为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
自己搭建的集群。 3个tidb,3个pd,3个tispark,3个tikv分别在三个机器上。
【概述】 场景 + 问题概述
在spark中,写入数据库出错
【背景】 做过哪些操作
按照文档(https://docs.pingcap.com/zh/tidb/stable/get-started-with-tispark)导入 tispark-sample-data到tidb数据库。然后读出数据后,创建数据表,然后将将读出的数据写入后,出错:
”WARN RowIDAllocator: error during allocating row id“
其中,数据库表创建的脚本:
CREATE TABLE target_customer (
C_CUSTKEY int(11) NOT NULL,
C_NAME varchar(25) NOT NULL,
C_ADDRESS varchar(40) NOT NULL,
C_NATIONKEY int(11) NOT NULL,
C_PHONE char(15) NOT NULL,
C_ACCTBAL decimal(15,2) NOT NULL,
C_MKTSEGMENT char(10) NOT NULL,
C_COMMENT varchar(117) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
写入数据库的java代码是:
SparkConf conf = new SparkConf()
.setMaster(“local[*]”)
.setAppName(“TiSparkJavaExample”)
.set(“spark.sql.extensions”, “org.apache.spark.sql.TiExtensions”)
.set(“spark.tispark.pd.addresses”, “127.0.0.1:2379”);
SparkSession spark = SparkSession
.builder()
.config(conf)
.getOrCreate();
Dataset<Row> customers = spark.sql("select * from customer");
customers.write().format("tidb")
.option("tidb.addr", "127.0.0.1")
.option("tidb.port", "4000")
.option("tidb.user", "root")
.option("tidb.password", "")
.option("database", "tpch_001")
.option("table", "target_customer")
.mode("append")
.save();
spark.stop();
【现象】 业务和数据库现象
写入出错
【问题】 当前遇到的问题
写入出错, 错误日志是:
21/10/11 09:35:49 WARN RowIDAllocator: error during allocating row id
java.lang.RuntimeException: java.io.EOFException
at com.pingcap.tikv.codec.CodecDataInput.readLong(CodecDataInput.java:158)
at com.pingcap.tikv.allocator.RowIDAllocator.updateMeta(RowIDAllocator.java:159)
at com.pingcap.tikv.allocator.RowIDAllocator.updateHash(RowIDAllocator.java:196)
at com.pingcap.tikv.allocator.RowIDAllocator.udpateAllocateId(RowIDAllocator.java:230)
at com.pingcap.tikv.allocator.RowIDAllocator.initSigned(RowIDAllocator.java:273)
at com.pingcap.tikv.allocator.RowIDAllocator.doCreate(RowIDAllocator.java:109)
at com.pingcap.tikv.allocator.RowIDAllocator.create(RowIDAllocator.java:90)
at com.pingcap.tispark.write.TiBatchWriteTable.getRowIDAllocator(TiBatchWriteTable.scala:395)
at com.pingcap.tispark.write.TiBatchWriteTable.preCalculate(TiBatchWriteTable.scala:309)
at com.pingcap.tispark.write.TiBatchWrite$$anonfun$1.apply(TiBatchWrite.scala:203)
at com.pingcap.tispark.write.TiBatchWrite$$anonfun$1.apply(TiBatchWrite.scala:203)
at scala.collection.immutable.List.map(List.scala:284)
at com.pingcap.tispark.write.TiBatchWrite.doWrite(TiBatchWrite.scala:203)
at com.pingcap.tispark.write.TiBatchWrite.com$pingcap$tispark$write$TiBatchWrite$$write(TiBatchWrite.scala:88)
at com.pingcap.tispark.write.TiBatchWrite$.write(TiBatchWrite.scala:45)
at com.pingcap.tispark.write.TiDBWriter$.write(TiDBWriter.scala:40)
at com.pingcap.tispark.TiDBDataSource.createRelation(TiDBDataSource.scala:57)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at com.zhiyun.sparkjob.FirstSpark.main(FirstSpark.java:48)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.io.EOFException
at java.io.DataInputStream.readFully(DataInputStream.java:197)
at java.io.DataInputStream.readLong(DataInputStream.java:416)
at com.pingcap.tikv.codec.CodecDataInput.readLong(CodecDataInput.java:156)
… 49 more
21/10/11 09:35:52 INFO TwoPhaseCommitter: prewrite primary key * successfully
【业务影响】
不能写入数据库
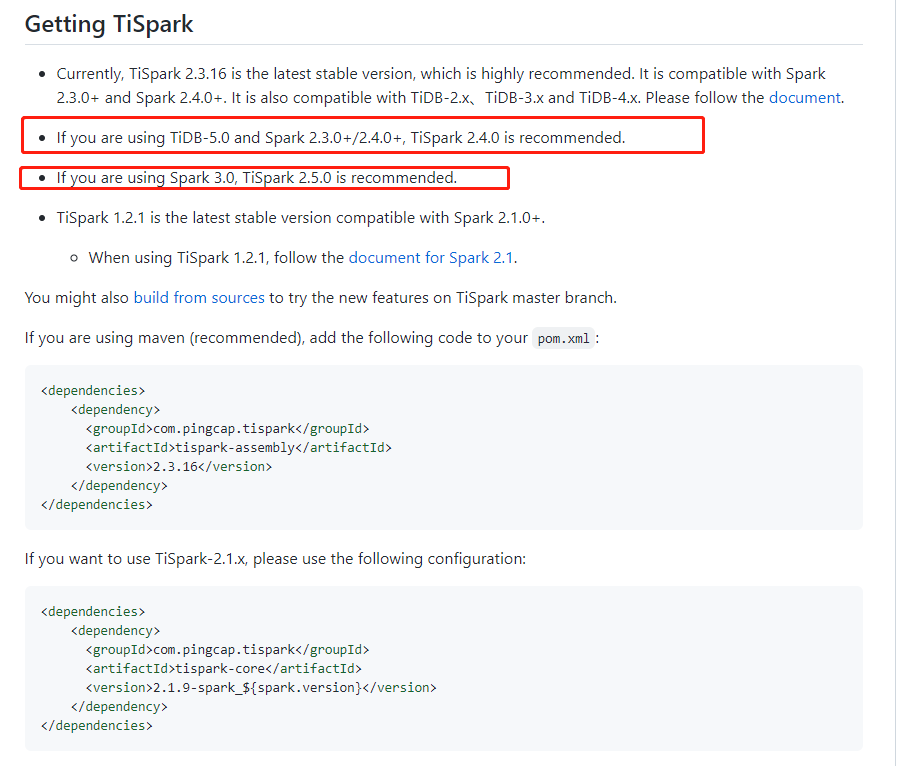
【 TiDB 版本】
v5.2.1
【附件】 相关日志及监控(https://metricstool.pingcap.com/)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。