getui
2021 年10 月 15 日 01:20
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
监控:
【背景】 做过哪些操作
【现象】 业务和数据库现象
【TiDB 版本】
【应用软件及版本】
【附件】 相关日志及配置信息
TiUP Cluster Display 信息
TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/ )
TiDB-Overview Grafana监控
TiDB Grafana 监控
TiKV Grafana 监控
PD Grafana 监控
对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
getui
2021 年10 月 15 日 01:33
4
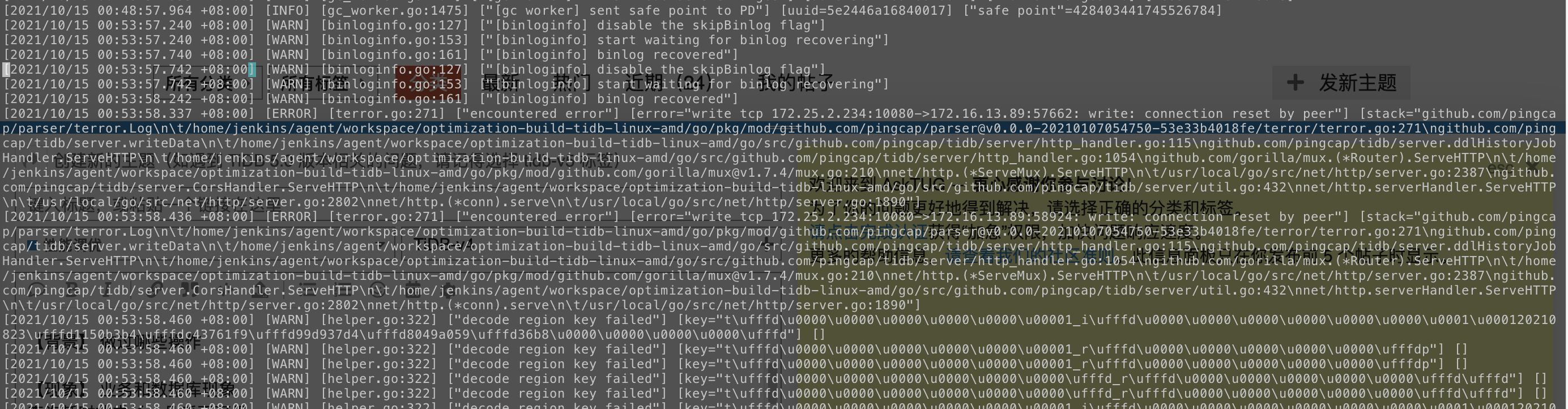
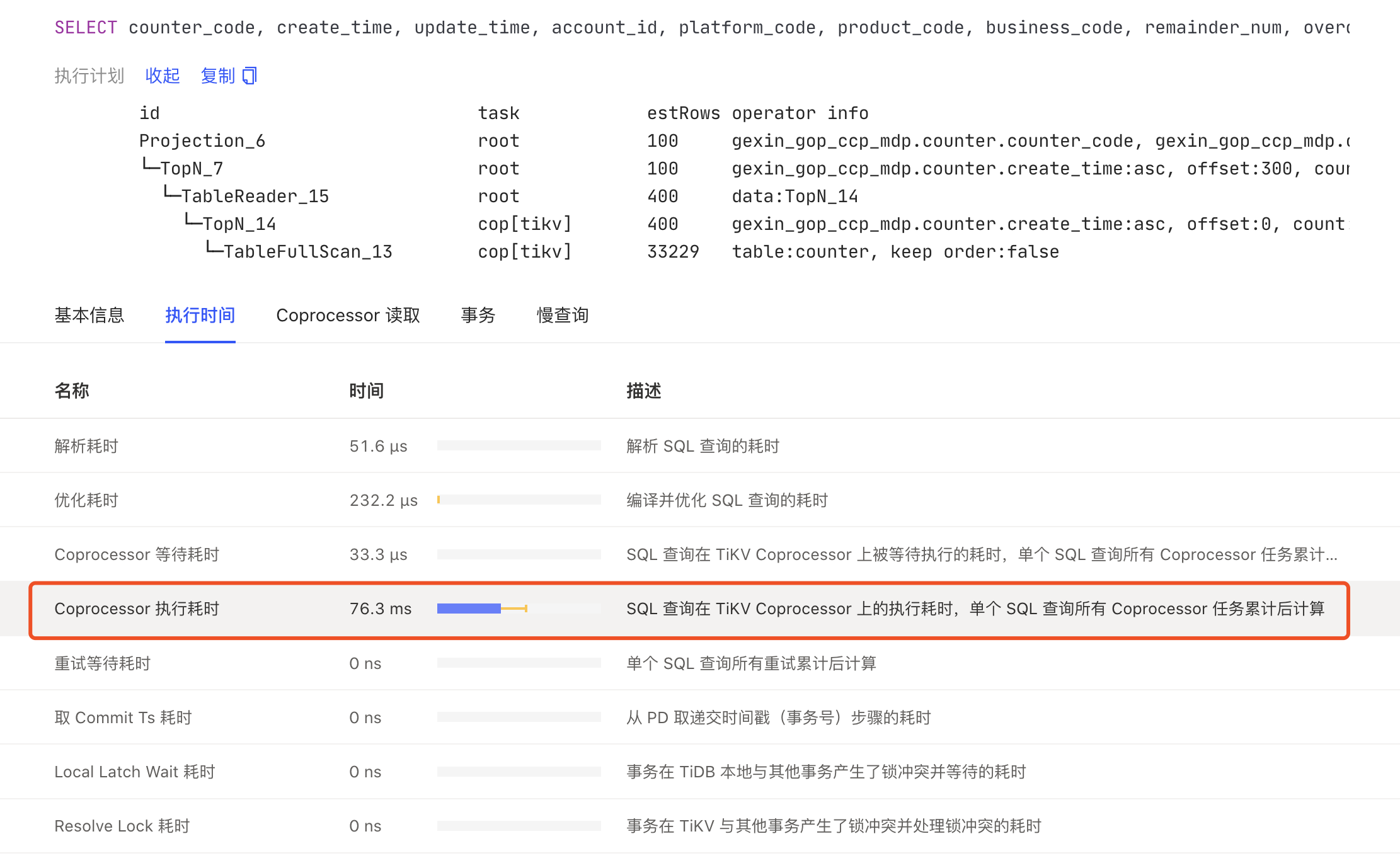
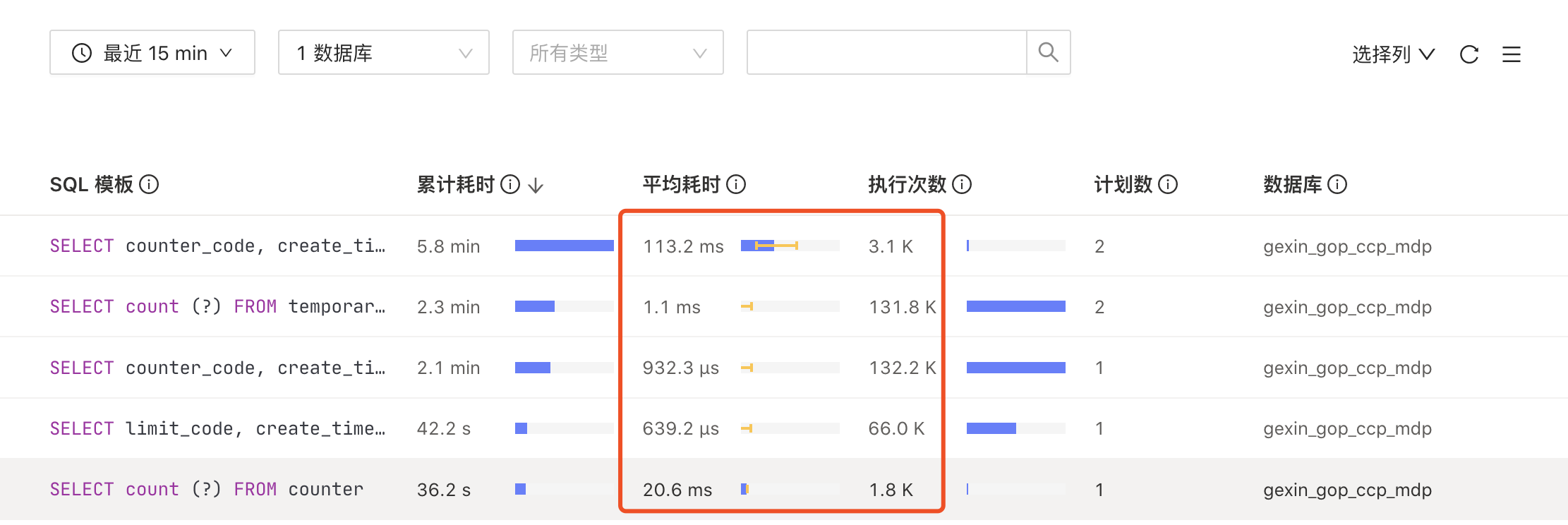
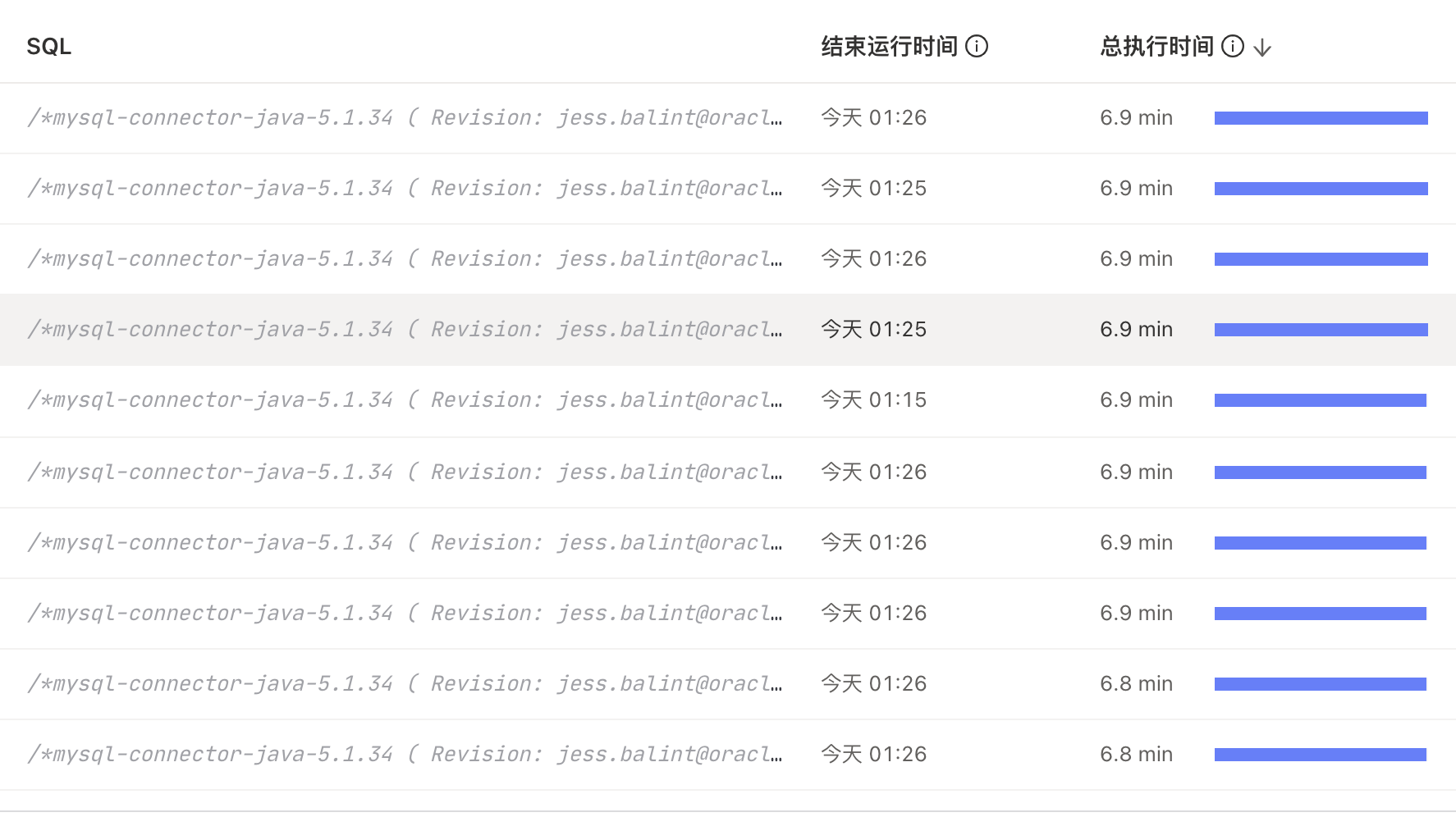
嗯,有个慢查询sql一直在执行的,为啥突然就飙升了,写影响了?
