为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
- 【系统版本 & kernel 版本】centos 7.5
- 【TiDB 版本】2.13
- 【磁盘型号】ssd
- 【集群节点分布】3pd 10kv(5物理机) 3tidb
- 【数据量 & region 数量 & 副本数】
- 【问题描述(我做了什么)】经常收到告警PD_leader_change,查看日志没有明确的线索
- 【关键词】
为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
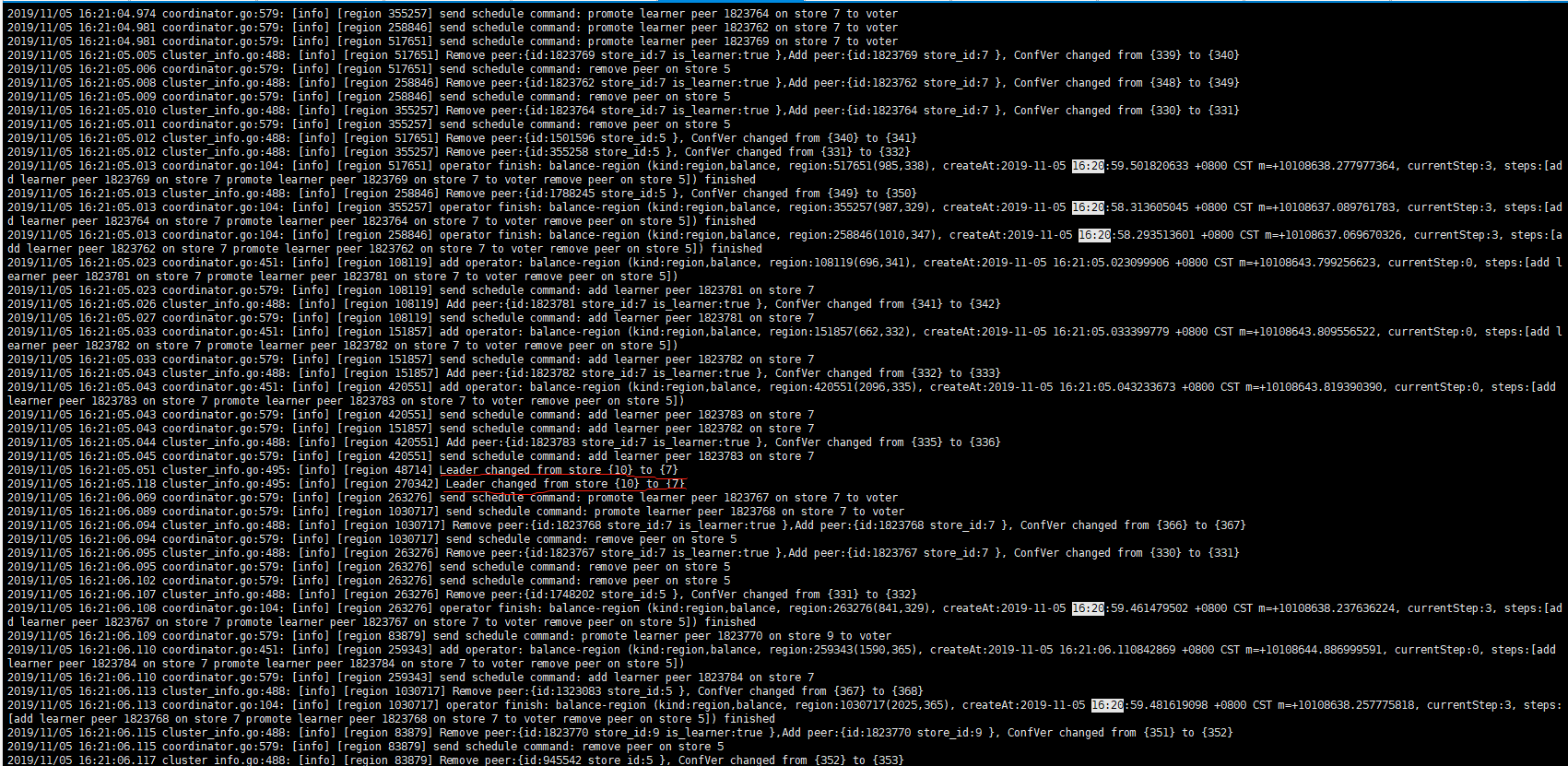
其他两个pd的日志都很少10分钟,只有81这台机器有pd change日志,想知道发生这个change的原因是什么,怎么排查呢
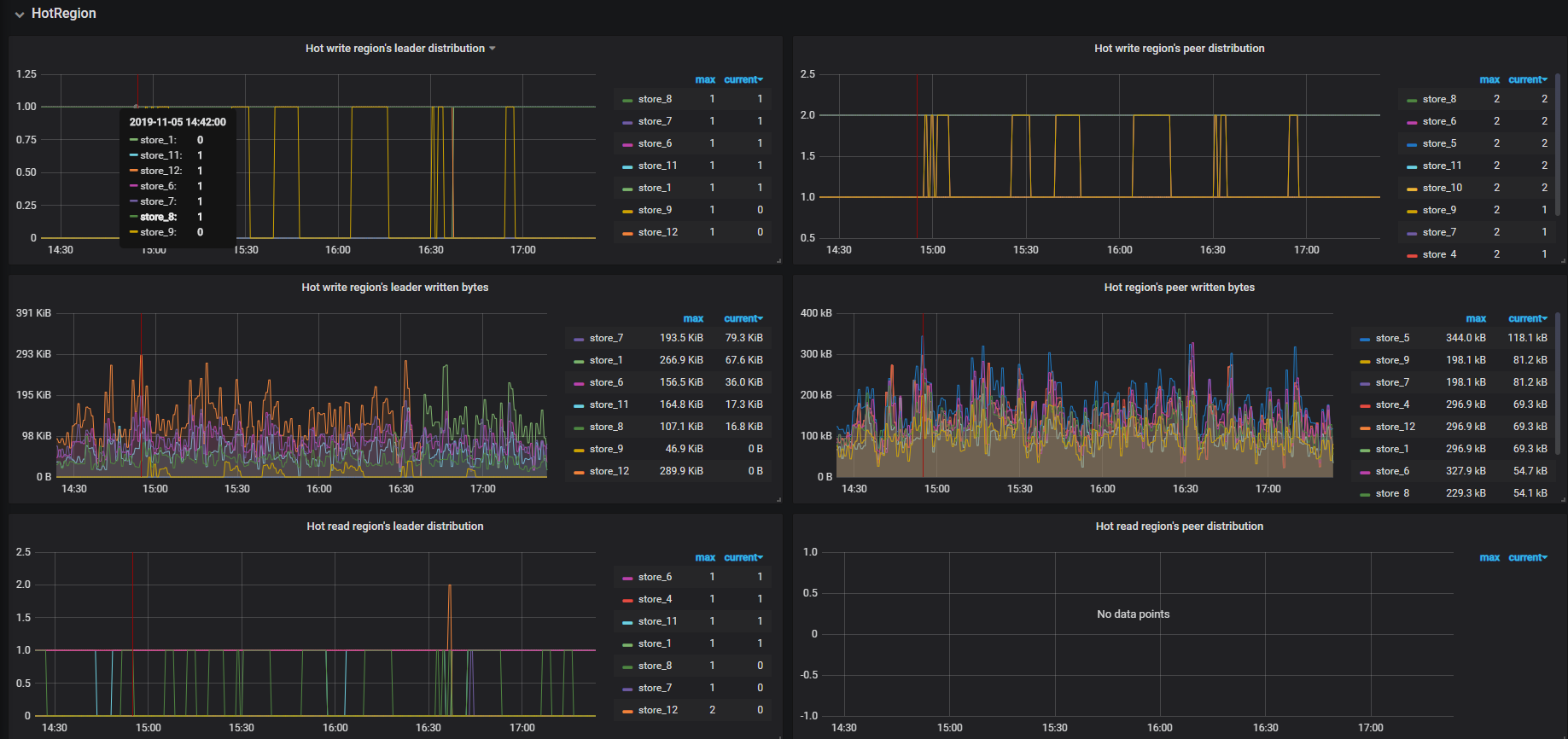
region 调度主要从两个方面来考虑:一个是磁盘剩余容量,另一个是 hot region 的调度。先看下这两块的监控。
1、首先日志中显示的是 region leader 的 change 不是 pd 的 leader 的 change。并且这个 change 显示的是将 region 的 leader 从 store 10 调度到了 store 7.
