
版本
出现的问题
可复现操作
脚本
日志
尽可能详细描述一下你遇到的问题~以便于问题更快速的定位~
1 个赞
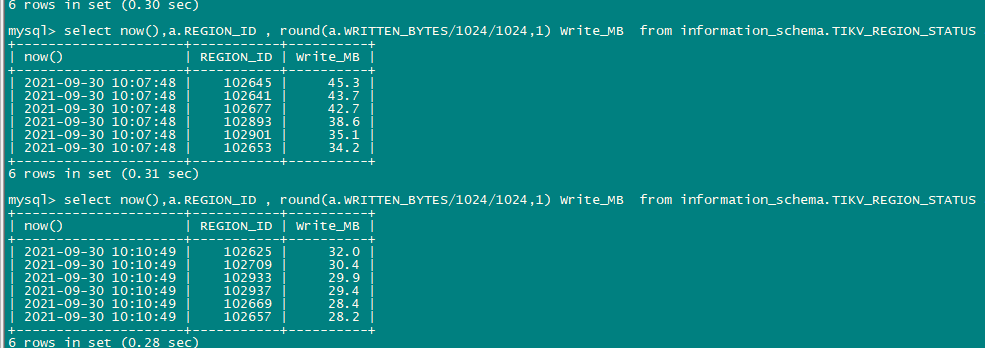
图上,不是有单位么
1 个赞
这么多bytes是每秒的量还是什么
1 个赞
对的。
1 个赞
我现在用sysbench做select random points测试出现热点问题17节点的unified read pool CPU比其他高很多,但是通过TIKV_REGION_STATUS TIKV_STORE_STATUS TIKV_REGION_PEERS 关联查询leader的热点读region 发下store 4:144.18的 region 77029读流量反而比较高
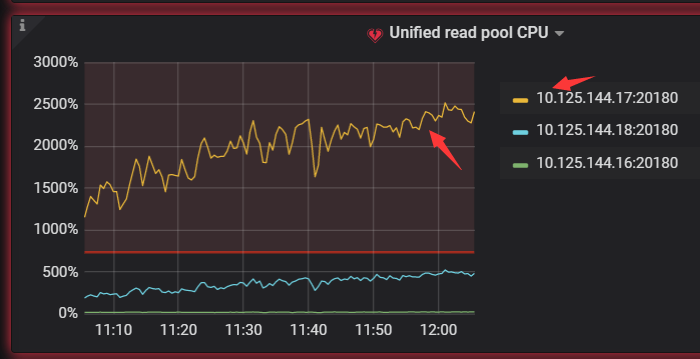
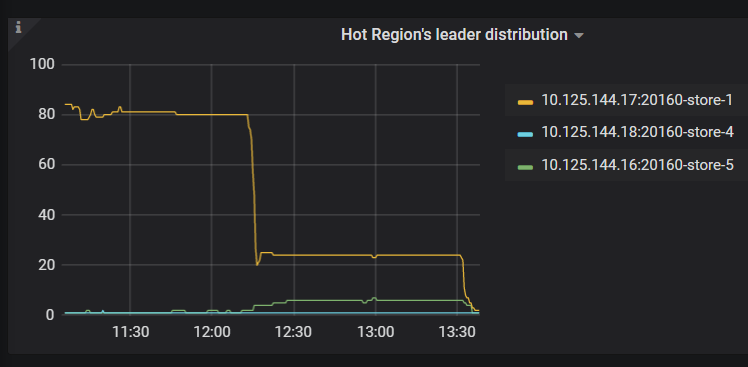
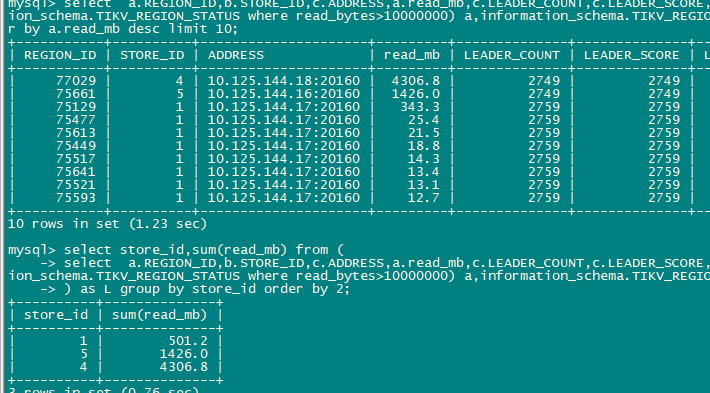

