为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.2
- 【问题描述】:TIDB 性能问题
生产环境使用TiDB已经5个月了, 之前使用的版本是2.1.6,现已升级到3.0.2,在此期间出现了一些问题,升级到3.0.2后,tikv 的cpu 使用率增加了80%,以前在微信群提过此问题, 没有解决,现在出现了一些严重的性能问题, tidb集群在删除数据,跟删除表时 变得很慢,查询性能也慢了,目前我查不到性能瓶颈在哪里,请协助我解决一下此问题, 需要提供哪些数据分析问题?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
不懂就问
(zhouyueyue)
2
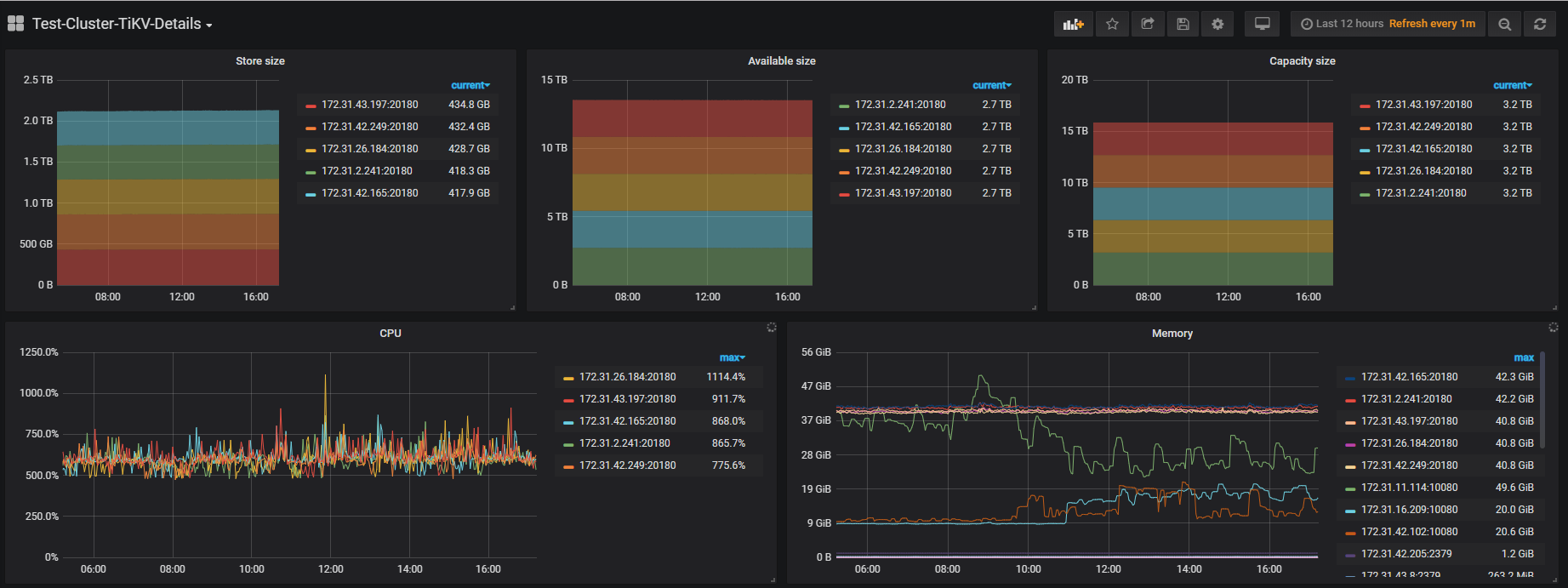
麻烦上传一份 TiDB & TiKV 的监控,最好能包括升级前后的时间区间,方便排查问题。
如果信息不够完整,请给我一个邮箱地址邀请您注册 grafana 账号
不懂就问
(zhouyueyue)
5
不懂就问
(zhouyueyue)
8
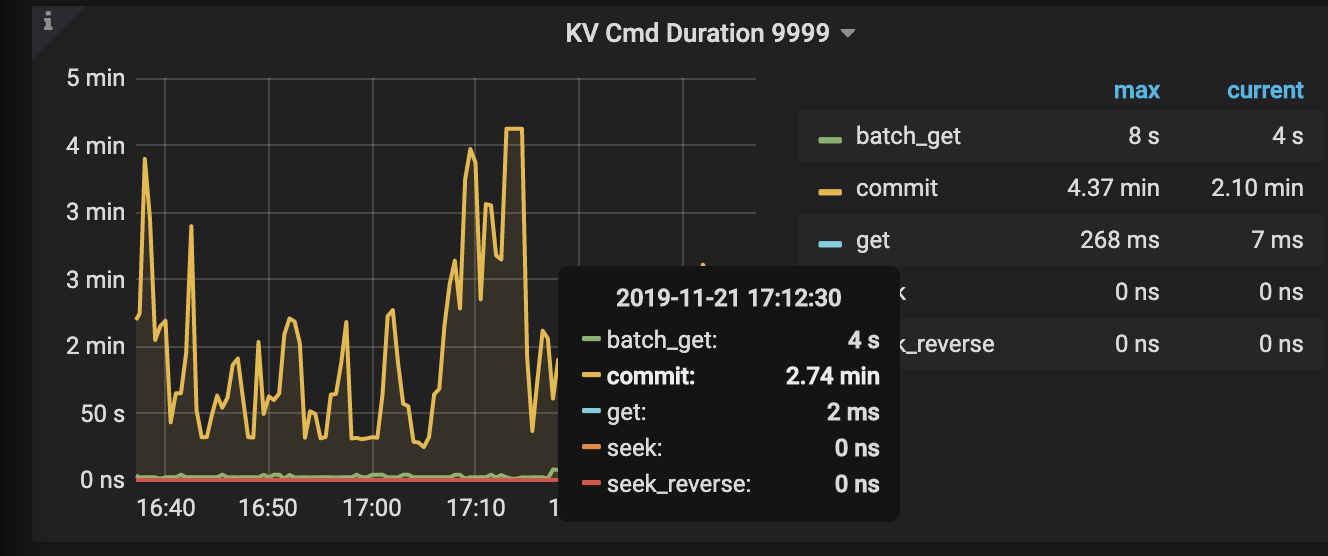
看着是 raftstore CPU 已经到瓶颈了,有很多的事务重试,commit 很慢。发下 TiKV 的配置文件。
ansible 中控机上的tikv tikv.yml 配置文件是默认的
tikv机器上的配置也是默认的
cat tikv.toml
TiKV config template
Human-readable big numbers:
File size(based on byte): KB, MB, GB, TB, PB
e.g.: 1_048_576 = “1MB”
Time(based on ms): ms, s, m, h
e.g.: 78_000 = “1.3m”
[readpool.storage]
[readpool.coprocessor]
[server]
labels = { }
[storage]
[storage.block-cache]
[pd]
This section will be overwritten by command line parameters
[metric]
[raftstore]
raftdb-path = “”
sync-log = true
[coprocessor]
[rocksdb]
wal-dir = “”
[rocksdb.defaultcf]
