zodiac207
(zodiac207)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:tidb3.0
- 【问题描述】: 按照 TiSpark 快速入门指南 部署tispark
通过 ansible-playbook start_spark.yml 后开启了spark服务后,在spark的监控页面可以看到worker已经起来。
然后起动spark-shell 测试,当我执行
语句后,一直报以下错误
1.bmp (842.7 KB)
这是spark监控的信息
确定机器 是有512M的内存空闲的。
而从worker 点进去看stderr 的信息如下:
stderr.txt (4.8 KB)
1 个赞
zodiac207
(zodiac207)
3
重新编辑了一下,原来刚拷了个sql,导致一部分的内容被当作代码显示了。执行的是这个SQL
spark.sql("select count(*) from lineitem").show
不懂就问
(zhouyueyue)
6
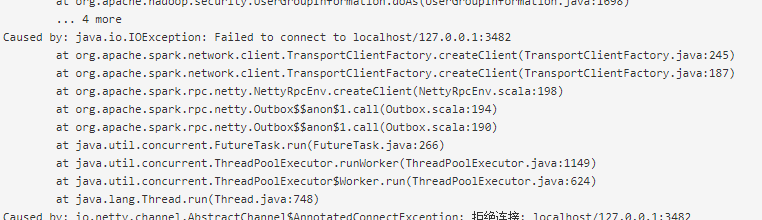
Caused by: java.io.IOException: Failed to connect to localhost/127.0.0.1:19488 看日志。
zodiac207
(zodiac207)
7
我也好疑惑 这个是哪里配置的。
这个端口每次都不一样的。现在又是3482了。他随机的。
不懂就问
(zhouyueyue)
8
麻烦把 master 和 worker 的日志都传上来,我们排查下。
zodiac207
(zodiac207)
9
log.rar (93.6 KB)
master与worker日志我打包了,在各自对应的文件夹上。
麻烦了。
不懂就问
(zhouyueyue)
10
排查下是不是启动 executor 的时候指定了 spark.driver.port=2656,所以 executor 一直在连 localhost:2656,但是 driver 实际上在另外一个机器上。
zodiac207
(zodiac207)
11
网络架构这样的,ABCD四台服务器
A :PD ,TIDB sparkmaster
BCD :titv sparkslaves
你的回复提醒了我,我之前一直都是在 sparkmaster 服务器开spark shell 来测试的,然后就一直报标题的错,然后今天我在sparkslaves 上执行就成功通过了。
按我理解 ,哪里起的spark shell ,driver就在哪台机器 ,而我在master上执行的时候,driver也在master 上,而worker 却一直连localhost ,所以一直没成功。
那么,是不是只能在slaves上执行 程序啊(spark 机制我也是现学的,不是很懂),还是有什么设置没设置好,导致worker 没有找到正确的driver 地址?
zodiac207
(zodiac207)
12
做了实验 ,在slaves 上执行spark-shell ,只是执行的shell 的机器 的worker 有用,其他机器 的worker 还是报 java.io.IOException: Failed to connect to localhost/127.0.0.1:28797 这个错。
birdstorm
(Birdstorm - PingCAP)
14
@zodiac207 您好
首先你现在是在 spark-shell 访问 Spark 集群模式,需要在 spark 的 spark-defaults.conf 配置里 添加 master 地址,或者在 spark-env.sh 中设置 SPARK_MASTER_HOST 及 SPARK_MASTER_PORT,或者 使用 spark-shell --master your_spark_master_url 访问你的集群。
另外,spark 要求 master 和 worker 之间都能双向访问,所以请检查网络连接是否正确,hostname 等能否正确解析,你可以使用 ping 等方式来查看。如果 worker 无法访问 master,那么就会出现类似 connection refused 的错误。
zodiac207
(zodiac207)
15
@birdstorm 谢谢你的回复,
你文中提到的,spark-defaults.conf spark-env.sh 这两个 文档我按官方文档检查 过,具体是如下
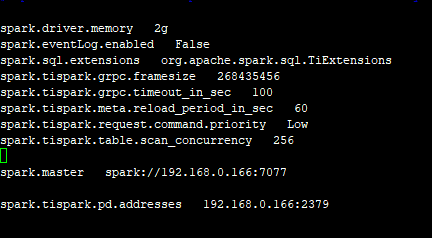

spark-env.sh文档 是没设置 SPARK_MASTER_PORT 我试一下
网络是肯定 通的。
谢谢。
birdstorm
(Birdstorm - PingCAP)
16
好的,从你的配置里看似乎没什么问题,如果方便的话可以提供一下 spark 集群启动的方式吗?另外,网络问题最好通过 telnet/nc 等方式确认端口也是开放的。
zodiac207
(zodiac207)
17
问题我找到了,因为spark 传给worker 的driver地址是通过机器名来传递的,而我的环境里所有机器名都是localhost,所以就一直报 java.io.IOException: Failed to connect to localhost/127.0.0.1:28797 ,这里的localhost 其实是driver机器的机器 名,这个localhost误导了我好久。现将各机器的机器名改一下,并配置一下各机器 的/etc/hosts文件 ,将集群的ip和机器名写正确,问题就解决了。
谢谢各位。
1 个赞
system
(system)
关闭
19
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。


{kind=link}