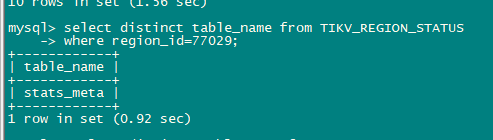
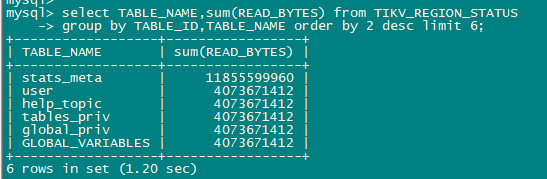

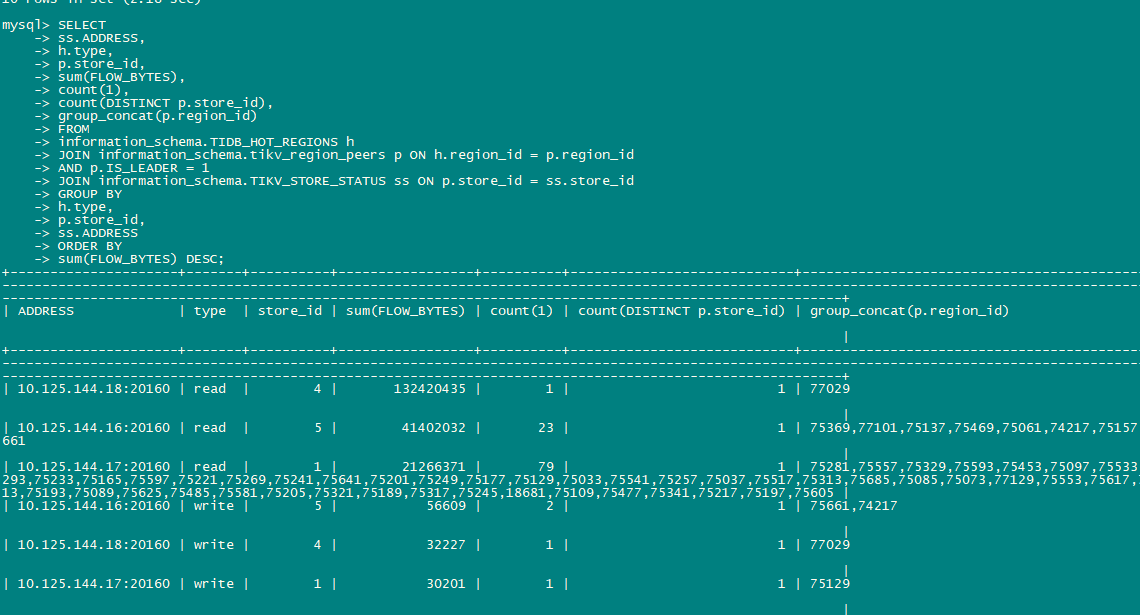
感觉有2个问题1. 通过系统表查看的top read region并不是测试的表而是stats_meta 2. leader/region在tikv节点均衡后 ,PD不能再识别热点并进行调度。
在后续的测试中,通过调整多次leader weight 利用率能趋于均衡,但当调整一个store的leder weight 后leader的数量进行了均衡,但并没有按照热点或流量分散到所有节点
» store weight 5 0.5 1
Success!
» store weight 5 0.3 1
Success!
» store weight 4 1.3 1
Success!
» store weight 5 0.2 1
Success!