[rocksdb.defaultcf.titan]
[rocksdb.lockcf]
[rocksdb.titan]
[rocksdb.writecf]
[raftdb]
[raftdb.defaultcf]
[security]
ca-path = “”
cert-path = “”
key-path = “”
[import]
#cat blackbox.yml
modules:
http_2xx:
prober: http
http:
method: GET
http_post_2xx:
prober: http
http:
method: POST
tcp_connect:
prober: tcp
pop3s_banner:
prober: tcp
tcp:
query_response:
- expect: “^+OK”
tls: true
tls_config:
insecure_skip_verify: false
ssh_banner:
prober: tcp
tcp:
query_response:
- expect: “^SSH-2.0-”
irc_banner:
prober: tcp
tcp:
query_response:
- send: “NICK prober”
- send: “USER prober prober prober :prober”
- expect: “PING :([^ ]+)”
send: “PONG ${1}”
- expect: “^:[^ ]+ 001”
icmp:
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: “ip4”
不懂就问
(zhouyueyue)
10
可以先调整下 raftstore,在中控机的 TiKV 配置文件里,修改 # store-pool-size: 3, ansible-playbook rolling_update.yml --tags=tikv 。另外看下 tidb.log 里面应该有大量的事务重试,从业务角度调整下。
好的,我修改一下配置试试, 业务端调整一下, 接下来我考虑升级到3.0.5 , 等我修改后继续观察一下吧。
不懂就问
(zhouyueyue)
12
看集群响应特别慢,先调整一个这个参数再看下,另外建议根据业务特点以及机器配置最好能修改一些配置。
system
(system)
关闭
13
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。