-
【 系统版本 & kernel 版本 】谷歌云 Linux gke-tidb-default-pool-c644815e-mfdm 4.14.137+ #1 SMP Thu Aug 8 02:47:02 PDT 2019 x86_64 Intel® Xeon® CPU @ 2.20GHz GenuineIntel GNU/Linux
-
【 TiDB 版本 】Container image “pingcap/tikv:v3.0.4”
-
【 磁盘型号 】单个虚拟机的启动磁盘1个100G,SSD磁盘两个,分别为1G和10G
-
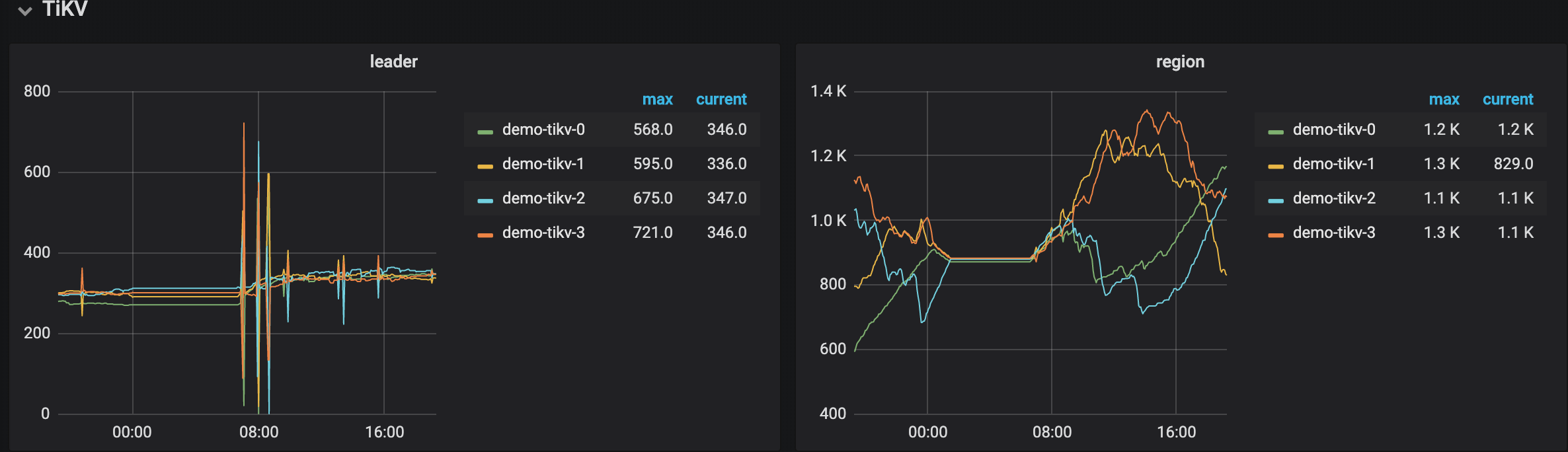
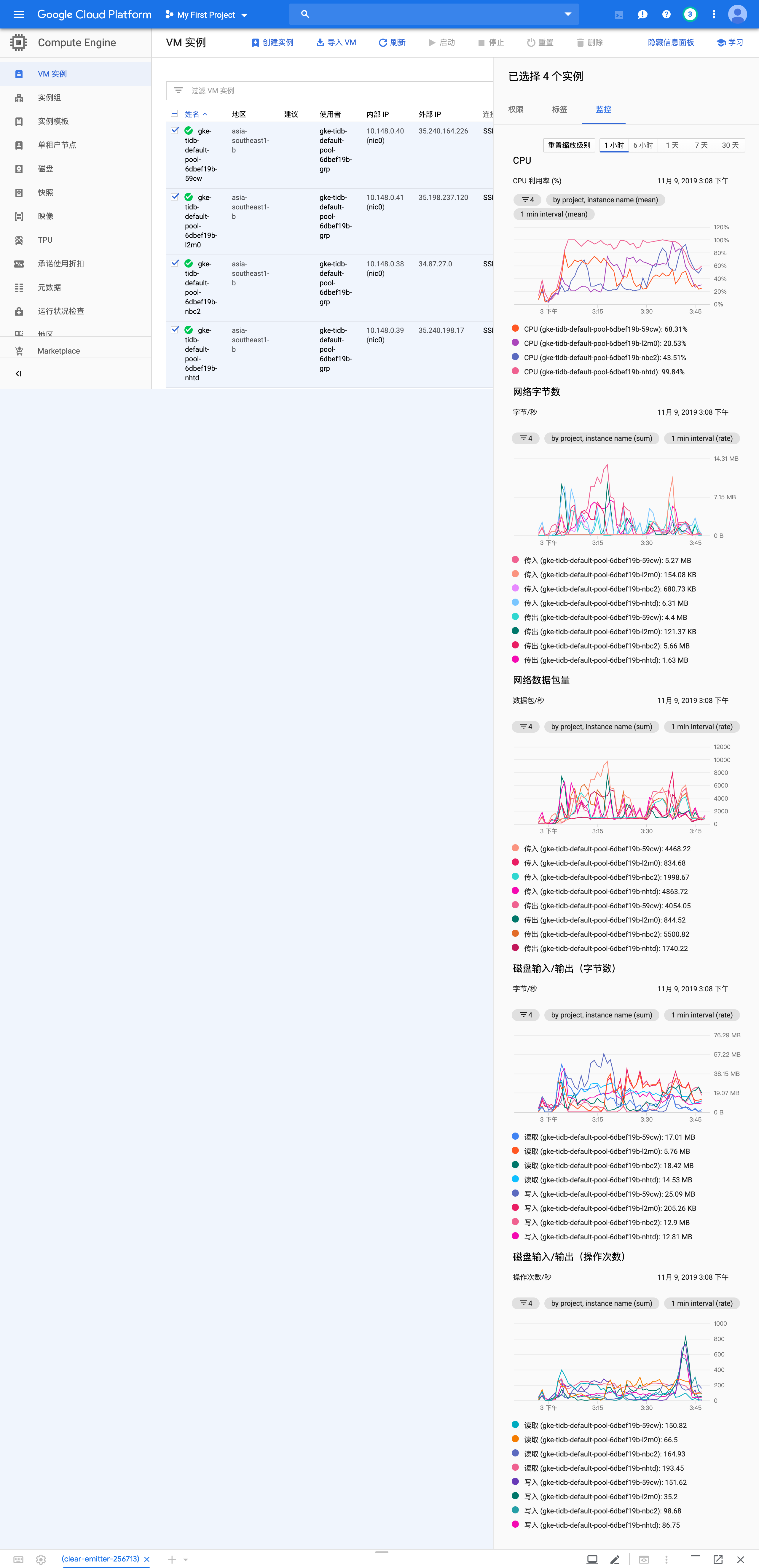
【 集群节点分布 】4个vm节点
NAME READY STATUS RESTARTS AGE
