues={412505514794024971, 1068297, }} primary={tableID=31, indexID=1, indexValues={412505514794024971, 1068297, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/16 23:23:55.296 +08:00] [WARN] [session.go:419] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412593116978085925, conflictStartTS=412593117004300289, conflictCommitTS=412593117004300290, key={tableID=31, handle=1089316} primary={tableID=31, indexID=1, indexValues={412593116938764305, 1089316, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/19 11:04:59.850 +08:00] [WARN] [session.go:419] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412649442404466700, conflictStartTS=412649442430681098, conflictCommitTS=412649442430681101, key={tableID=31, handle=1101562} primary={tableID=31, indexID=1, indexValues={412649442378252309, 1101562, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/19 11:04:59.954 +08:00] [WARN] [session.go:661] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412649442456895524, conflictStartTS=412649442430681106, conflictCommitTS=412649442483109896, key={tableID=33, handle=1305961} primary={tableID=31, indexID=1, indexValues={412649442404466700, 1101564, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/20 00:17:55.274 +08:00] [WARN] [session.go:419] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412661914049445896, conflictStartTS=412661914062553111, conflictCommitTS=412661914062553114, key={tableID=31, indexID=1, indexValues={412661914023231491, 1104908, }} primary={tableID=31, indexID=1, indexValues={412661914023231491, 1104908, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/20 15:03:55.326 +08:00] [WARN] [session.go:419] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412675849637593113, conflictStartTS=412675849637593112, conflictCommitTS=412675849663807491, key={tableID=31, indexID=1, indexValues={412675849611378709, 1108379, }} primary={tableID=31, indexID=1, indexValues={412675849611378709, 1108379, }} [try again later]"] [txn=“Txn{state=invalid}”]
node2没有冲突日志
node3: [2019/11/16 23:23:55.277 +08:00] [WARN] [session.go:419] [sql] [label=internal] [error="[kv:9007]Write conflict, txnStartTS=412593116978085897, conflictStartTS=412593116938764305, conflictCommitTS=412593116978085920, key={tableID=31, handle=1089315} primary={tableID=31, indexID=1, indexValues={412593116899442694, 1089315, }} [try again later]"] [txn=“Txn{state=invalid}”] [2019/11/19 15:54:18.479 +08:00] [WARN] [txn.go:69] [RunInNewTxn] [“retry