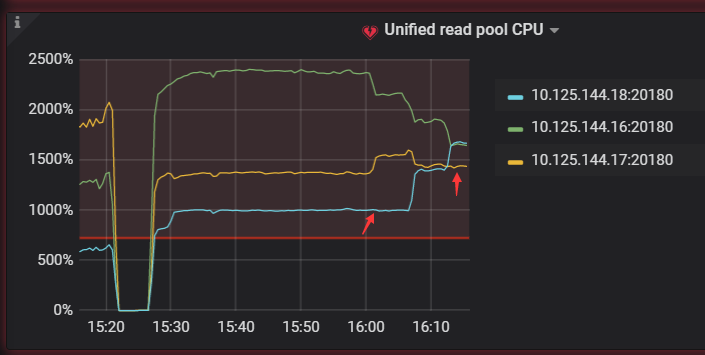
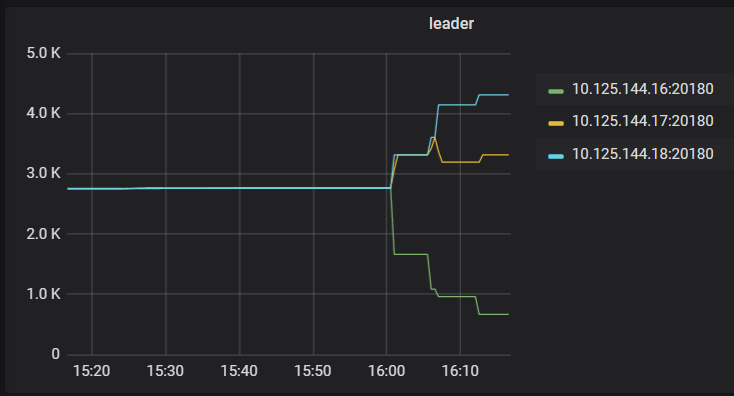
1 个赞
为什么不看 dashboard
1 个赞
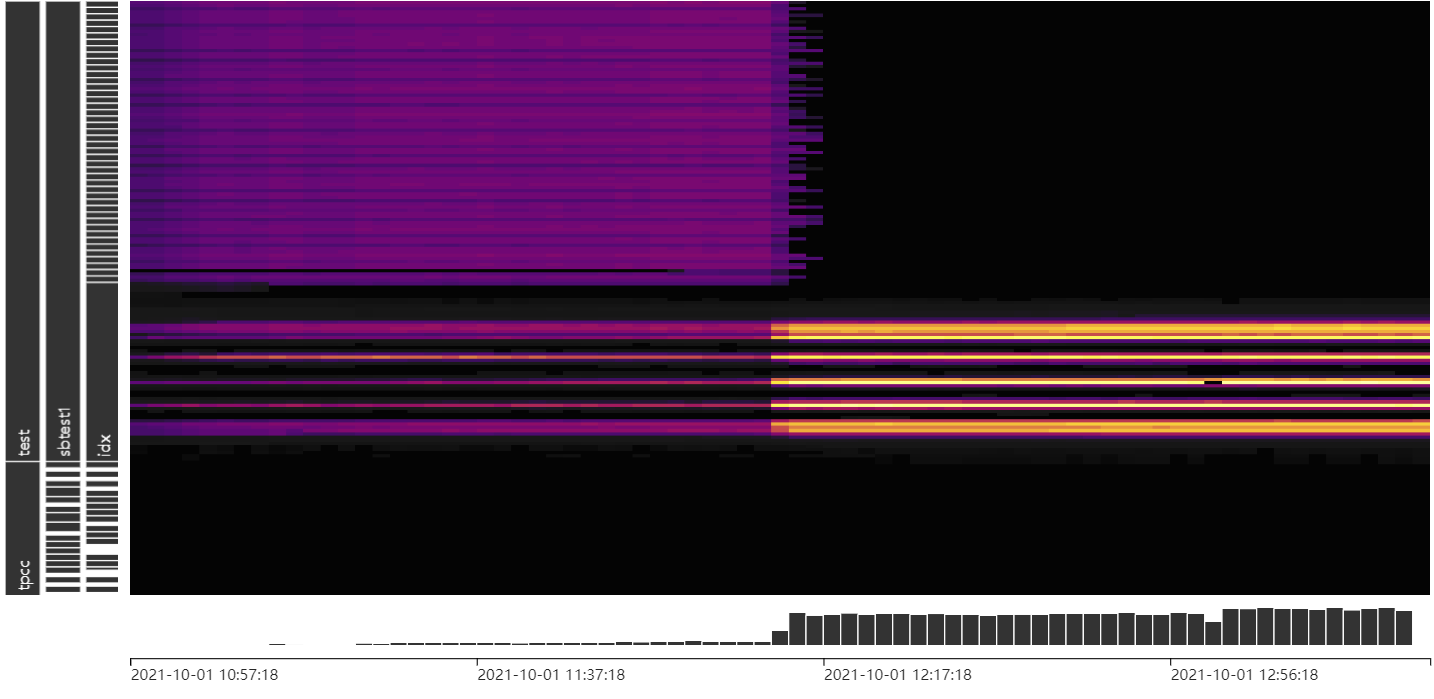
热力图不能看到具体哪些region是访问比较频繁的,想直接定位到这些region然后做split或transfer leader. 系统表只能展示瞬时流量,如果能按时间段查询region的总流量就比较方便了
1 个赞
热力图可以看到 region,你把鼠标放在亮度较高的地方,看看。其他的热点定位及处理,还在优化中
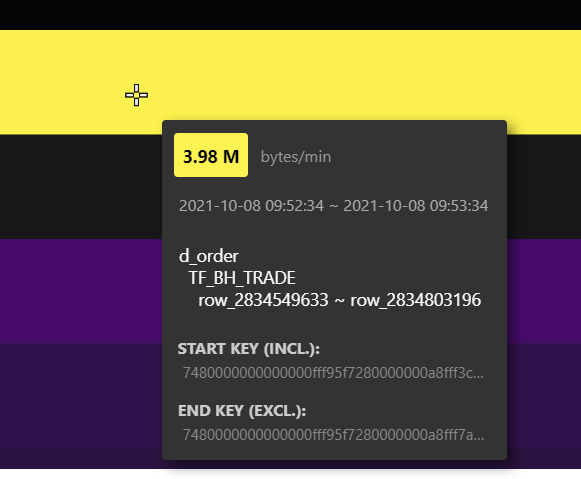 已经放大到最大了
