为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
- 【系统版本 & kernel 版本】 centos7
- 【TiDB 版本】 tidb v2.1.1
- 【磁盘型号】 ssd
- 【集群节点分布】 2tidb+3PD+3tikv
- 【数据量 & region 数量 & 副本数】 2
- 【问题描述(我做了什么)】SQL 跨库查询,怎么优化 SQL 跨库查询,怎么优化 现在从应用本身的数据库查询很快,但是需要跨其他的数据库查询,这样就很慢,请问有什么优化措施吗?
为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
请问具体的跨库查询操作是怎么样的?
在tidb实例下有两个数据库、customerdb、employeedb客户数据库和人事数据库,现在有一个应用通过关联关系通过SQL在两个数据库下查询 SQL如下: SELECT DISTINCT cr.customer_id FROM tb_customer_relationship cr where EXISTS ( select e.id_number FROM employeedb.employee e JOIN employeedb.employee_record er ON e.user_id = er.oid WHERE e.id_number = cr.employee_certi_no and (er.employee_status = 8 or e.std_is_deleted = 1) )
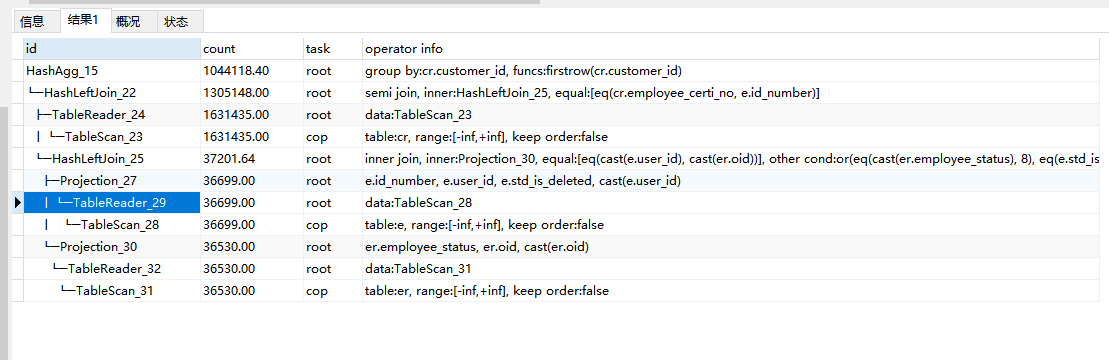
可以提供一下 explain analyze 的执行计划吗
这个跨库关联查询的关联操作都是在 TiDB 层完成的,无法利用 Coprocessor 下推到 TiKV 层利用 TiKV 的计算资源,所以效率上会比较低,而且下推的 Coprocessor 也是 tablescan ,属于低效操作
能不能给一个推荐的优化方案,优化SQL也行。
可以看下
explain analyze SELECT e.id_number
FROM employeedb.employee e
JOIN employeedb.employee_record er ON e.user_id = er.oid
WHERE e.id_number = cr.employee_certi_no
AND (er.employee_status = 8
OR e.std_is_deleted = 1
子查询的执行计划以及
explain analyze
SELECT e.id_number
FROM employeedb.employee e
JOIN employeedb.employee_record er ON e.user_id = er.oid
WHERE e.id_number = cr.employee_certi_no
AND er.employee_status = 8
union
SELECT e.id_number
FROM employeedb.employee e
JOIN employeedb.employee_record er ON e.user_id = er.oid
WHERE e.id_number = cr.employee_certi_no
AND e.std_is_deleted = 1
的执行计划
1。
建议先从架构层面优化。
yuelu86
中心数据库是按照三范式设计的,面向业务端单表的增删改查。
同时跨库场景为联合客户和员工表统计。
类似这种需求应从服务中心(类似数仓的服务层)整合数据之后提供。
2。尽快升级3.0
3.0版本对SQL多表关联查询有一定优化,性能翻倍。
3、后续版本希望能够将利用Coprocessor 结合pd元数据信息将不需要数据迁移的在节点完成join后返回
@ gangshen-PingCAP
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。