KS贺大伟
(Ks贺大伟)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】场景+问题概述
TiKV扩容了一些节点之后,手动调整store limit 从15->100,起初看到大量的rebalance,运行两天之后,发现集群的负载均衡调度非常慢了,一周过去了,新扩容的节点的存在大量空闲,反观之前的节点,磁盘占用仍然处在接近capacity size的水位线上。我确认了当前的store limit,是我之前修改后的100,不知道如何加速这种均衡过程
【背景】做过哪些操作
【现象】业务和数据库现象
【业务影响】
【TiDB 版本】
V4.0.14
【附件】
-
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
2 个赞
xfworld
(魔幻之翼)
2
可以手动调节参数,来对均衡操作进行提速,但是这块有点复杂,建议你参考下面的文档进行操作
首先要排查Region 是否均衡,然后通过调度均衡Region 后,在考虑其他的问题
3 个赞
KS贺大伟
(Ks贺大伟)
3
根据这个文档,结合监控,尝试了各种参数,几乎没有任何效果,这个集群有一个offline的tikv节点。
KS贺大伟
(Ks贺大伟)
5
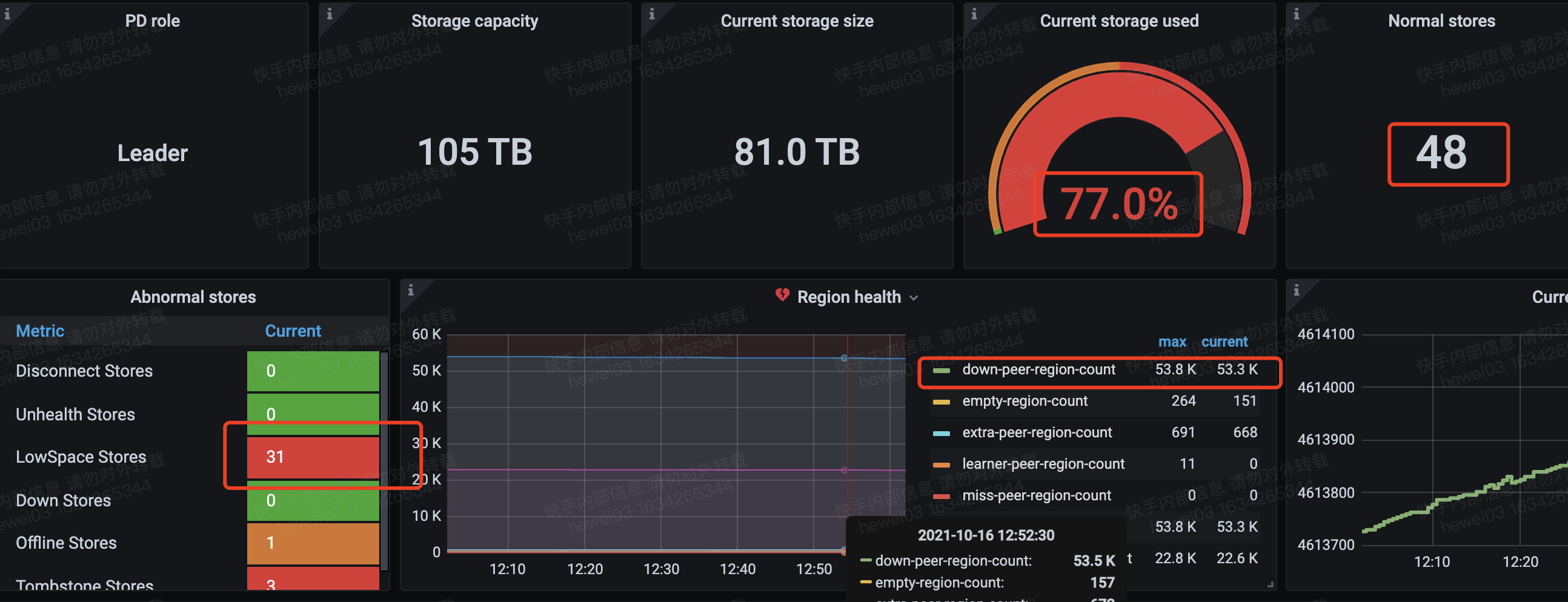
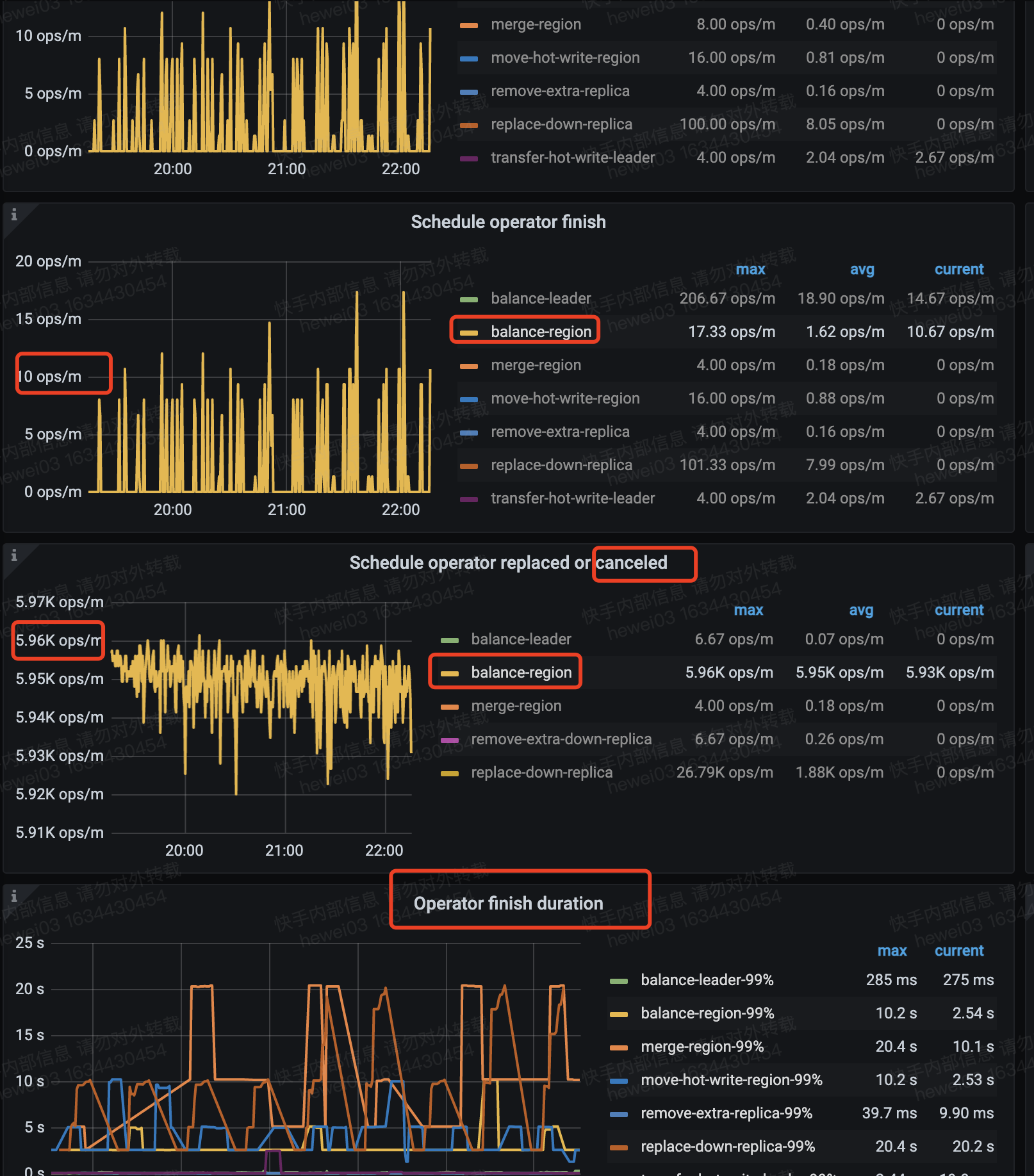
48个tikv节点,其中31个节点磁盘空间不足了,另有一个offline的节点,磁盘已经彻底满了,新扩容了10台机器,起初还进行负载均衡,我在扩容之后,条了store limit all 100,起初还是开始负载均衡,后来就没有动静了,按照你提供的文档,我也尝试调试各种调度相关的参数,发现没有效果,大量的region调度任务被cancel了,pd的日志中也是一直打印cancel 调度任务,除此之外没有其他的告警信息。另外offline的节点反应到监控上就是down peer的数量下降的也很慢。
KS贺大伟
(Ks贺大伟)
6
store score是差异很大的,tikv的CPU占用我也看了,都是300%左右,我们的机器都是40+ CPU核心,根本没有达到负载很高。
xfworld
(魔幻之翼)
8
这么多实例的 tikv 上面的 regions 的数量是否均衡?
