[toc]
【 TiDB 使用环境】
版本:4.0.9
tidb+pd 共用
4台 4c 8G 300G SSD磁盘(4 tidb, 3 pd)
tikv
8台16c 64G SSD本地盘机器
【概述】
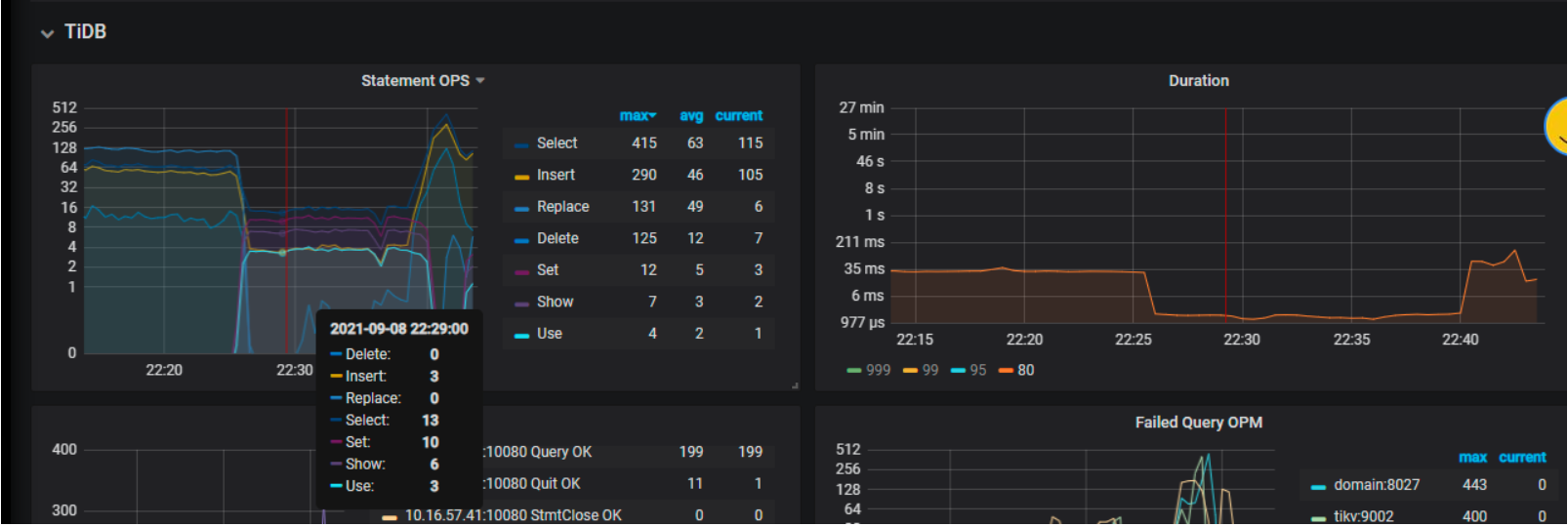
9.8号 22:36 有日志tidb集群tikv节点内存报警,进grafana监控中发现QPS都陡降(写入 读取请求量基本都降为0),持续实际15分钟左右
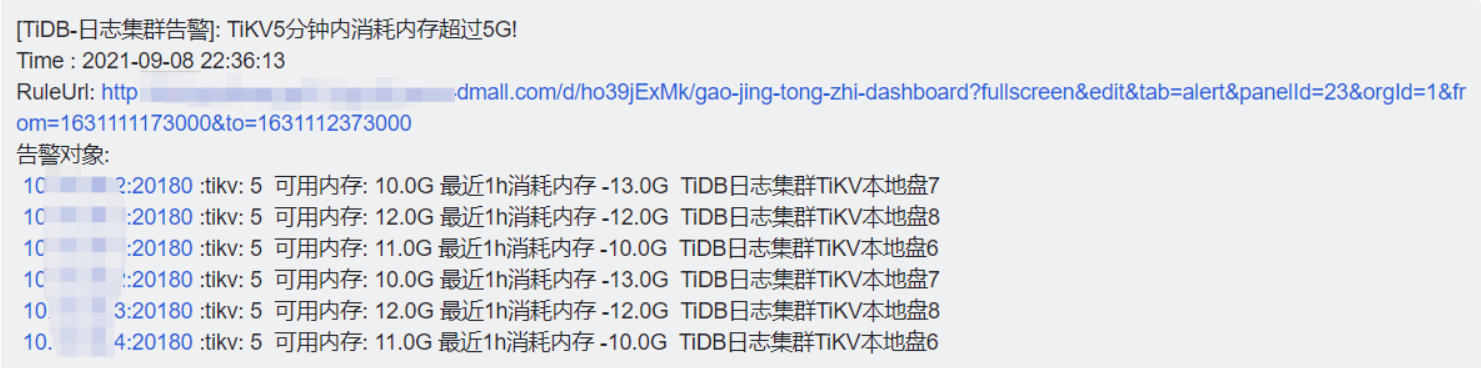
【背景】
没有做过操作,过15分钟左右自行恢复可用
【现象】
