llplmlyd
(Llplmlyd)
1
【 TiDB 使用环境】生产
【概述】 在tidb日志中发现大量的锁日志。之前没有打开general log,看不到对应的语句,需要分析对应时刻的SQL语句内容,考虑是否可以解析tidb 对应时刻的binlog来分析。
【背景】
在asktug上查询到有相关的解析文章,但是是只针对db-type=file类型的drainer,db-type=kafka的未涉及。尝试使用官方指引的工具 repo,无法进行解析。
【现象】
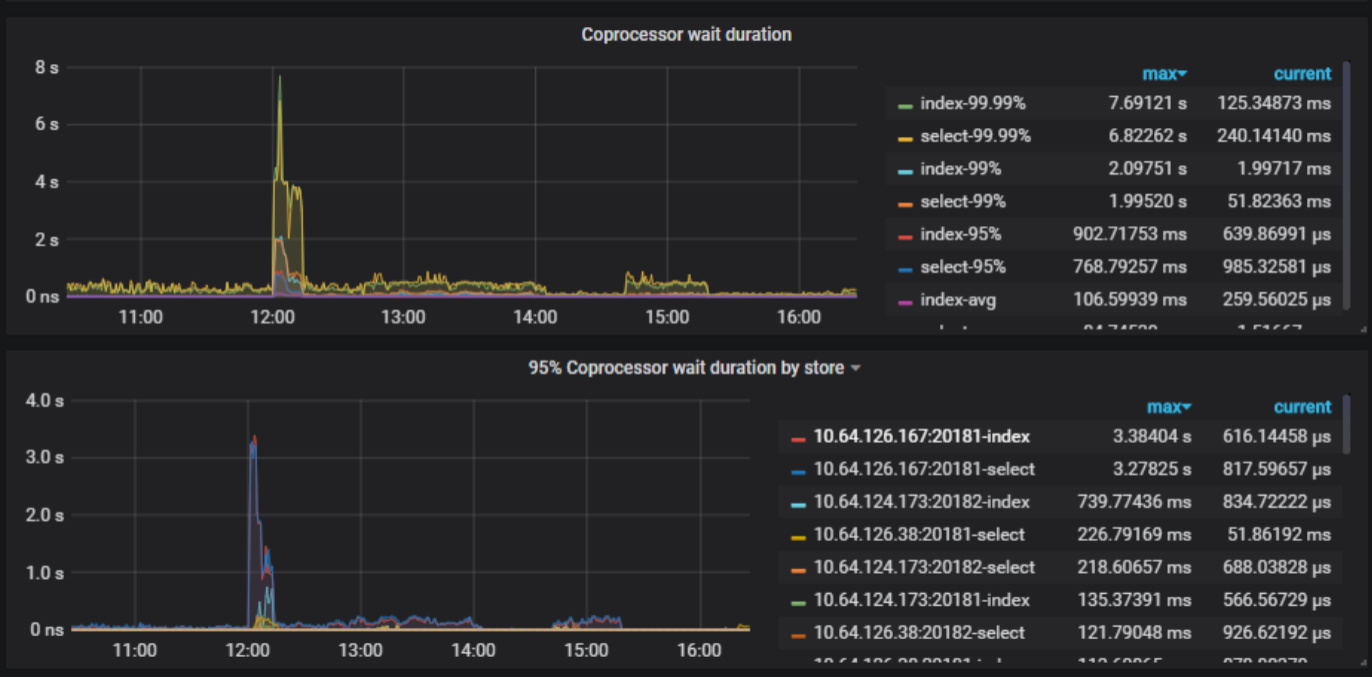
1.对应异常时间点出现了大量的下面的这种锁日志。
[2021/09/06 12:00:52.385 +08:00] [WARN] [endpoint.rs:454] [error-response] [err="locked primary_lock: 74800000000000015C5F69800000000000000104090EC1C16B09C00003800000001213C25F lock_version: 427530873017991394 key: 74800000000000015C5F72800000001213C25F lock_ttl: 3000 txn_size: 1"]
- tikv慢查询中的slow-query大多数是 wait time 大于Process time
Process_time: 45.129 Wait_time: 76.158 Backoff_time: 0.002 Request_count: 2245 Total_keys: 21908930 Process_keys: 21476772
3.duration大,lock多
4.执行计划不稳定,异常变化。
【问题】 查询大量超时。
1.需要定位锁冲突的原因,解析binlog 是一个方法,但是工具无法正常使用。
2.需要定位执行计划异常突变的原因,目前该版本有无解决办法?
