【系统版本 & kernel 版本】
cent OS 7
【前置条件】
数据量:700W
【TiDB 版本】
3.0.5
【问题描述(我做了什么)】
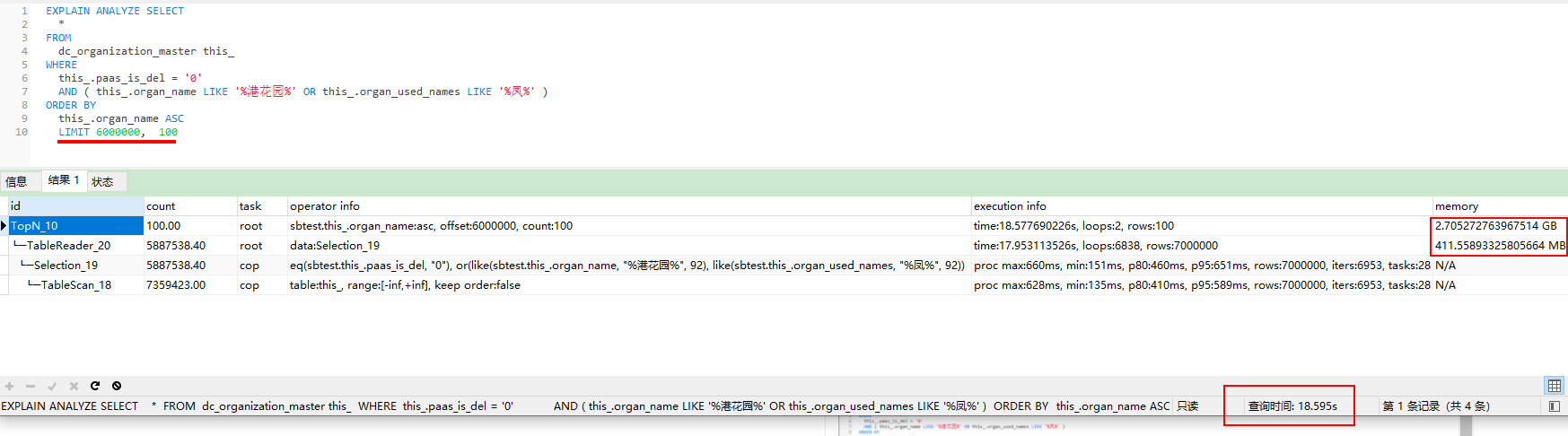
做分页查询 LIMIT 0, 100 与 LIMIT 6000000, 100 查询效率的区别
cent OS 7
数据量:700W
3.0.5
做分页查询 LIMIT 0, 100 与 LIMIT 6000000, 100 查询效率的区别
LIMIT 0, 100
LIMIT 6000000, 100
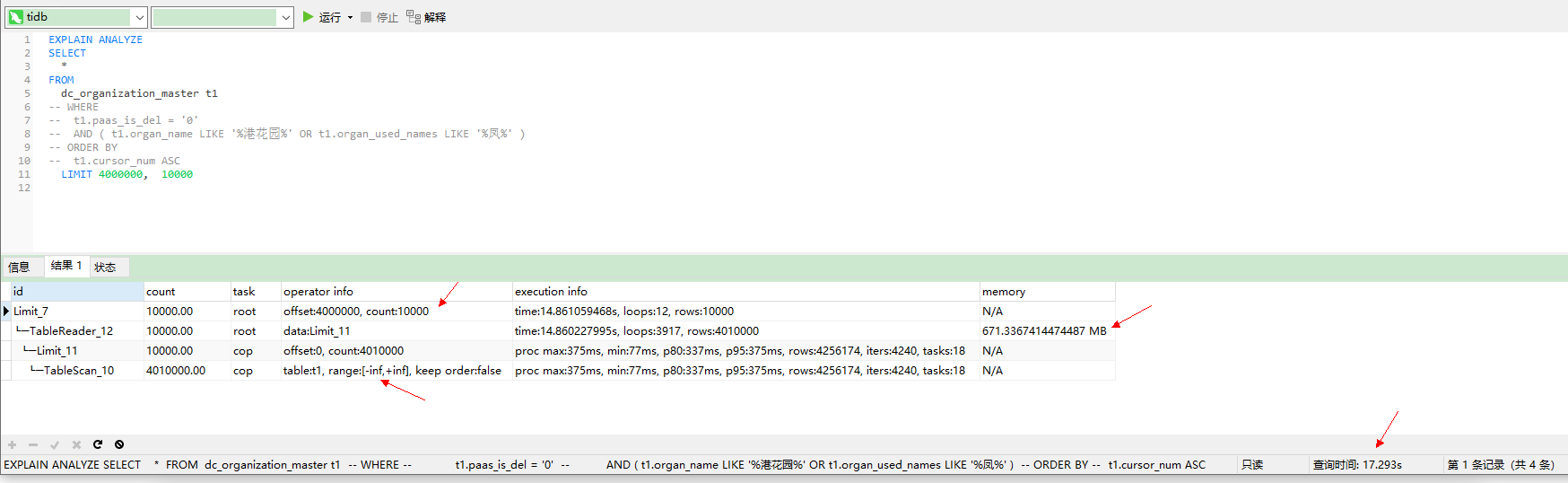
建议用自增主键作为游标取代limit offset的分页方式
分布式数据库中,对于LIMIT M,N的操作,M和N较小时,在每个TiKV节点上通过TOP(M+N)方式获取每个节点上的数据,然后在TiDB节点上进行汇总排序(如果有的话),然后取第M到(M+N)个数据,但是当M或者N比较大时,每个TiKV节点上要获取大量的数据,然后在TiDB节点上进行汇总,这对于TiDB节点的内存和CPU都是比较耗资源的
对于这种查询的优化,可以考虑像@Limbo提到的:用自增主键作为游标取代limit offset的分页方式
