为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
- 【系统版本 & kernel 版本】centos7
- 【TiDB 版本】v3.0.0
- 【磁盘型号】ssd
- 【集群节点分布】3TIKV 3PD 2TIDB
- 【数据量 & region 数量 & 副本数】
- 【问题描述(我做了什么)】
- 【关键词】
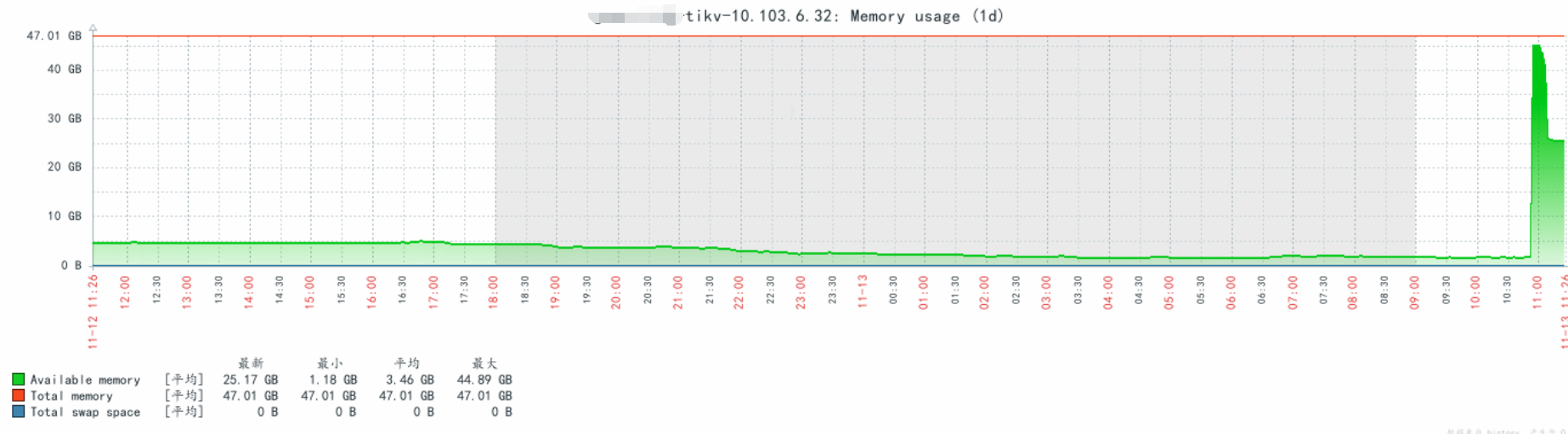
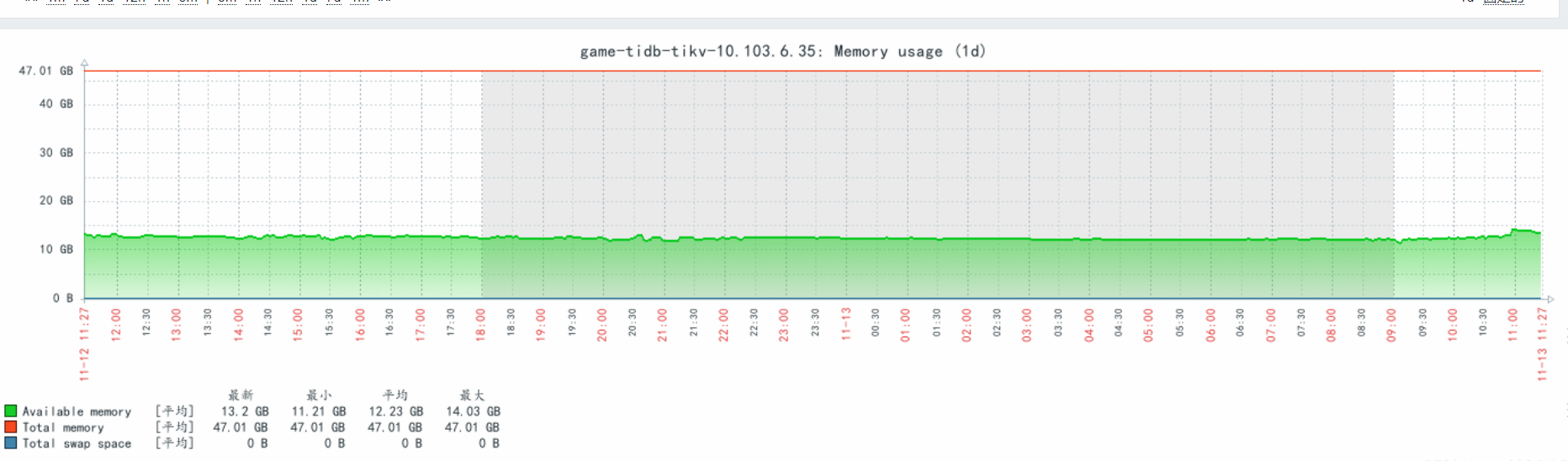
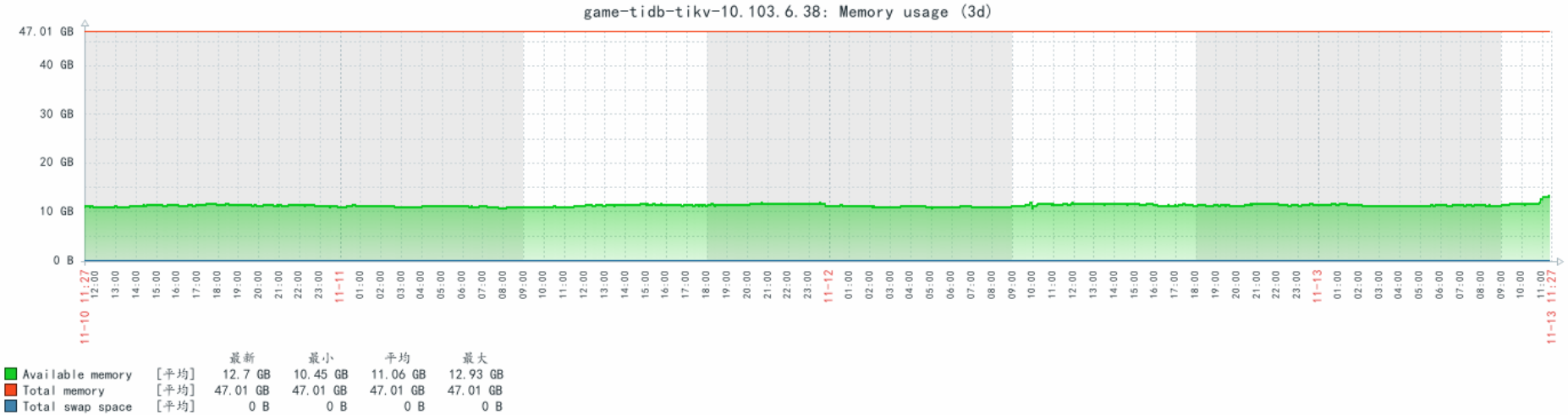
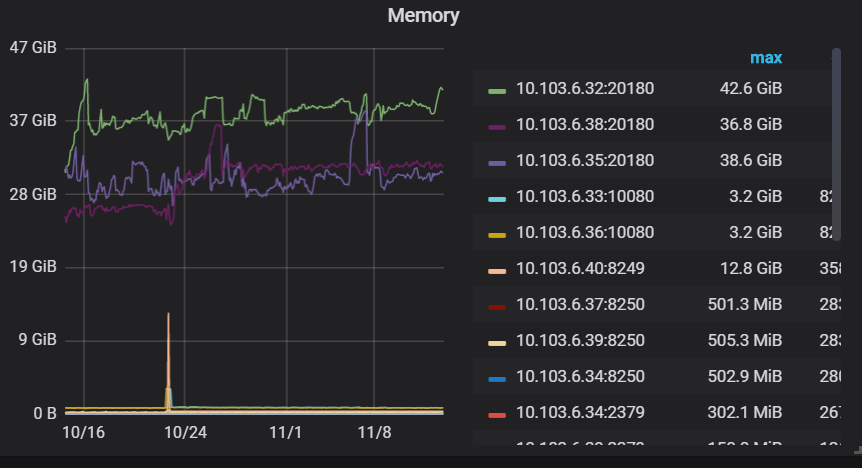
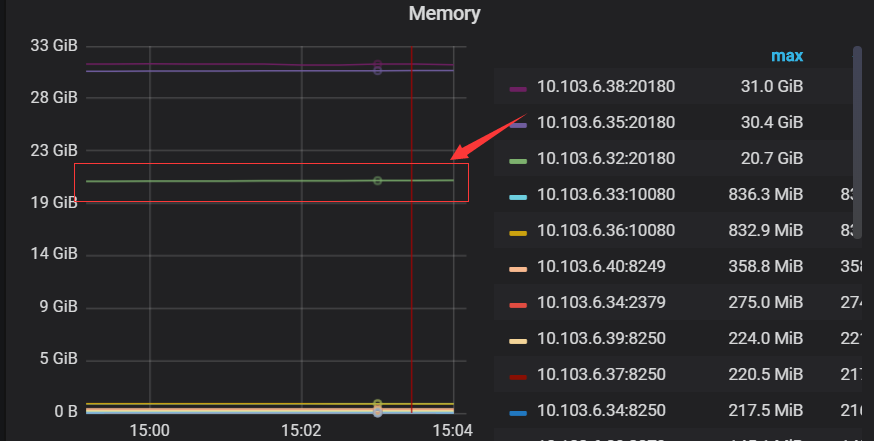
明显看出10.103.6.32这台机器的内存使用率比其他2台都要高。请帮忙看一下问题
为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
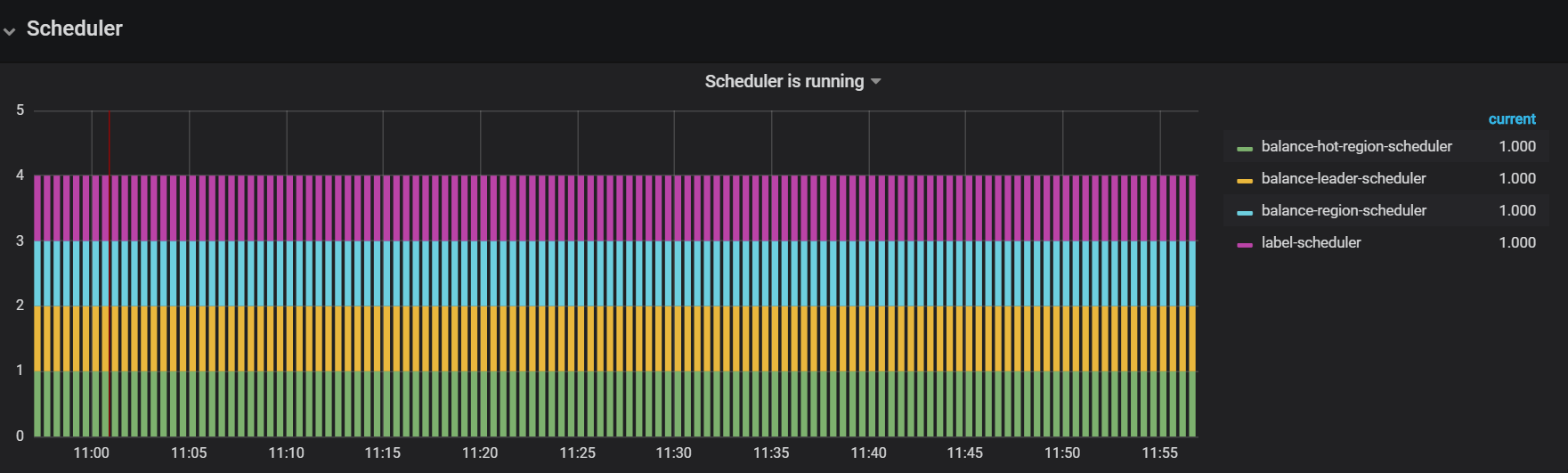
您好: 1. 当前region的数量是多少? 查一下监控,每个节点的region数量,leader数量是否均衡 2. 查看热点,是否集中在这台机器 3. 使用top命令查看每台机器,是否都是tidb占用的内存,排查是否有其他应用的占用,多谢
1、当前region: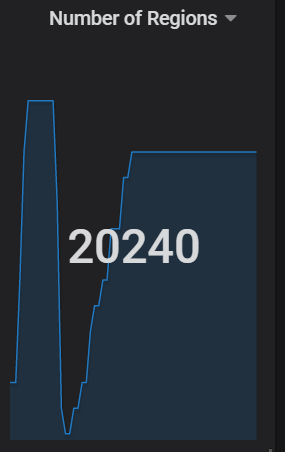
{
“count”: 3,
“stores”: [
{
“store”: {
“id”: 1,