store score 的差异也会影响到 regions 的均衡策略,但是可以手动调整的
你参考 【SOP19】 排查问题,结果是完全无效么? 那可以描述一下步骤么?
另外,最好把你现在集群的环境做一个整体描述,主要的问题是均衡,还是热点?
KS贺大伟
(Ks贺大伟)
9
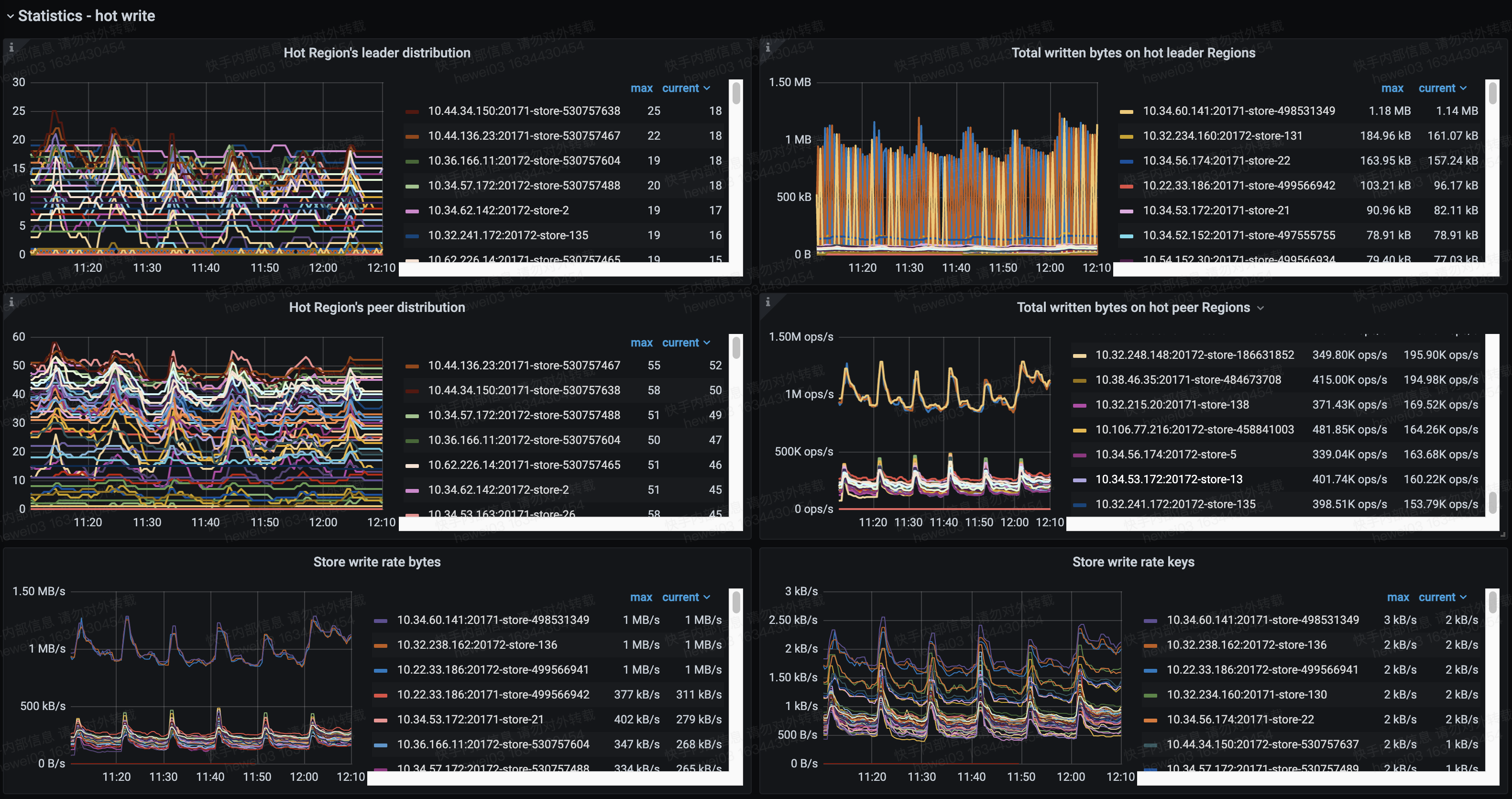
热点分片监控如上图所示
store上region数量也不均衡,我今天把offline的store主动标记为墓碑,期望加速故障恢复,但是看起来也没有什么效果
我的另外一个规模差不多的集群,最近也扩容了,它就均衡的很快,我怀疑offline store的处理对PD的集群负载均衡有很大的影响。
xfworld
(魔幻之翼)
10
offline store 本身对 PD 的影响就很大,所有的Regions 的调度都是通过PD 来执行的
如果有offline store,一定要及时处理,否则 PD 会平移副本信息到 其他的节点,来满足集群对于副本数量的要求。
xfworld
(魔幻之翼)
12
及时下线节点,或者及时的 让节点上线,让集群所有的节点保持UP 状态
KS贺大伟
(Ks贺大伟)
13
也就是我主动墓碑这个节点也是可以的是吧,这个节点的磁盘满了,没办法让他直接up了,只能先墓碑他。
KS贺大伟
(Ks贺大伟)
14
我理解, 如果集群某一个节点发生了故障,那么第一要义是尽快进行故障恢复,尤其是配置了三个副本的情况下,如果恢复的时间太长,有可能会遇到另外的节点也发生故障,这种情况下,raft的多数派会被破坏,无法自动恢复了。