demo-discovery-76d999b748-bgsk9 1/1 Running 0 25h
demo-monitor-648447d8f-sj7pp 3/3 Running 0 25h
demo-pd-0 1/1 Running 0 25h
demo-pd-1 1/1 Running 1 25h
demo-pd-2 1/1 Running 0 25h
demo-tidb-0 2/2 Running 0 25h
demo-tikv-0 1/1 Running 0 17h
demo-tikv-1 1/1 Running 0 6h15m
demo-tikv-2 1/1 Running 0 25h
demo-tikv-3 1/1 Running 0 12h
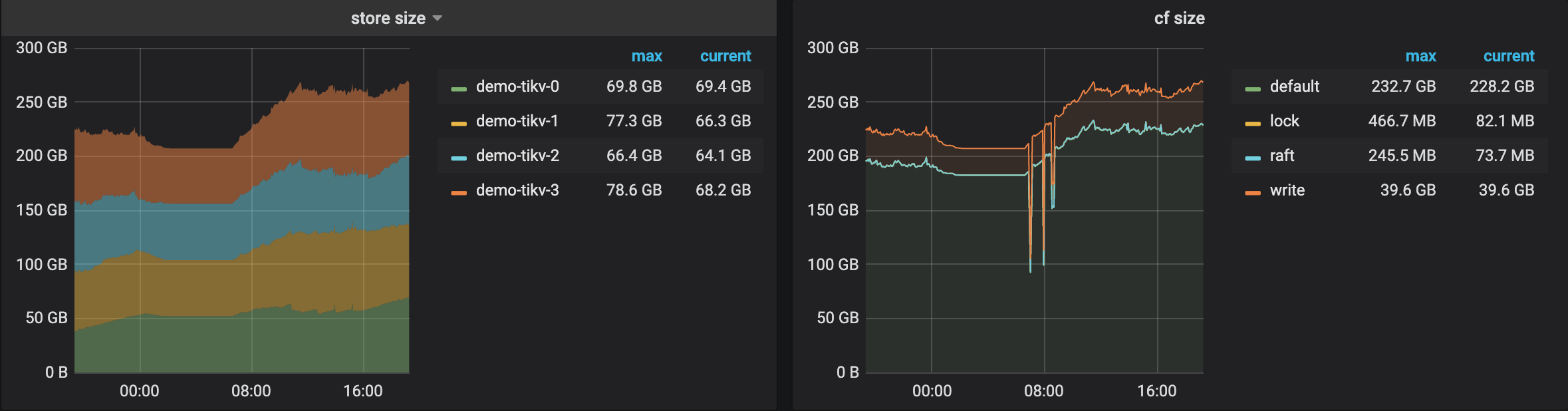
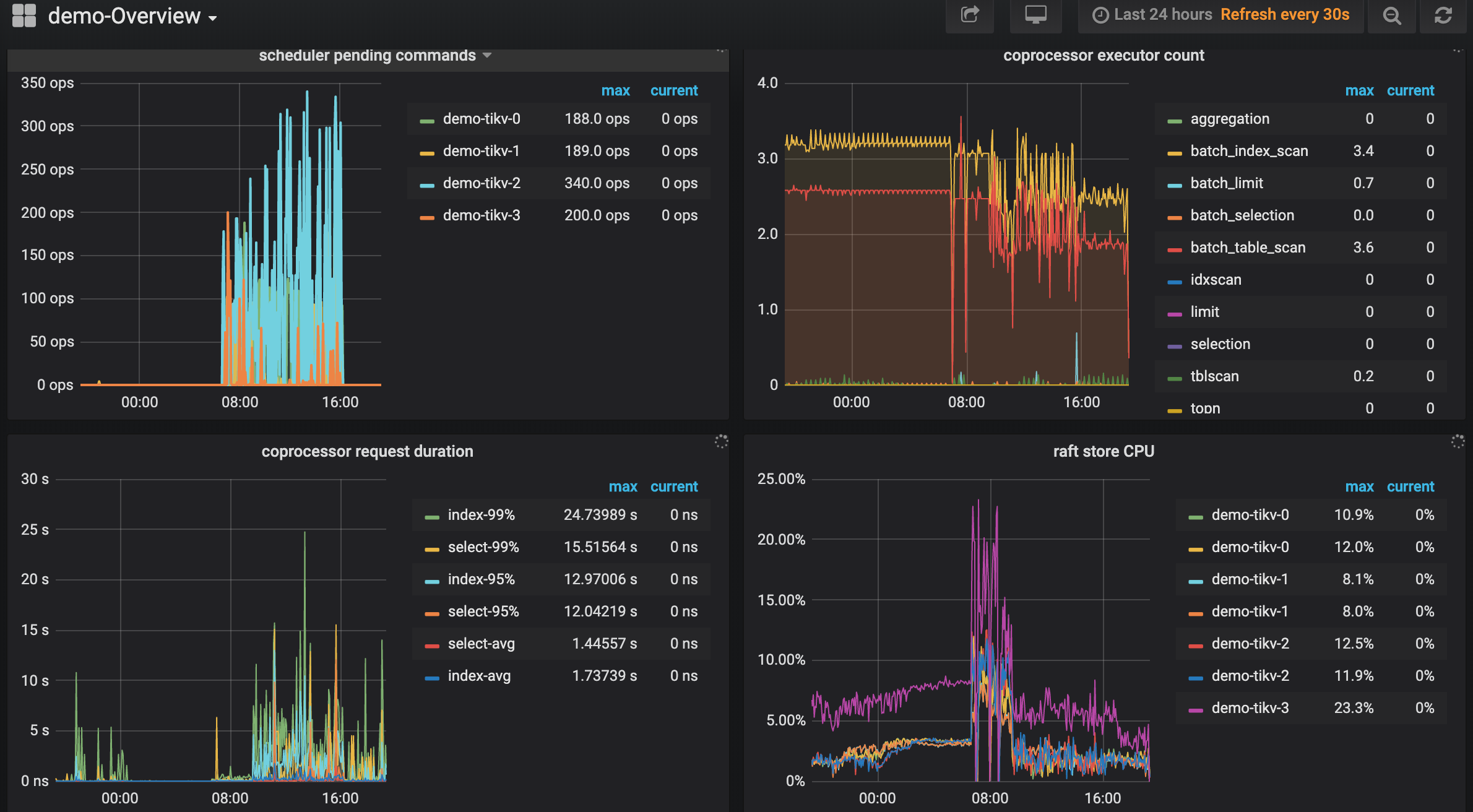