“address”: “10.103.6.35:20160”,
“version”: “3.0.0”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1000 GiB”,
“available”: “743 GiB”,
“leader_count”: 6398,
“leader_weight”: 1,
“leader_score”: 413837,
“leader_size”: 413837,
“region_count”: 20240,
“region_weight”: 1,
“region_score”: 1240961,
“region_size”: 1240961,
“start_ts”: “2019-08-15T20:48:14+08:00”,
“last_heartbeat_ts”: “2019-11-13T11:56:13.452877341+08:00”,
“uptime”: “2151h7m59.452877341s”
}
},
{
“store”: {
“id”: 4,
“address”: “10.103.6.32:20160”,
“version”: “3.0.0”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1000 GiB”,
“available”: “742 GiB”,
“leader_count”: 6771,
“leader_weight”: 1,
“leader_score”: 413258,
“leader_size”: 413258,
“region_count”: 20240,
“region_weight”: 1,
“region_score”: 1240961,
“region_size”: 1240961,
“start_ts”: “2019-11-13T11:04:44+08:00”,
“last_heartbeat_ts”: “2019-11-13T11:56:14.417547047+08:00”,
“uptime”: “51m30.417547047s”
}
},
{
“store”: {
“id”: 7,
“address”: “10.103.6.38:20160”,
“version”: “3.0.0”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1000 GiB”,
“available”: “744 GiB”,
“leader_count”: 7071,
“leader_weight”: 1,
“leader_score”: 413866,
“leader_size”: 413866,
“region_count”: 20240,
“region_weight”: 1,
“region_score”: 1240961,
“region_size”: 1240961,
“start_ts”: “2019-08-15T20:51:55+08:00”,
“last_heartbeat_ts”: “2019-11-13T11:56:16.515865671+08:00”,
“uptime”: “2151h4m21.515865671s”
}
}
]
}
2、
您好: 请执行以下top命令,按m,按照内存大小排序,查看占用内存高的进程,记录进程id cat /proc/{pid}/status, 查看内存占用的多少.
您好: 那先观察一下吧,等到下次出现这种情况,先查看一下具体是哪个进程,再看下这个进程里内存分配的情况,多谢。