tuyi
2019 年10 月 29 日 12:26
1
【系统版本 & kernel 版本 】Linux host-10-128-3-57 3.10.0-862.el7.x86_64
【TiDB 版本 】2.1.16
【集群节点分布 】
【数据量 & region 数量 & 副本数 】
三台服务器都是8个CPU,其中56,57两个节点的load【1m】经常处于8以上,而55这台服务器负载在3左右。
show processlist没有复杂的SQL在跑
请问各位大佬,这种问题该如何排查呢?
先排查一下是否读写不均匀,存在读写热点。
1)读热点排查,通过看 QPS 监控中的 kv_get 和 kv_coprocessor 对比下这三台机器,另外通过 hot read region 看下分布
2)写热点排查:通过看QPS 监控中的 kv_commit 和 kv_prewrite 对比下这三台机器,另外通过 hot write region 看下分布
在 TiDB-Server 模块中的 Query Summary
tuyi
2019 年10 月 30 日 01:21
5
老师好,没找到kv_get 和 kv_coprocessor 是哪个指标,我把Query Summary都贴上来了
不懂就问
2019 年10 月 30 日 02:06
6
读写热点的确定可以参考这里排查下:TiDB 常见问题处理 - 热点 。另外集群的机器配置怎么样,是按照官方文档的要求部署的吗,看集群节点的分布,三台机器分别部署了 PD,TiKV 和 TiDB,这种方式是不建议使用的,TiKV 需要单独部署。
tuyi
2019 年10 月 30 日 02:06
7
hot read region 和hot write region 命令的结果我保存在文件中了hot.txt (5.5 KB)
tuyi
2019 年10 月 30 日 02:09
8
确实是三节点都部署了pd,kv和db,机器资源有限。
其他节点的负载都正常,就56,57load很高
tuyi
2019 年10 月 30 日 02:57
9
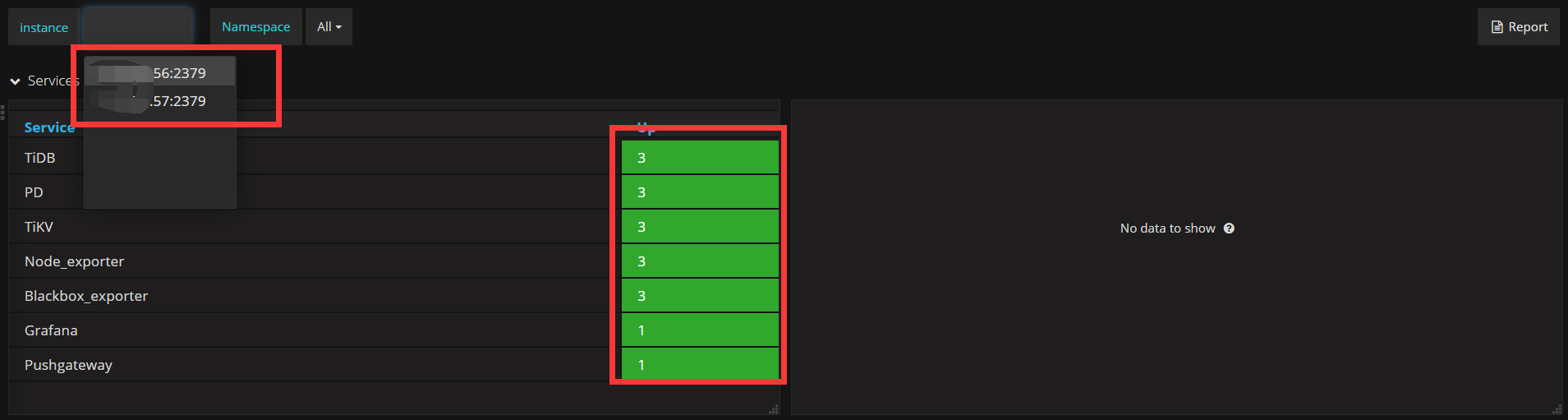
老师,我有3个节点,但是监控只能看到2个instance,如图:
这是正常的吗?还是哪里配置有问题啊?
tuyi
2019 年10 月 30 日 03:02
10
老师好,我参考 TiDB 常见问题处理 - 热点 ,执行了operator add split-region 1 --policy=scan 命令,没什么反应呢?
不懂就问
2019 年10 月 30 日 03:07
11
监控不展示现象可能是显示问题,再等等刷新下页面或者检查下部署时候 inventory 文件里面的配置。执行了 split-region 命令没反应是什么情况?是 region 1 是热点 region ,split 之后热点问题没有缓解吗?如果 region 1 所在节点的热点很明显,还可以考虑把 region 1 的 leader transfer 到其他非热点节点,然后再次执行 split 操作看下。
tuyi
2019 年10 月 30 日 03:14
12
执行了split-region后,用hot read命令发现还是region 1的状态还是和执行之前一样。是本来就不会变化吗?
不懂就问
2019 年10 月 30 日 03:41
13
split 之后看下现在监控,热点问题还有没有,按照之前的排查方式看下。
tuyi
2019 年10 月 30 日 04:00
14
很多指标没有3个节点没有明显的区别,发现一个有明显区别的就是如下图,这可以说明有热点吗?
不懂就问
2019 年10 月 30 日 06:28
15
看截图是一个节点还有读热点,现在需要找到读热点的 region ID。可以看下 138894那个 TiKV 节点的 tikv.log 信息,拿下所有的 region ID ,找出出现次数最多的 region ID,进行 split 或者 transfer 到另外两个节点。操作完看下调度是否正常:PD -> Scheduler 下面 leader 和 region 的调度是否变化。
tuyi
2019 年10 月 31 日 02:17
16
老师好,我找出tikv.log中出现次数最对的region ID,进行operator add split-region 282869 --policy=approximate操作,在PD → Scheduler 下面 leader 和 region的调度没有发生变化。
有几个问题:
1、operator add split-region完成后如何观察region是否已经分割完成
2、tikv.log中出现次数最多的是8000次左右,有20个出现8000次左右的region,这说明这些region都是热点数据吗?
operator执行完成可以通过operator show或者在pd日志中查看
麻烦看下Overview面板中TiKV中。leader和region的监控数据,看在几个tikv节点的分布是否均匀
tuyi
2019 年10 月 31 日 03:02
18
老师好,这是下Overview面板中TiKV中,leader和region的监控数据
还算均匀,leader会有波动,291417是新加的节点。我该如何确定是热点问题还是硬件资源问题呢?