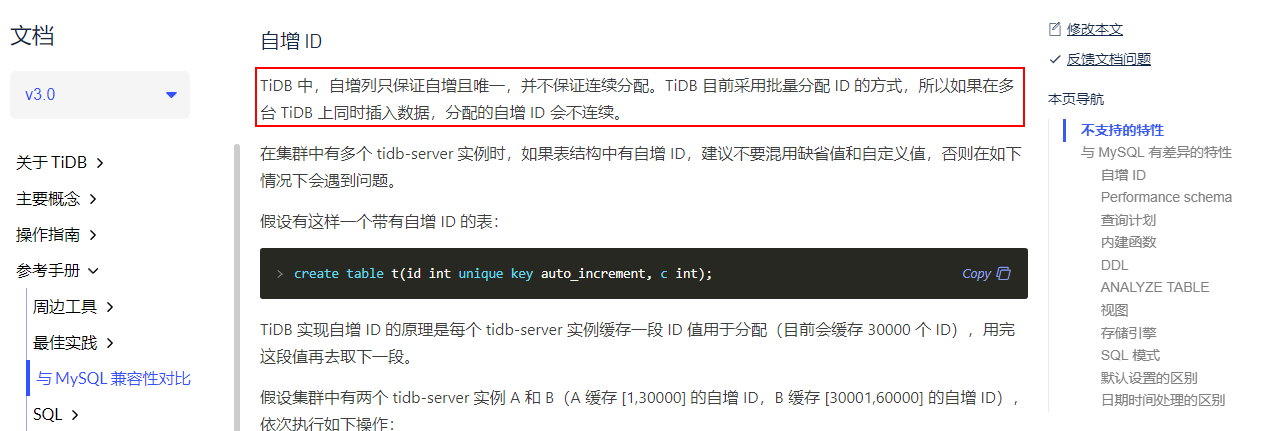
用自增主键作为游标取代limit offset的分页方式,会不会受到 https://pingcap.com/docs-cn/v3.0/reference/mysql-compatibility/#自增-id 的影响
使用自增唯一键作为游标取代 limit offset 分页需要注意的是,由于 TiDB 里面自增列只保证自增且唯一,所以有可能自增列会存在空洞(例如:limit 10 offset 2 有可能 ID 返回的 3,4,5,6,7,30001,30002,30003,30004,30005),还有一点就是自增 ID 的顺序与 数据 Insert 的顺序 没有必然的关系。另外,更加建议使用的是自增唯一键,而非自增主键。自增主键有可能会引发写热点问题。
谢谢老师,我了解了一些,我还有几个点不明白
因为 TiDB 是分布式的,没办法像单机写入那样一直顺序写,只能保证在某一段区间是顺序的,另外自增唯一键,空洞问题是会存在的。如果对 Insert 顺序比较敏感的话,可以考虑在应用端改造。
那,使用自增主键作为游标,这个方案来优化查询,是不是因为空洞的问题也就变的不可行了?
