为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
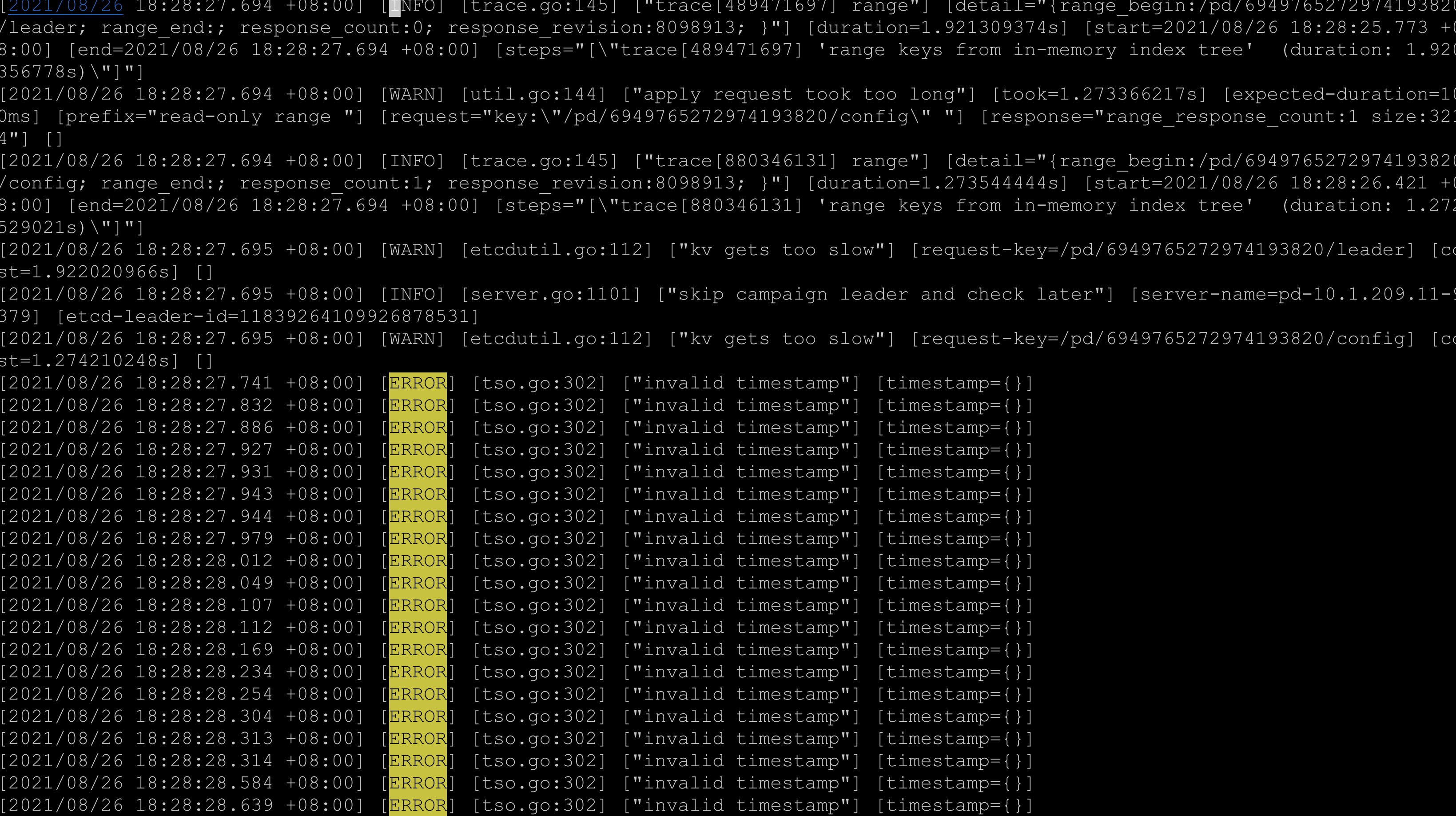
【概述】生产tidb 4.0.12 突然非常慢 然后 发现pd 和tikv 一直断自动重启 集群用不了
【现象】生产tidb 4.0.12 突然非常慢 然后 发现pd 和tikv 一直断自动重启 集群用不了
【业务影响】 生产用不了 P0 级别
【TiDB 版本】4.0.12
【附件】
- 相关日志 和 监控
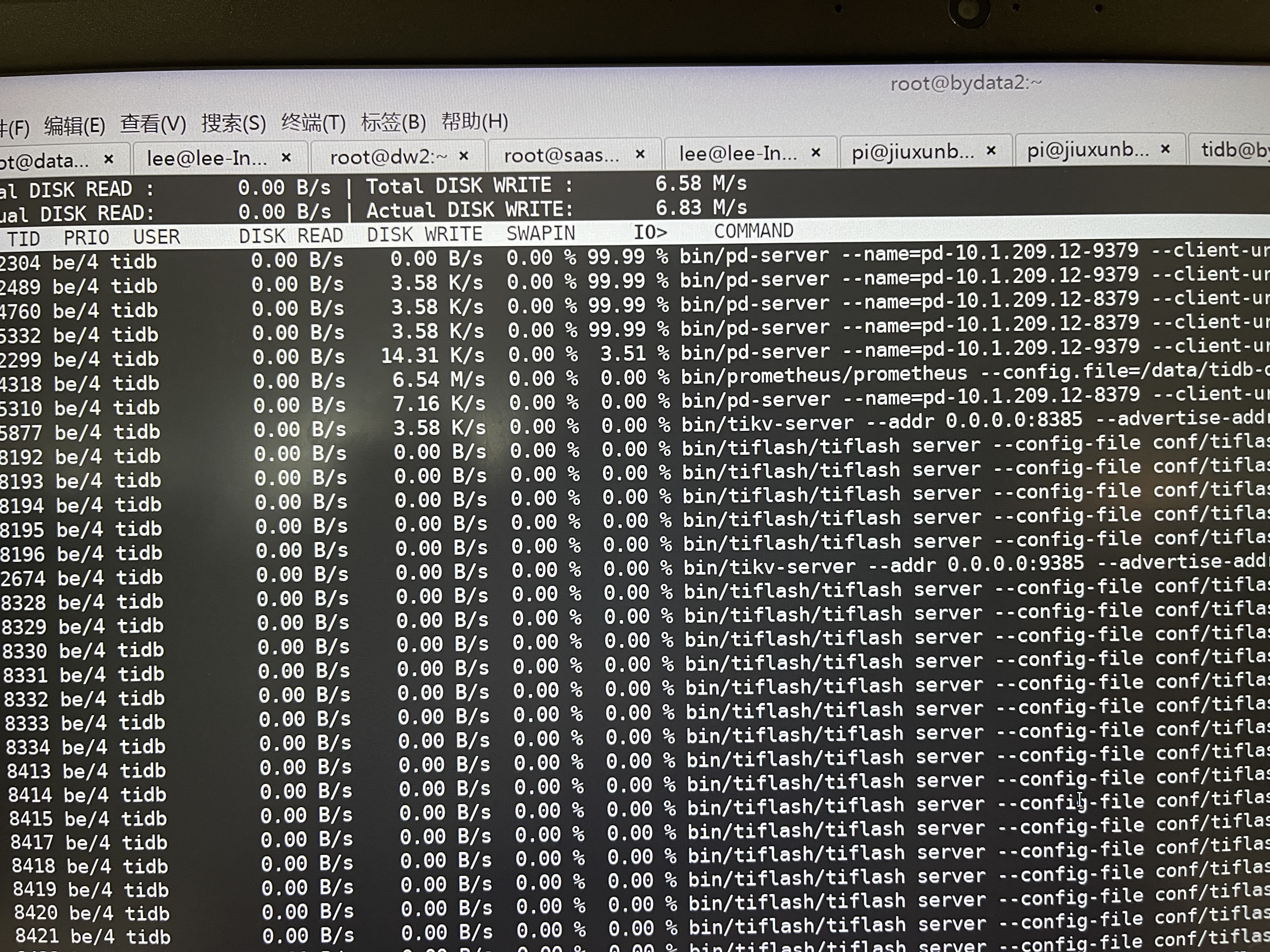
- TiUP Cluster Display 信息
[tidb@bydata1 ~]$ ~/.tiup/bin/tiup cluster display baiyao-v4
Starting component `cluster`: /home/tidb/.tiup/components/cluster/v1.5.5/tiup-cluster display baiyao-v4
Cluster type: tidb
Cluster name: baiyao-v4
Cluster version: v4.0.12
Deploy user: tidb
SSH type: builtin
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
10.1.209.13:9095 alertmanager 10.1.209.13 9095/9096 linux/x86_64 Up /data/tidb-data/alertmanager-9095 /data/tidb-deploy/alertmanager-9095
10.1.209.13:3030 grafana 10.1.209.13 3030 linux/x86_64 Down - /data/tidb-deploy/grafana-3030
10.1.209.11:9379 pd 10.1.209.11 9379/9380 linux/x86_64 Down /data/tidb-data/pd-9379 /data/tidb-deploy/pd-9379
10.1.209.12:9379 pd 10.1.209.12 9379/9380 linux/x86_64 Down /data/tidb-data/pd-9379 /data/tidb-deploy/pd-9379
10.1.209.13:9379 pd 10.1.209.13 9379/9380 linux/x86_64 Down /data/tidb-data/pd-9379 /data/tidb-deploy/pd-9379