txn”=412653992883519495] [“original txn”=412653992883519495] [error="[kv:9007]Write conflict, txnStartTS=412653992883519495, conflictStartTS=412653992883519494, conflictCommitTS=412653992883519497, key=[]byte{0x6d, 0x44, 0x42, 0x3a, 0x31, 0x32, 0x38, 0x37, 0x34, 0xff, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xf7, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x48} primary=[]byte{0x6d, 0x44, 0x42, 0x3a, 0x31, 0x32, 0x38, 0x37, 0x34, 0xff, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xf7, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x48} [try again later]"] [2019/11/20 15:47:22.506 +08:00] [WARN] [txn.go:69] [RunInNewTxn] [“retry txn”=412676533099429905] [“original txn”=412676533099429905] [error="[kv:9007]Write conflict, txnStartTS=412676533099429905, conflictStartTS=412676533099429899, conflictCommitTS=412676533099429908, key=[]byte{0x6d, 0x44, 0x42, 0x3a, 0x37, 0x36, 0x32, 0x33, 0x0, 0xfe, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x48} primary=[]byte{0x6d, 0x44, 0x42, 0x3a, 0x37, 0x36, 0x32, 0x33, 0x0, 0xfe, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x48} [try again later]"]
从日期上看都是历史的冲突日志。
收到,我再查一下,稍等。
辛苦了,先吃午饭吧![]()
你好,能提供下 tidb.log 10:20-10:30 tikv.log 10:20-10:clock1030 都拿一个节点的
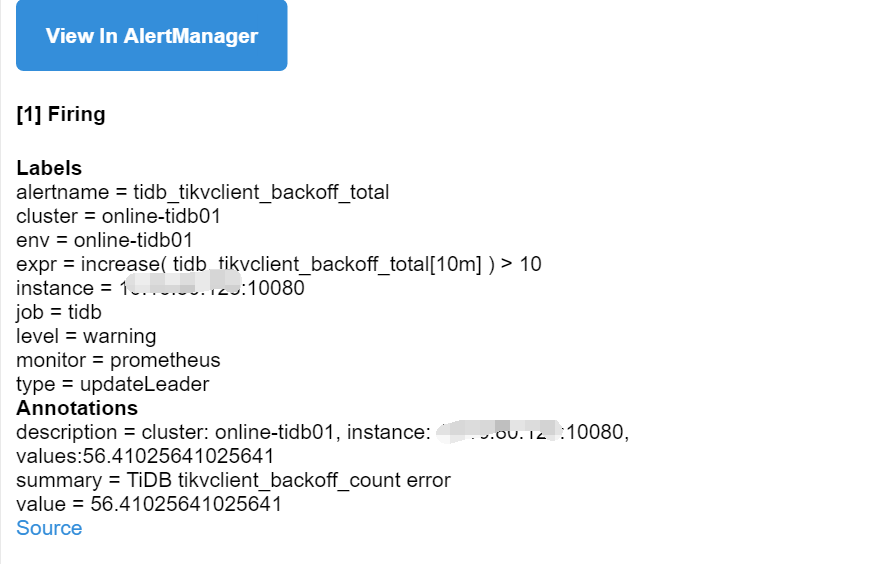
麻烦再把完整告警信息发出来,
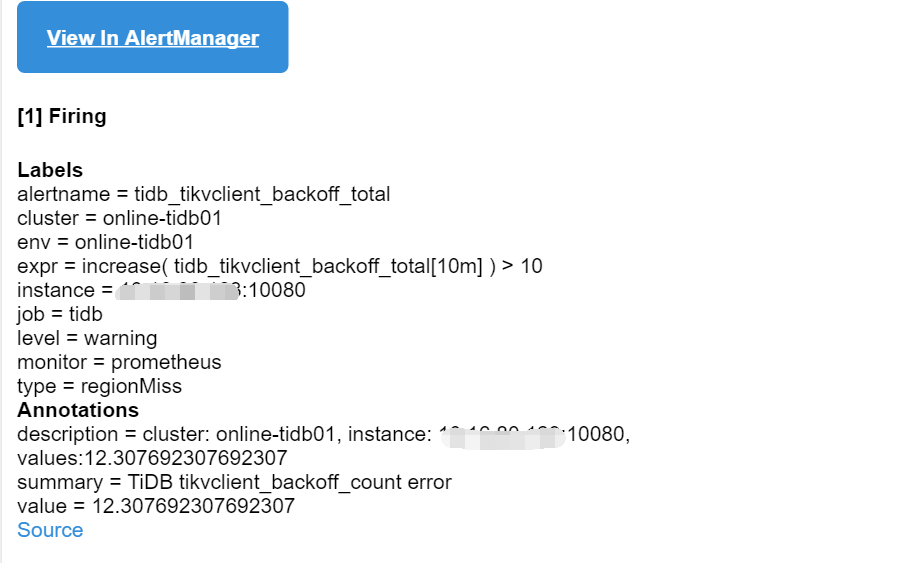
View In AlertManager
[1] Firing
Labels
alertname = tidb_tikvclient_backoff_total
cluster = online-tidb01
env = online-tidb01
expr = increase( tidb_tikvclient_backoff_total[10m] ) > 10
instance = 10.16.90.123:10080
job = tidb
level = warning
monitor = prometheus
type = tikvLockFast
Annotations
description = cluster: online-tidb01, instance: 10.16.90.123:10080, values:916.9230769230768
summary = TiDB tikvclient_backoff_count error
value = 916.9230769230768
type = tikvLockFast ,代表读写事务冲突,当前正在读的表有其他操作正在修改,等待 resolve lock 的时间很短。 type = updateLeader,代表 region 的 leader 可能发生了切换,导致该请求需要重试。
可以排查下,现在 TiDB 上频繁查询的表,在上游中是否有频繁修改。
tidb集群中查询的语句很少,频繁查询的情况基本不会发生。
那查询如果很大的话,也可能出现这种情况。
如果对现有业务没造成影响,那 type=tikvLockFast 这个类型的告警也可以忽略。
好的。 type=updateleader,type=regionmiss 这类告警信息怎么处理呢?
这种一般是 region 发生了分裂或者合并,其实也不用太关注。当 region 发生分裂时,请求发送到对应的 tikv 上,找不到这个 region 后,它会从 pd 重新获取元数据,马上重试这个请求。
现在这个频繁的告警,个人感觉是我将tidb从v3.0.3升级到v3.0.5后才开始出现的。
是不是在v3.0.5中监控告警有了部分调整?
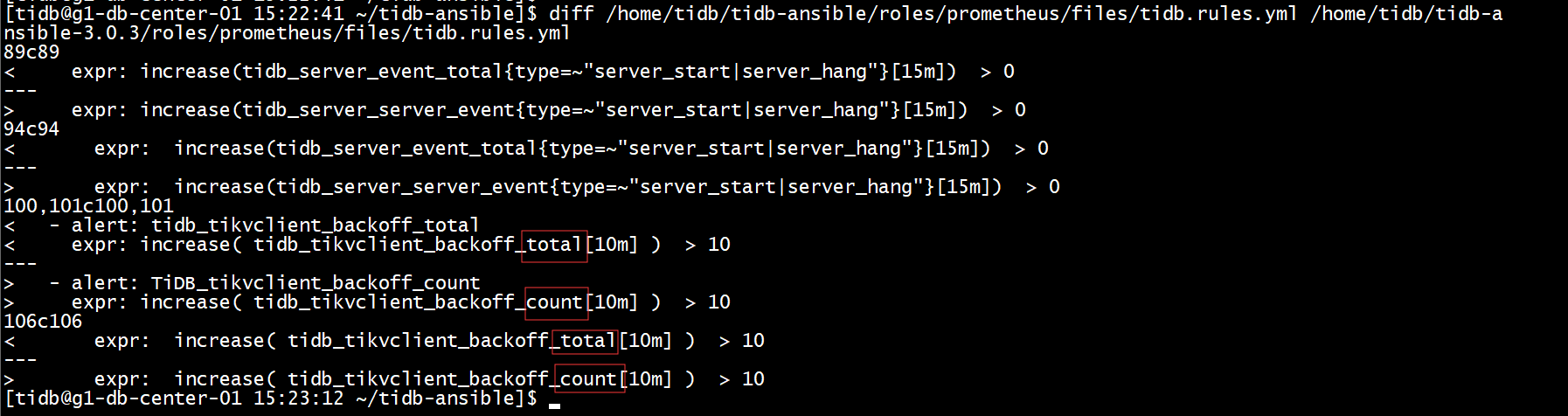
业务上没调整吗。 可以对比下两个 ansible 中 tidb-ansible/roles/prometheus/files/tidb.rules.yml 中 tidb_tikvclient_backoff_total 这条告警的计算方式是不是不同。
在业务上,上游MySQL增加了2张写入量较大的表
应该还是与上游两张表的关系比较大。