可以考虑在应用端当前查询的批次的最大值缓存下来,然后下一批次从上次最大值开始的方式来查询。当前情况下来说单纯用自增 ID 的方式无发满足对 Insert 顺序敏感的场景。
我明白了谢谢老师
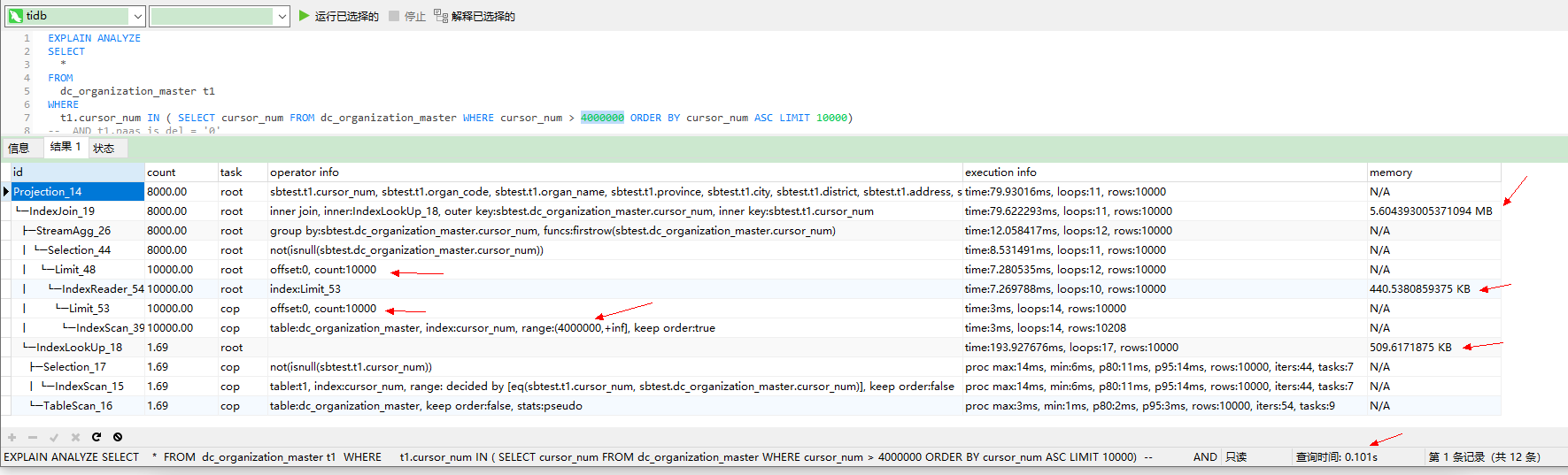
给个语句吧 应该怎么写 这种带 自增id 唯一约束 的limit
SELECT
*
FROM
dc_organization_master t1
WHERE
t1.cursor_num IN ( SELECT cursor_num FROM dc_organization_master WHERE cursor_num > 4000000 ORDER BY cursor_num ASC LIMIT 1000)
多谢了
这样快? 我怎么感觉 比正常的limit要慢呢
nice
自增唯一键是不是仍然存在写热点问题,是否可能引发写热点和是否是主键没有必然联系?
就目前 3.0.5 的版本,可以通过 SHARD_ROW_ID_BITS 缓解无主键以及主键为非 int 类型的数据写入热点的问题。通过设置 SHARD_ROW_ID_BITS,可以把 rowid 打散写入多个不同的 Region,缓解写入热点问题。pre_split_regions 可以在大批量加载数据的时候进行预分片。
原则上在 tidb 中不建议使用自增键作为主键,因为容易引起写入热点问题。当然如果将自增键作为唯一键,也有可能会出现写入热点问题,此时与主键无关。目前针对索引热点内部已经在着手解决了,敬请期待。
因为是异步导入的数据,中间会出现以下情况

而我又必须按照日期排序 然后从中进行分页处理,就不能使用cursor_num>(pageNum-1)*pageSize 这样的条件了
这个需要怎么处理吗?
大批量数据分页查询非常慢 这个帖子已经回答,多谢