10.1.209.13:9080 prometheus 10.1.209.13 9080 linux/x86_64 Up /data/tidb-data/prometheus-9080 /data/tidb-deploy/prometheus-9080
10.1.209.11:9383 tidb 10.1.209.11 9383/9384 linux/x86_64 Up - /data/tidb-deploy/tidb-9383
10.1.209.12:9383 tidb 10.1.209.12 9383/9384 linux/x86_64 Up - /data/tidb-deploy/tidb-9383
10.1.209.13:9383 tidb 10.1.209.13 9383/9384 linux/x86_64 Up - /data/tidb-deploy/tidb-9383
10.1.209.11:8000 tiflash 10.1.209.11 8000/7123/2930/20270/20192/7234 linux/x86_64 N/A /data/tidb-data/tiflash-8000 /data/tidb-deploy/tiflash-8000
10.1.209.12:8000 tiflash 10.1.209.12 8000/7123/2930/20270/20192/7234 linux/x86_64 N/A /data/tidb-data/tiflash-8000 /data/tidb-deploy/tiflash-8000
10.1.209.13:8000 tiflash 10.1.209.13 8000/7123/2930/20270/20192/7234 linux/x86_64 N/A /data/tidb-data/tiflash-8000 /data/tidb-deploy/tiflash-8000
10.1.209.11:9385 tikv 10.1.209.11 9385/9386 linux/x86_64 N/A /data/tidb-data/tikv-9385 /data/tidb-deploy/tikv-9385
10.1.209.12:9385 tikv 10.1.209.12 9385/9386 linux/x86_64 N/A /data/tidb-data/tikv-9385 /data/tidb-deploy/tikv-9385
10.1.209.13:9385 tikv 10.1.209.13 9385/9386 linux/x86_64 N/A /data/tidb-data/tikv-9385 /data/tidb-deploy/tikv-9385
Total nodes: 15
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控