31个store 80T的数据。。 我震撼了。。。
看看 Duration P999,学习一下。
KS贺大伟
(Ks贺大伟)
16
哎,其实是从成本考虑,3TB的SSD磁盘,一台物理机两块磁盘,部署两个tiKV实例,单磁盘用1TB,成本太高了,只能用到更多才划算,比如2TB甚至更多。TP999还好,主要是因为平时流量不大。
我的经验是 如果单盘容量太高,单实例的处理性能会有问题,1T左右比较合适。
data目录有个磁盘缓存文件,space_placeholder_file 用来紧急释放2G的空间。
KS贺大伟
(Ks贺大伟)
19
是的,1TB以下是比较好的,但是历史原因,并没有tidb定制的机型,没有那么多1TB左右的磁盘,也没有LVM来重新划分磁盘,成本太高,没办法
space_placeholder_file 这个是有的,我刚接手这部分,原来的同事不了解这个,遇到磁盘满了没办法,只能offline节点了。
KS贺大伟
(Ks贺大伟)
20
昨天晚上有一个节点down,从监控上,PD对于down的节点,故障恢复特别快,一直进行region调度,等到我重新拉起来这个节点之后,region调度又停滞不前了,我有一个offline的节点,我专门标记为墓碑,我的问题是我有什么办法可以加速这个墓碑节点导致的大量的down peer,已经一周了。是不是我stop这个节点,PD就按照down的流程梳理了,可以加速调度迁移??