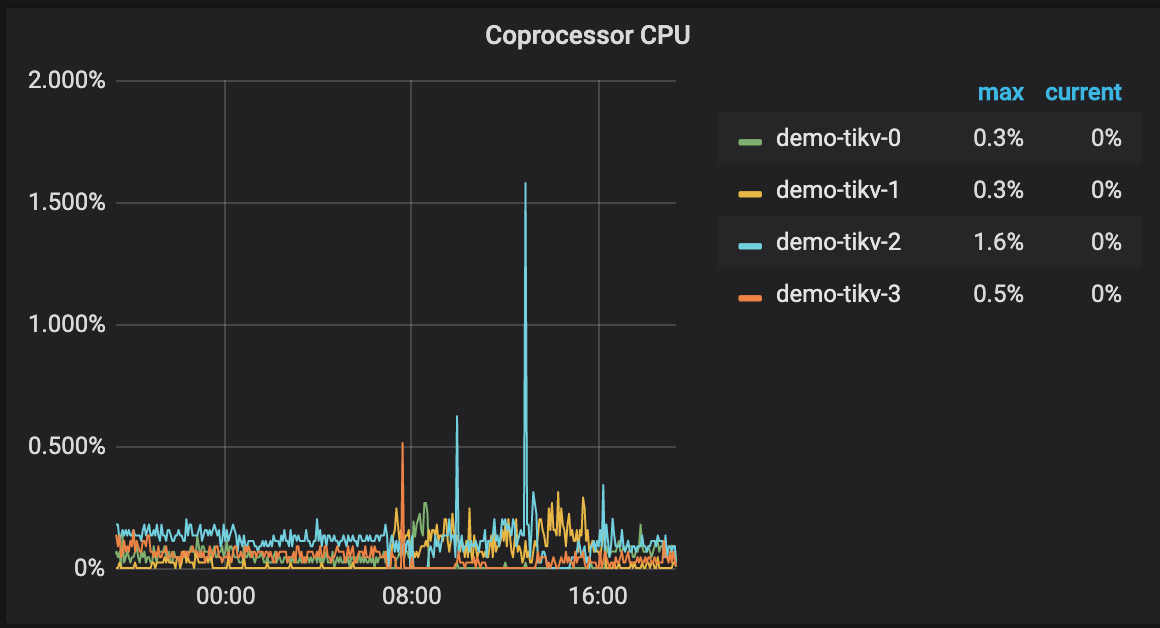
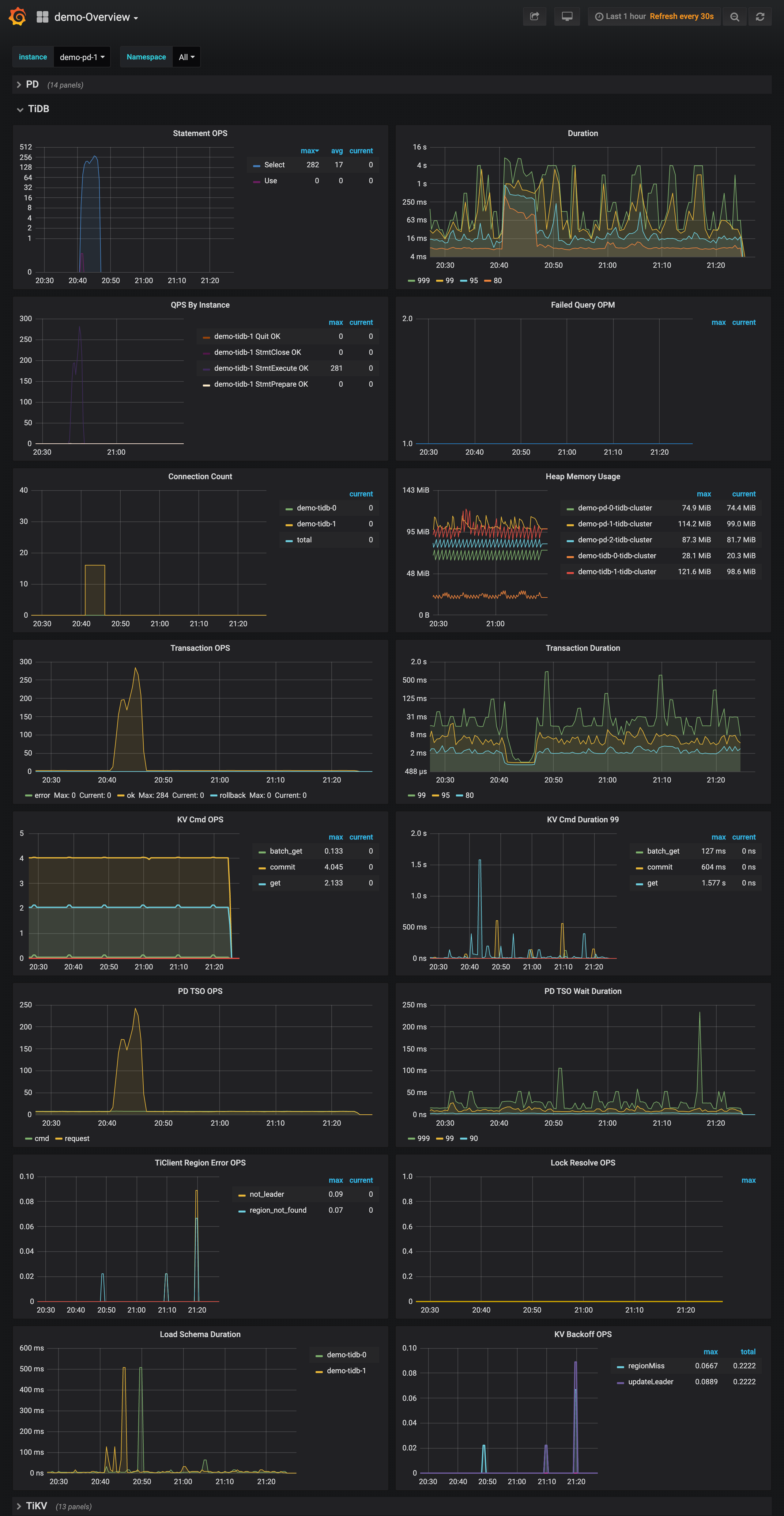
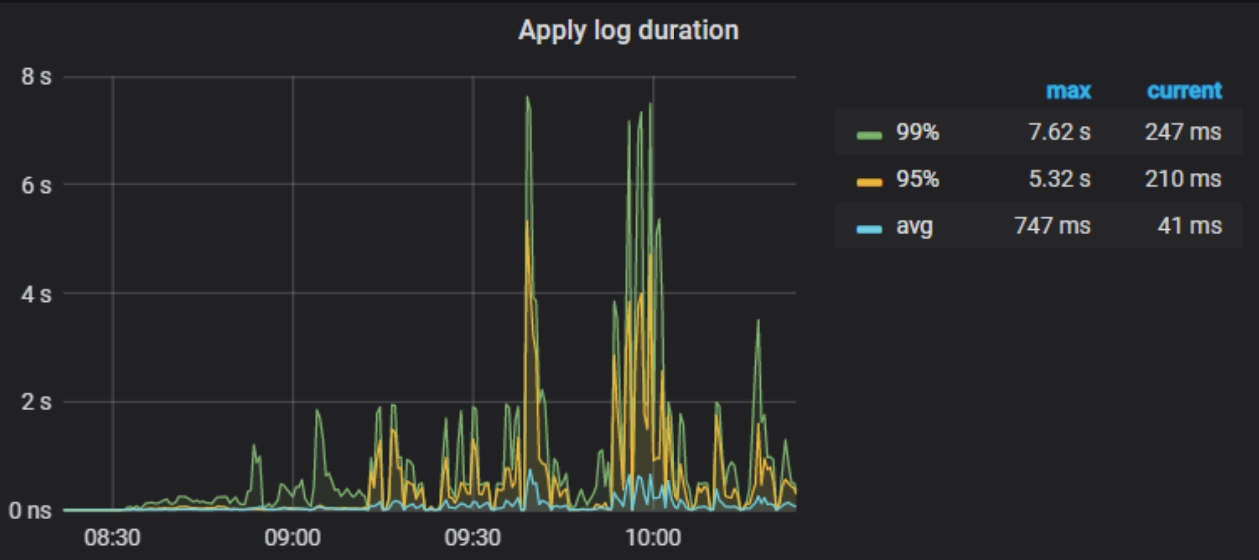
- 【 数据量 & region 数量 & 副本数 】只有单库单表3.6亿记录,4个tikv的region数分别为900、1.1k、1.1k、1.1k,store size分别为54GB、64GB、70GB、70GB