h5n1
2021 年10 月 15 日 01:35
5
可能返回tidb server的数据量太大,看下执行计划
这道题我不会
2021 年10 月 15 日 02:11
7
1.重点排查下问题时间点的慢 SQL 情况,查询下哪些 SQL 开销最大,可以使用下面这条 SQL 先核实下扫描 region 最多的几个 SQL ,然后看下 SQL 对应的执行计划是否存在全表扫描等情况:
select query_time, query, digest
from information_schema.cluster_slow_query
where is_internal = false
AND time >= '2021-10-15 xx:xx:00'
AND time < '2021-10-15 xx:xx:00'
order by Process_keys desc
limit 5;
2.上面几个高频 SQL 需要让业务研发侧看下请求是否合理。
haizi
2021 年10 月 15 日 02:26
8
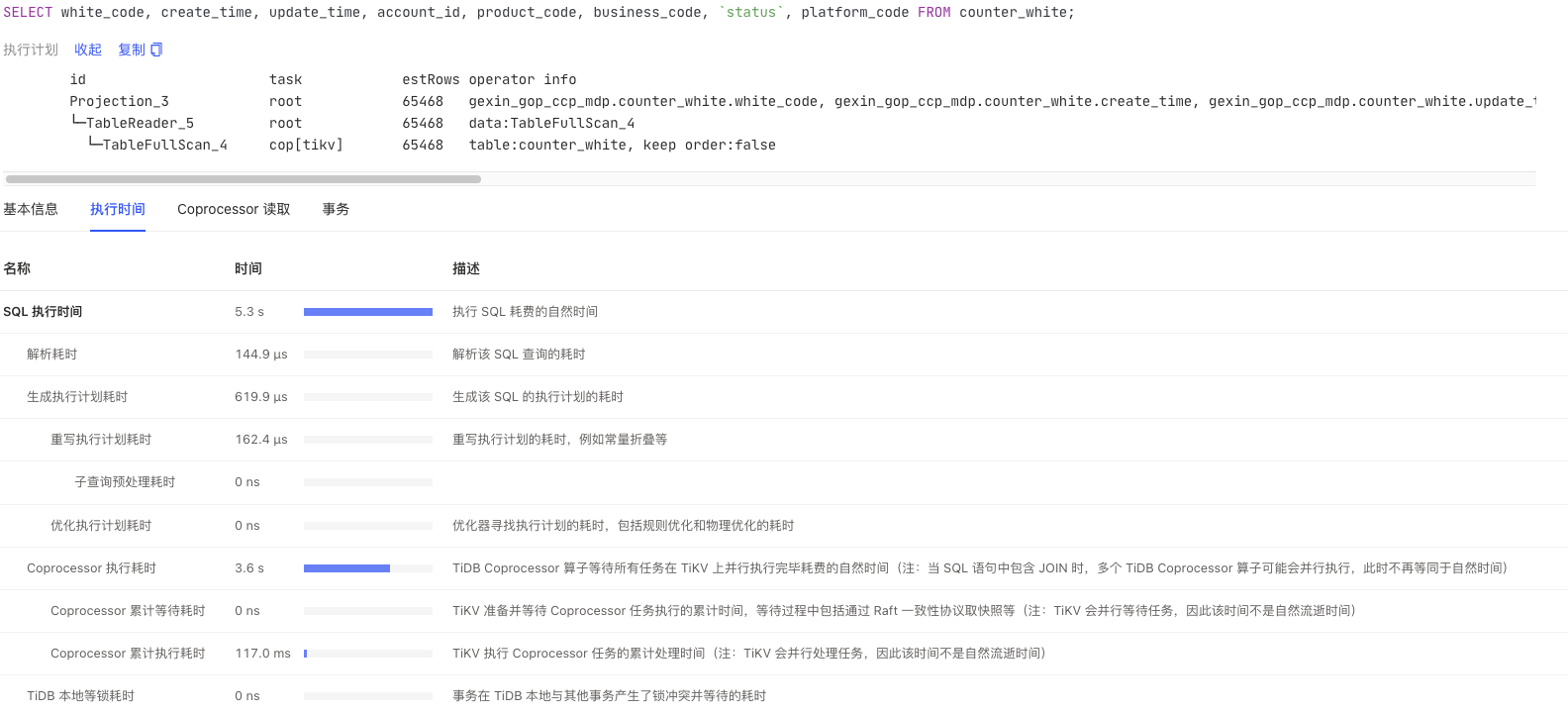