发现该时间段是在做空间回收,9.7号22:26做了清除(truncate xx_log 10T无用日志表)操作,truncate这日志表前10来分钟还下线过对这表的cdc同步,这表在上个月8月中旬就已经没有写数据了,业务应用方改成写分表了



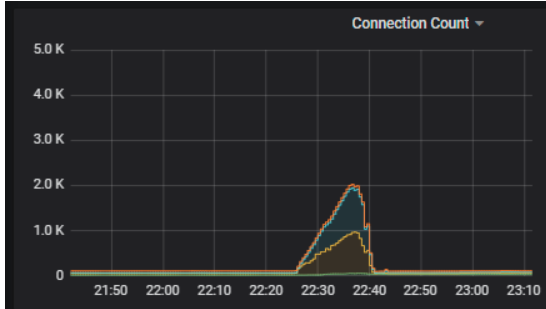
数据写入没成功重试导致4 tidb计算节点连接数暴涨(40左右->2k左右)
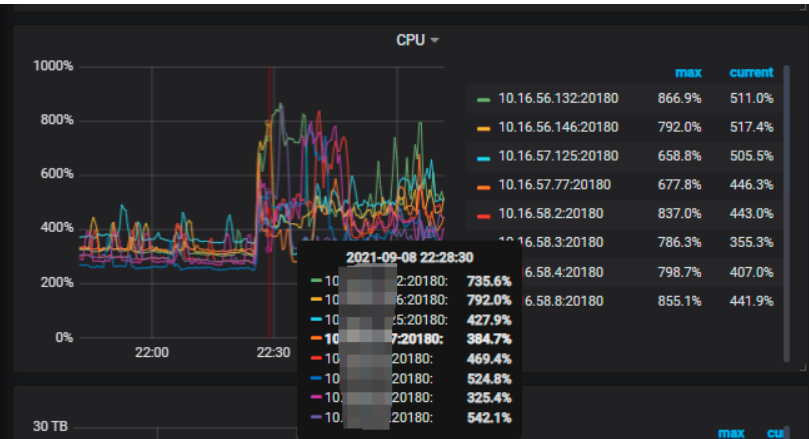
8 tikv存储节点cpu利用率上涨了1倍多
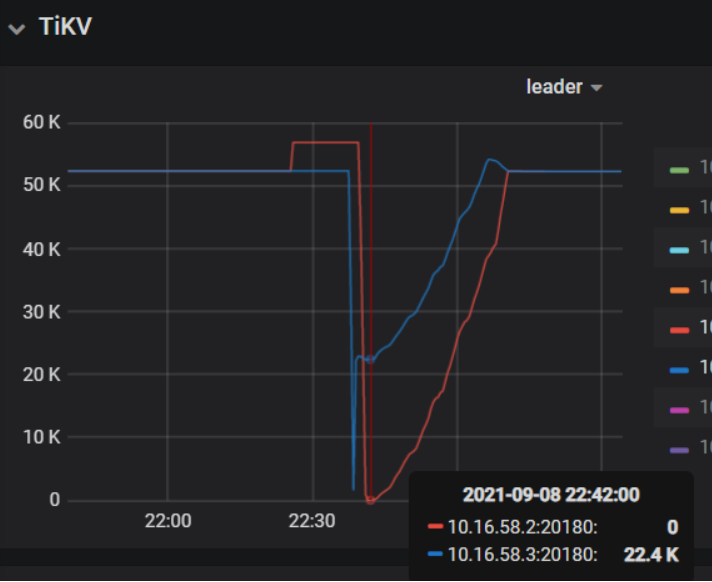
有2 tikv节点leader 在出现减少情况
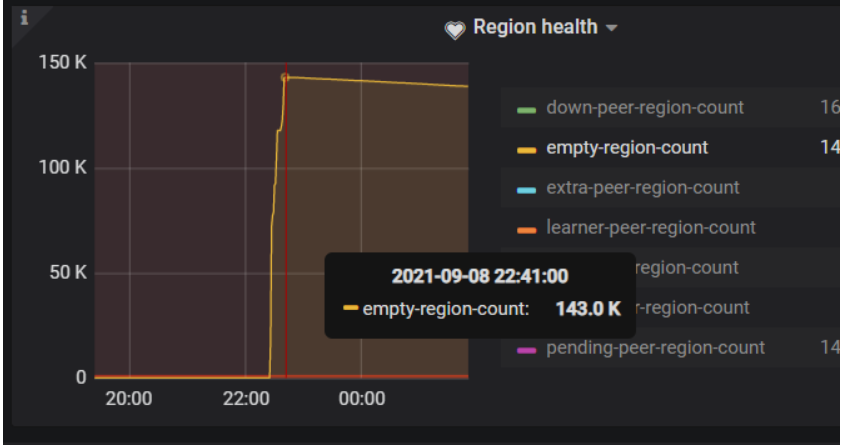