已经放大到最大了
哦,明白你意思了,你要找 region id 对吧,这个确实不能直接显示出来(key 能用 pd-ctl 解析出来 region 信息),另外,你可以看看split.qps-threshold":“3000” 参数
1 个赞
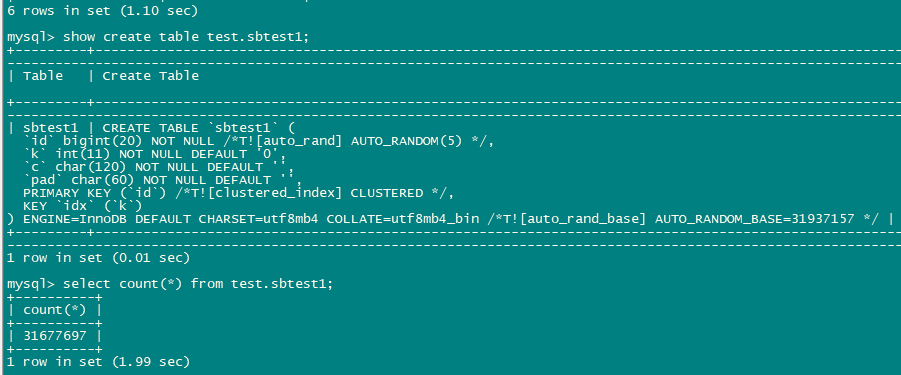
load base split的参数都是默认值,只是比较疑惑开始测试时TIKV_REGION_STATUS 这些系统视图里读流量比较高的对象为啥是stats_meta,后来调整过leader weight也重启过后都是显示的测试表sbtest1了
![]() 不好回答
不好回答
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。