按照你给的这个查询条件,在这个异常的时间段内,是有一个全表扫描的语句,查的这个表有6w记录,正常执行的话,这个语句只需要0.3秒,之前一直在执行的。在异常的这个时间段内,执行需要5-7秒。
这道题我不会
2021 年10 月 15 日 02:38
10
1.这条 SQL 没有过滤条件直接全表扫描,如果表数据量突然变大或者查询频率突然升高,都会给系统带来很大的影响,建议添加一些过滤条件;
haizi
2021 年10 月 15 日 02:41
11
当时还有大量的这个语句在执行,每个执行完都需要6 7分钟。这个是什么原因啊?
这道题我不会
2021 年10 月 15 日 02:46
12
这些 SQL 应该是受害者,源头是哪些业务 TOPSQL 导致整个集群的负载上升,原先正常执行的 SQL 由于不能及时获取到资源,执行消耗时间也会变长,从日志中看这些 SQL 也就变成了慢 SQL
这道题我不会
2021 年10 月 15 日 02:57
14
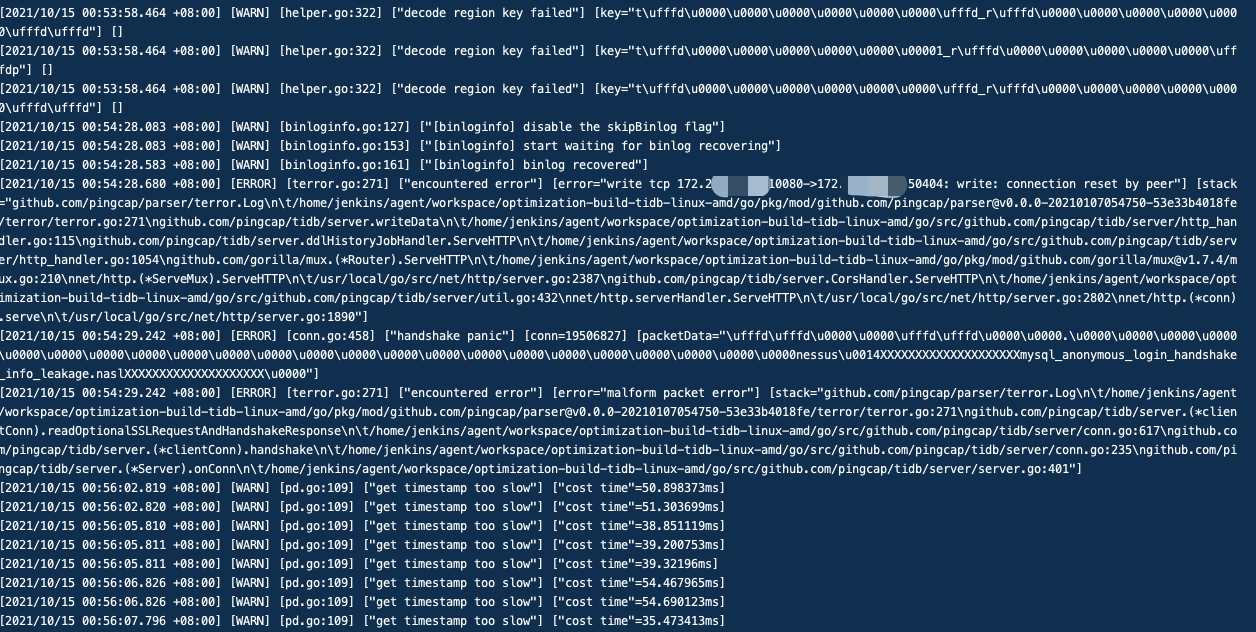
这个时间段该 tidb-server 负载应该很高了吧,相关请求打过来时 tidb-server 无法及时处理,发生了 panic