【业务影响】 查询接口超时。
【TiDB 版本】 5.7.25-TiDB-v3.0.13
xfworld
(魔幻之翼)
2
锁信息,最好通过日志来查阅,binlog 是事务已经执行成功后形成的,锁则在执行过程中,这个无法判断
而且锁的话,一般都是写写冲突,你可以从业务层面分析一下,哪些数据可能会导致这个情况发生
tidb 5.1 以后的版本是支持锁的查阅的,如果有条件,可以在测试环境复盘一下
执行计划异常,大多数都是慢查询引起的,这个只能优化,尚无其他的办法
llplmlyd
(Llplmlyd)
3
这边有看到asktug上有相关锁的技术文章讲解了相关悲观锁的原理。
https://asktug.com/t/topic/33550
文章内提到以下内容:
目前业务库使用的是悲观锁。目前业务的一个锁冲突比较严重的表,据反馈,逻辑是
1.delete,根据索引去删除特定的行,
2.insert,插入一条新的行,
3.select,根据索引查询
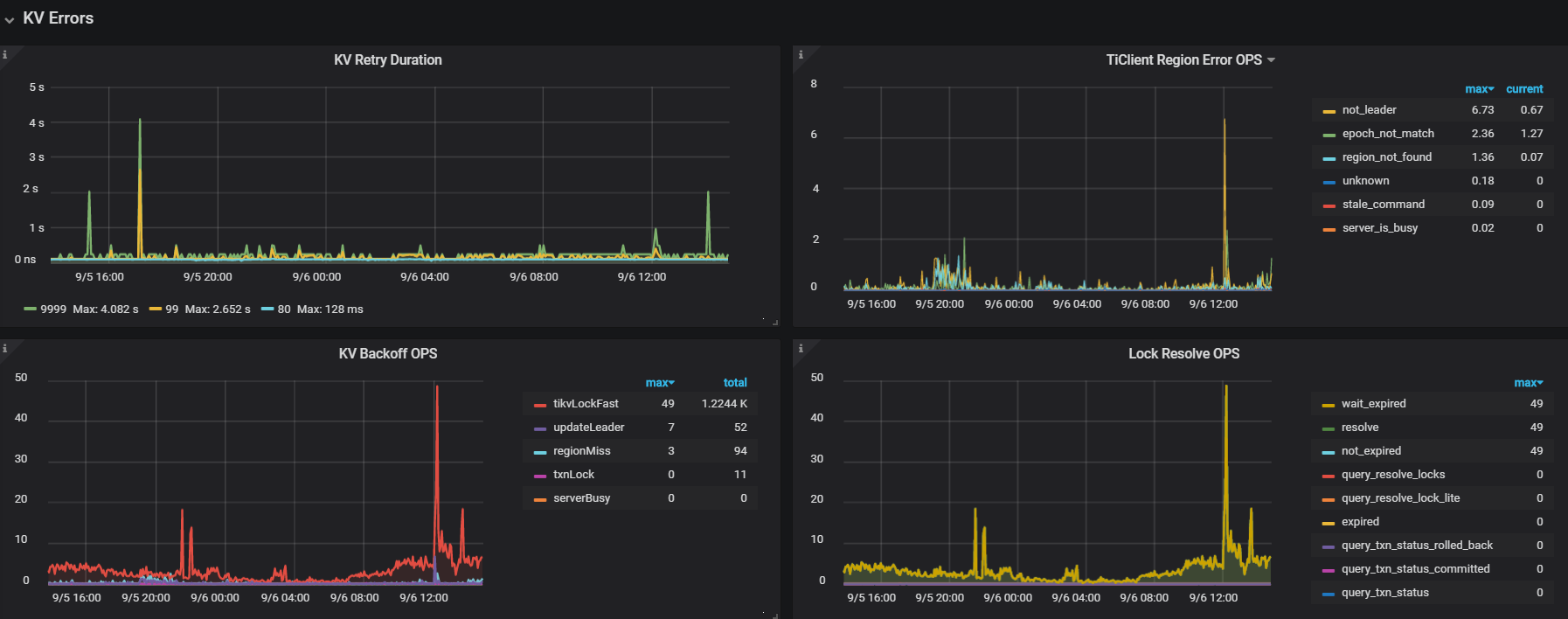
也看到相关文章说明了,【 tikvlockfast 】:读写冲突,读请求碰到还未提交的数据,需要等待其提交之后才能读。
1.那么我这个是属于读写冲突还是写写冲突应该如何判断?
2.“读写冲突比较严重,冲突严重则会大幅降低集群整体的效率”,这点应该如何理解?锁是针对一张表的rowid/唯一索引/region key,但是其他表的查询也会受到影响?
是因为读写冲突/写写冲突导致了TiKV CPU资源消耗导致了查询超时?
system
(system)
关闭
5
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。