TIDB读放大在于LSM需要逐层查找。这里是不是可以这么理解:根据客户端的TSO:既先找level 0 层,因为level0 层sst 数据有重叠,所以level 0层需要多次进行查找:小于客户端TSO的最大TSO数据,如果找到,则返回客户端。如果没有找到则在下一层leve1 查找,由于level 1都是没有重叠的数据,因此操作定位要比level0 要快。
最新的数据都会在level0,然后level0 是内存级别的,只有寻找旧版本的数据才会去下层找

不都是,大部分是,参考下图
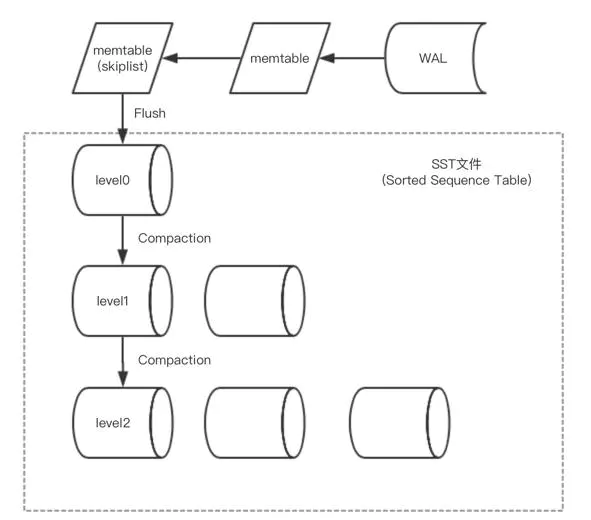
第一步先以日志的形式落地磁盘,记write ahead log, 落地成功后再写入memtable。这里记录wal的原因就是防止重启时内存中的数据丢失。所以在db重新打开时会先从wal恢复内存中的mentable. 可配置WAL保存在可靠的存储里。
所以level 0 就是已经落地成为sst 文件了。不是内存中数据了
当level0的sst文件数超过阈值或者总大小超过阈值,会触发compaction操作,将level0中的数据合并到level1中。同样level1的文件数超过阈值或者总大小超过阈值,也会触发compaction操作, 这时候随机选择一个sst合并到更高层的level中。这里有两点比较重要,1:level1 及其以上的level都整体有序。每个sst存储一个范围的数据互不交叉互不重合;2: level1 以上的 compaction操作可以多线程执行,前提是每个线程所操作的数据互不交叉。
那么这样数据就由内存流入到高层的level。我们理想状态下,所有的数据都存在非level0的一层level上。这样可以保证最高效的查询速度。
首先RocksDB中的每一条记录(KeyValue)都有一个LogSequenceNumber,从最初的0开始,每次写入加1。lsn在memtable中单调递增。之前提到的snapshot即就是基于lsn实现,每次以只读模式打开时,记录一个lsn, 大于该lsn的key不可见。
首先读操作先访问memtable。跳表的时间复杂度可达到logn, 如果不存在会访问level0, 而level0整体不是有序的, 所以会按创建时间由新到老依次访问每一个sst文件。所以时间复杂度为m*logn。如果仍不存在,则继续访问level1,由于level1及其以上的level都整体有序,所以只需要访问一个sst文件即可。 直到查找到最高层或者找到这个key。所以读操作可能会被放大好多倍。
rocksdb做了几点优化,一点是为每个SST提供一个可配置的bloomfilter. 每个level的配置不一样。这样可以快速的确认一个key在不在某个SST中,这点以牺牲磁盘空间来换取时间。另一点是提供可配置的cache, 用于保存访问过的key在内存中, 这里有一点就是它缓存的是某个key在SST文件中的整个block里的记录。
这个看怎么去理解了,能解答你的疑问就好! ![]()
1 个赞
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。