pd监控中看22:41空region数据涨到最对14.3W个(143000*96/1024/1024=13T,与24h前清除的表大小一致)
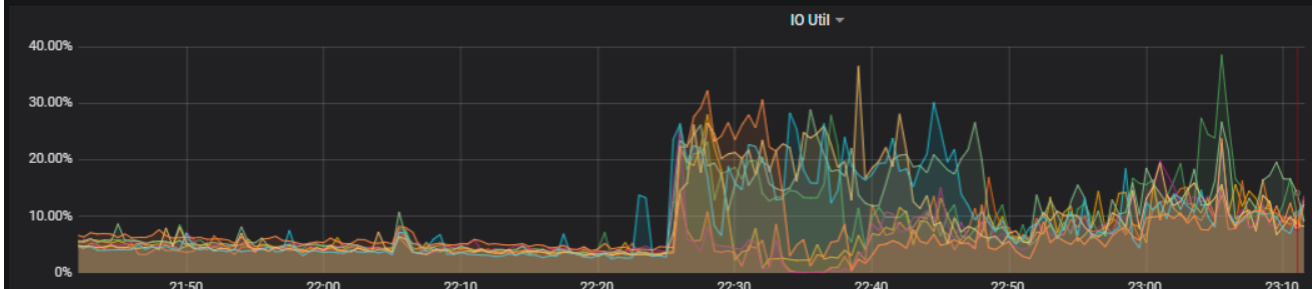
tikv节点io利用率上升
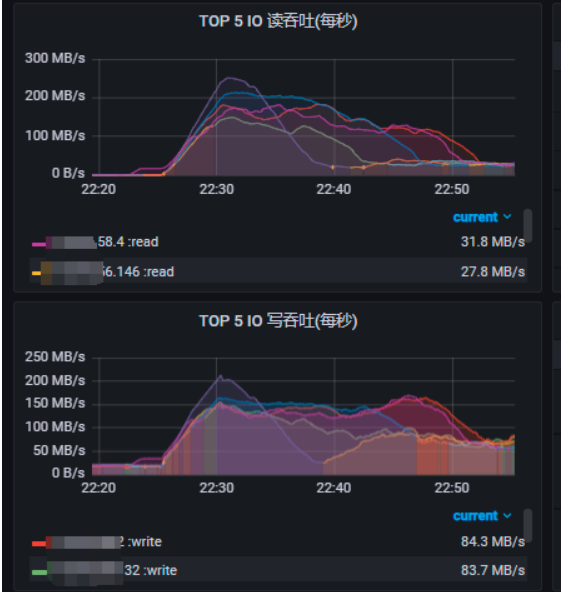
8 tikv存储节点 读吞吐100~250MB/s;写吞吐100~200MB/s
tidb 自身dashboard 热力图看对表有很大的写入量,没有读取量

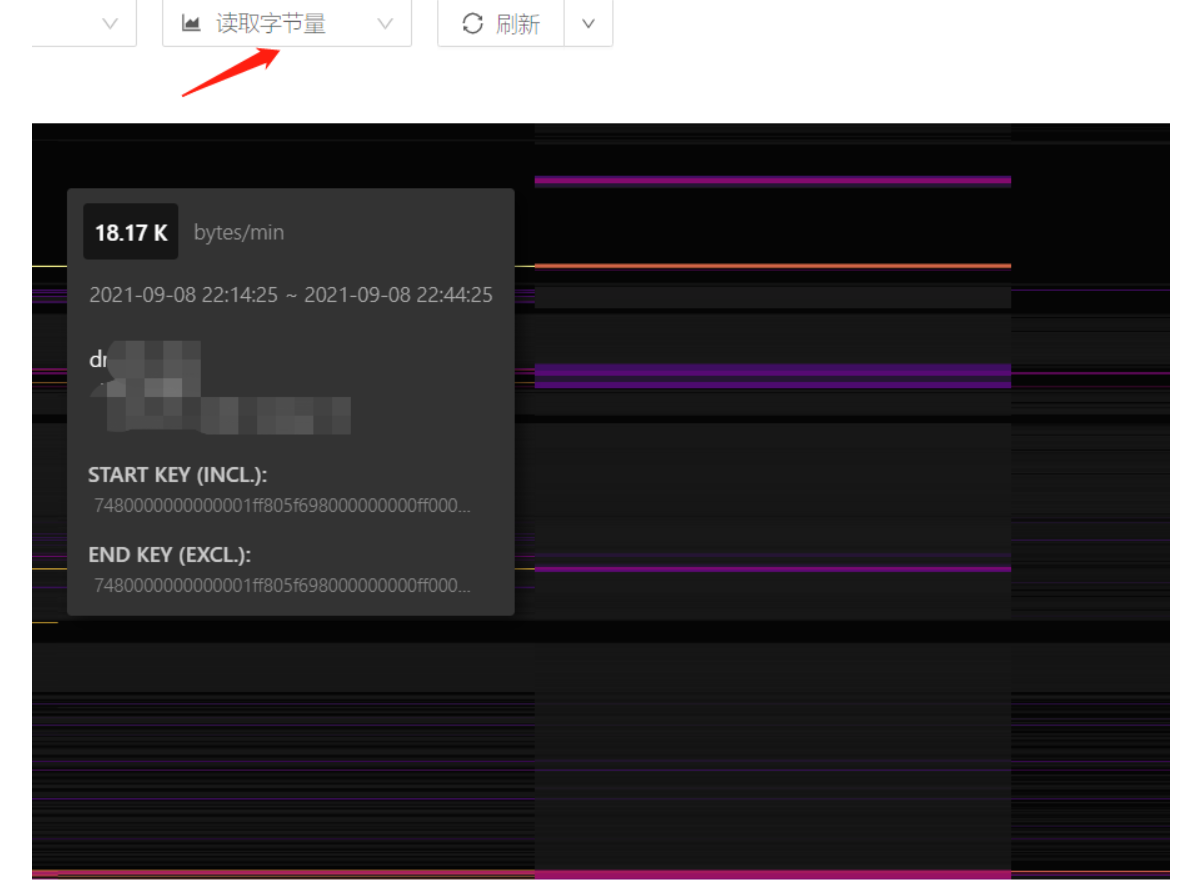
【业务影响】
业务应用写入日志数据失败,mysql->日志tidb集群同步(1 OLAP汇总业务库也在日志tidb集群)也失败,不可用持续15分钟左右

疑问
1、tidb delete、drop、truncate是10分钟(我们用的默认)会自动进行空间回收,这10T表回收空间为何在24h后才进行?
2、为啥自动回收空间会对tikv进行大量写入?但没有读取量(热力图上看没有读取,但实际tikv机器是有最高250MB/s吞吐的)?
3、大空间表清除是不是不适合用truncate,有推荐方式吗?
cluster_display.txt (3.3 KB) edit_config_2021-09-10_14-32-30.log (1.2 KB) leader_reduce_tikv_09_08_22_25~42.txt.tar.gz (5.2 MB) pd_leader_09_08_22_25~42.rar (3.0 MB)