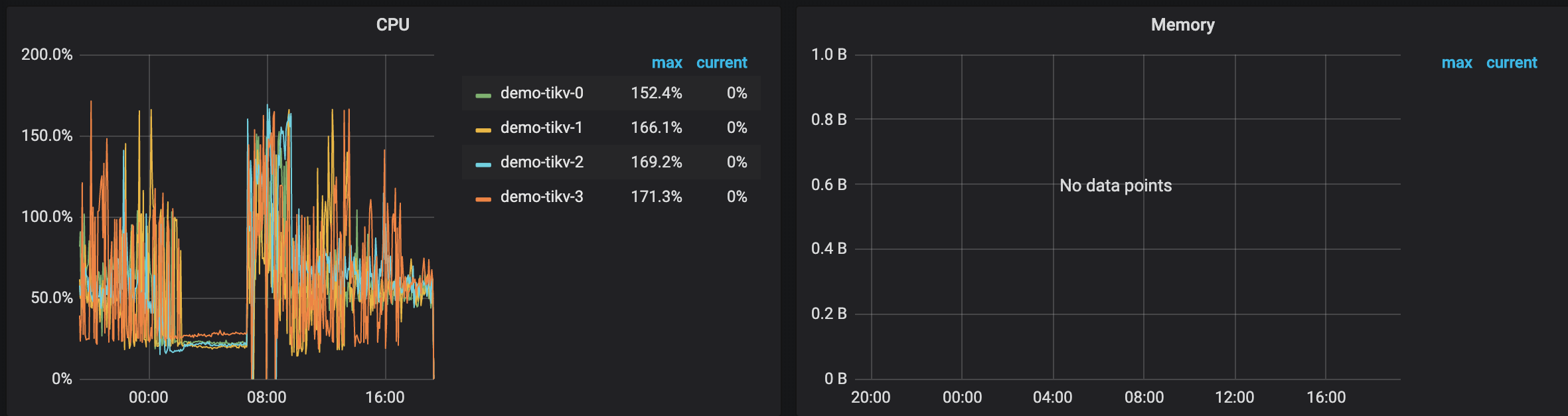
- 【 问题描述(我做了什么) 】 k8s集群新增tikv节点后,tikv节点数据看似已经均衡。 使用loader加载数据,比之前加载速度明显慢。 sysbench的oltp_point_select测试,152.90 qps。而之前3亿数据的qps是988.23。