2、 region 的 leader 的调度依赖于 PD 的调度策略,比如 region 的 leader 的调度是依据 region size 的量,hot region 的调度,是依据热点调动的算法。想了解更多内容,推荐看下下面的博客:
3、在 pd 中可以通过 pd-ctl 来查看当前的 scheduler 调度器,比如 leader 的 scheduler,region scheduler 等调度器
好的,这个我在研究下。 另外还有一个经常告警TiDB_monitor_keep_alive,我看了下各节点tidb的进程都是正常的,各节点间的日志也无异常,但经常时不时告警一下,请问这个问题要怎么排查呢,会不会有什么隐患呢
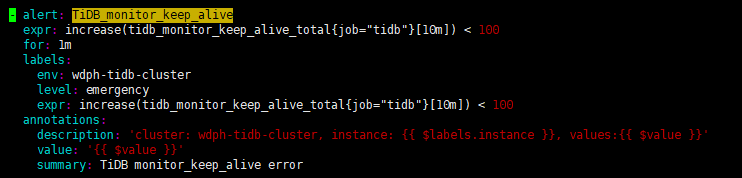
告警表示 10 分钟内 tidb_monitor_keep_alive_total 的次数少于 100 会告警,可以在目标 tidb 的 server 上手动的监控下 10 分钟内的数值变化情况。另外,如果告警不符合预期,可以根据自己的需求手动调整~~~
这个文档介绍我看过,你们肯定有命令去采集的,现在的问题是经常告警,实际情况tidb并没有问题,进程一直都存在,日志也正常,所以我想知道你们是具体通过什么命令采集的tidb进程不存在的
这一块是写在我们代码中的:
好的,谢谢
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。