林先森cC
2021 年10 月 15 日 03:10
15
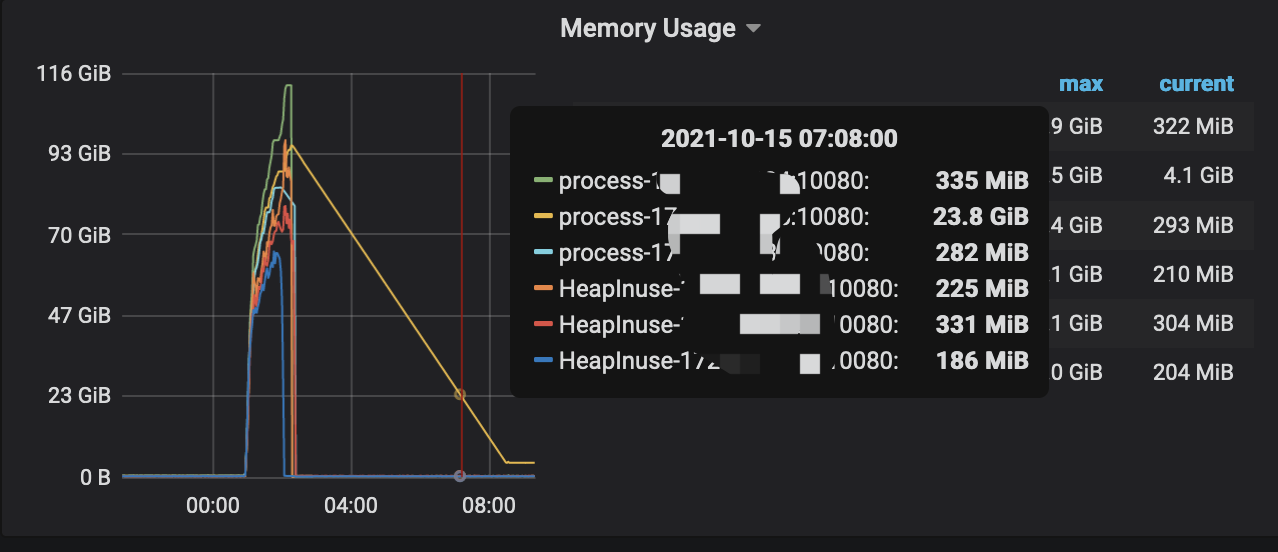
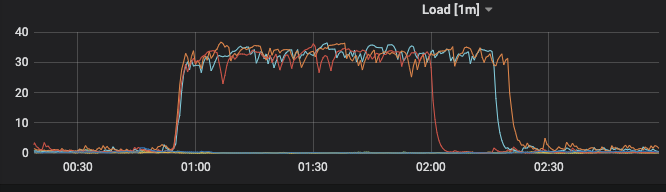
看监控是PD的三台节点机器 压力很大,差不多从00:54分开始上涨
有报这个错
qizheng
2021 年10 月 15 日 03:16
16
查询 information_schema.cluster_slow_query 表还可以按照 Mem_max 内存使用量做一下排序
haizi
2021 年10 月 15 日 06:29
17
还有一个疑问,就是从 information_schema.cluster_slow_query查出来的每个慢sql,最大的也就占用6MB的内存,为啥这里突然一下子内存飙升那么高 ?瞬时把内存占完了?
system
2022 年10 月 31 日 19:25
18
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。