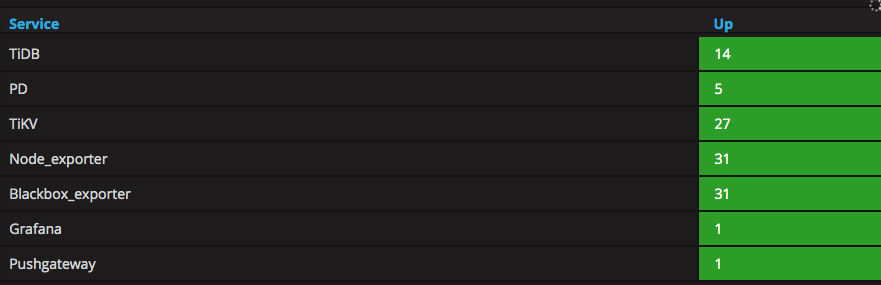
这是我的集群现状
LSB Version: :core-4.1-amd64:core-4.1-noarch:cxx-4.1-amd64:cxx-4.1-noarch:desktop-4.1-amd64:desktop-4.1-noarch:languages-4.1-amd64:languages-4.1-noarch:printing-4.1-amd64:printing-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.4.1708 (Core)
Release: 7.4.1708
Codename: Core
Linux 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
我目前的计算用的有点狠,经常会用满, 见下图
一般出现这种情况,持续走低,过一会这台计算节点就宕机了
这是宕机的最后一眼,看样子像是oom kill 导致的.问我们的运维,给出的答复就是内存别用太狠了.(暂时还没有其他骚操作)
这个宕机,完全是看运气了(运气好大喘气内存一个大释放,运气不好机器就宕了),目前的结果是不完全认为是内存问题,但是内存是问题的可能之一
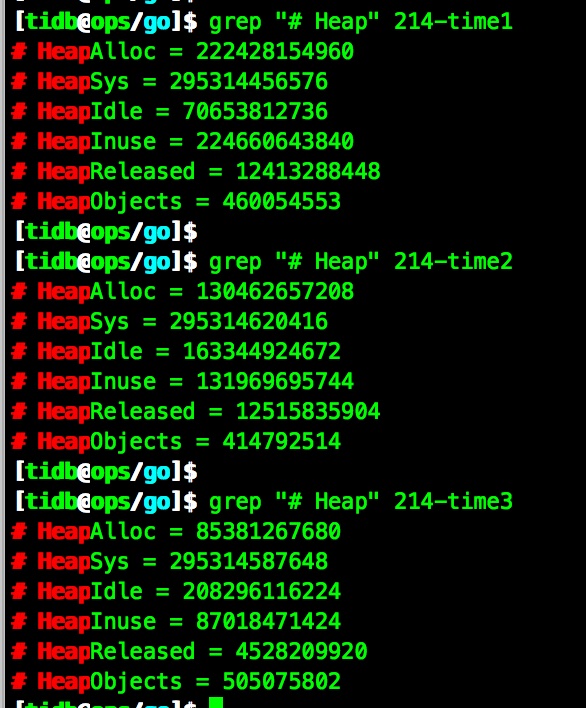
我使用命令观察了heap内存,分别记录了3个时间
从heap的3个时间来看,内存应该是在慢慢的归还.
我的问题
从监控上来看,内存是吃满了,从go监控命令来看内存在慢慢归还给tidb.
那我现在的计算节点是 真正 可用状态吗?
可以继续往里面 捅 吗,还是说等到内存归还给操作系统才能放心 捅 呢?
内存占用较多的时间段是因为业务访问量大吗?先确认一下是不是系统本身就要占用这么多内存
因为前面做了haproxy, 路由到后面的计算就打散了.不知道谁是谁,不好分辨属于谁的业务.
有什么办法能够 精确 的知道,当前计算节点,分别有多少sql在执行,分别占用了多少内存呢?
我现在只知道在当前节点使用 SHOW FULL PROCESSLIST; 查看, 但是里面的内存显示,会与监控上的差距很大.
比如现在我这个节点只剩几十mb了
用这个命令查看,就有2个显示了内存
用管理命令查看堆内存
最后这内存差距
31664766976
204591886
是我这找到思路不对吗?
其实我就像实时知道到底是谁的sql占用了这么多资源.
印象中可以去看slow_query.log,但是那个是事后的把,我想知道实时的.
1.通过查询 TiDB 面板的 QPS By Instance 这个监控指标能查看到每个 TiDB 执行的 SQL 数量,但是没有办法统计每条 SQL 查用的内存
2. 是的 SLOWQUERY LOG 是事后记录的,只有在 SQL 查询的时间超过 slow-threshold 值时才会记录,因此也没有办法获取得全量的 SQL 及每条 SQL 占的内存
3. Show full processlist 只是记录当前正在执行的命令占用内存的情况,并不是全部
可以先尝试一下限制每条 SQL 使用内存的大小,通过修改 mem-quota-query 这个参数
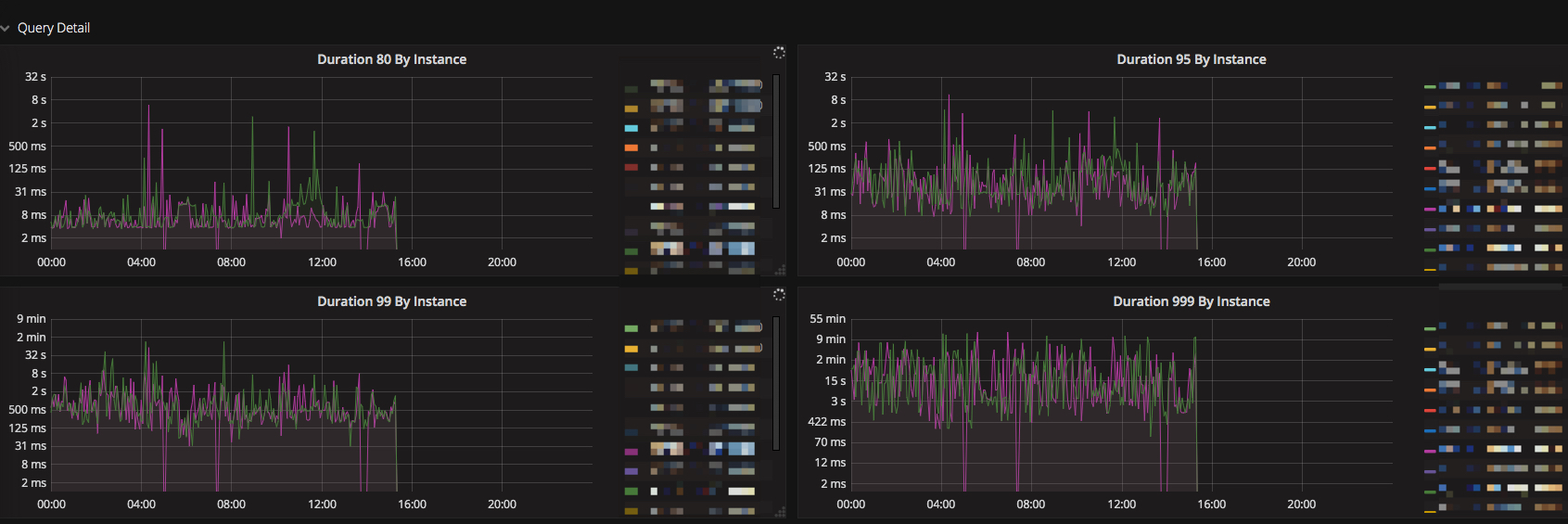
能将占用内存比较多的时间段,QPS,延时相关的监控提供一下吗
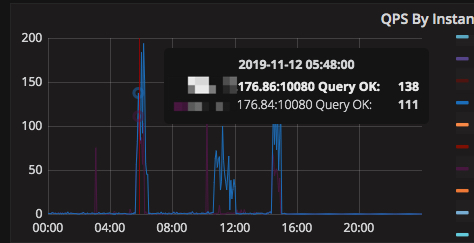
我现在是有2套计算集群,有1套就是像你说的,开启了oom-action为cancel的
另外一套就是现在这个不稳定的,我现在已经在入口处的haproxy做了根据资源进行负载均衡,但是还是会出现几个峰值上来,就把计算节点给捅死.(并且已建立连接的,会绕过这个均衡)
因为这套集群上是不建议去随意kill掉的,有不有这样的办法呢?比如计算节点达到阈值,我把接来下的计算进行转发让它去重走haproxy路由到有资源的节点,或者让它排队.
yilong
(yi888long)
8
针对单独sql设置了内存oom限制之后,如果超过阈值,这条连接终止后,如果业务侧能根据报错重试这个语句,也许可以重新走HAproxy
system
(system)
关闭
9
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。