为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
【系统版本 & kernel 版本 】
centos7
【TiDB 版本 】
3.0.4
【磁盘型号 】
1T 的云ssd磁盘
【集群节点分布 】
2个tidb节点,4个tikv节点,3个pd节点
【数据量 & region 数量 & 副本数 】
1亿,每个节点1.5k region
【问题描述(我做了什么) 】
这是一个新部署的测试集群,上面没有其他请求,就是在测试,
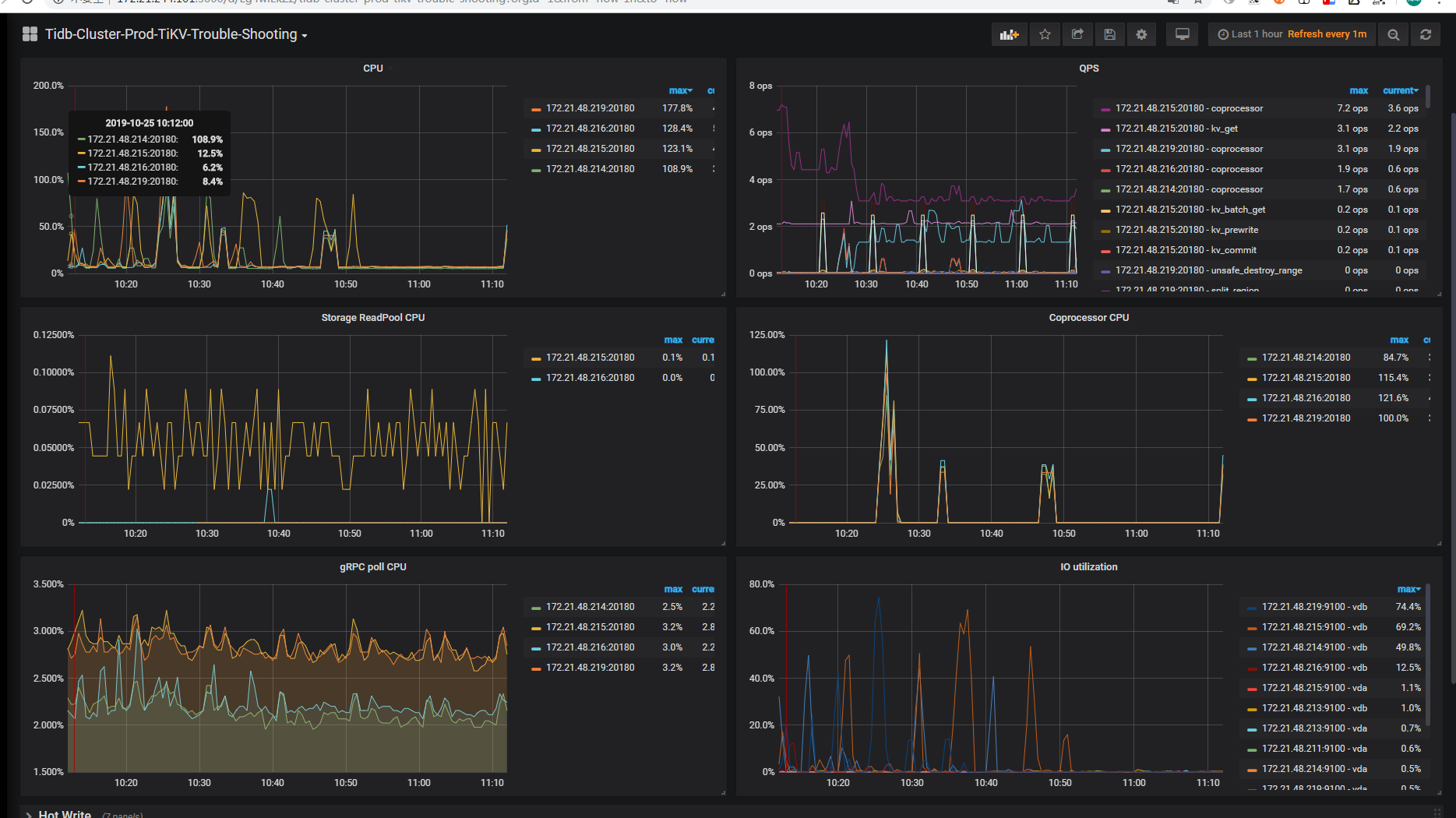
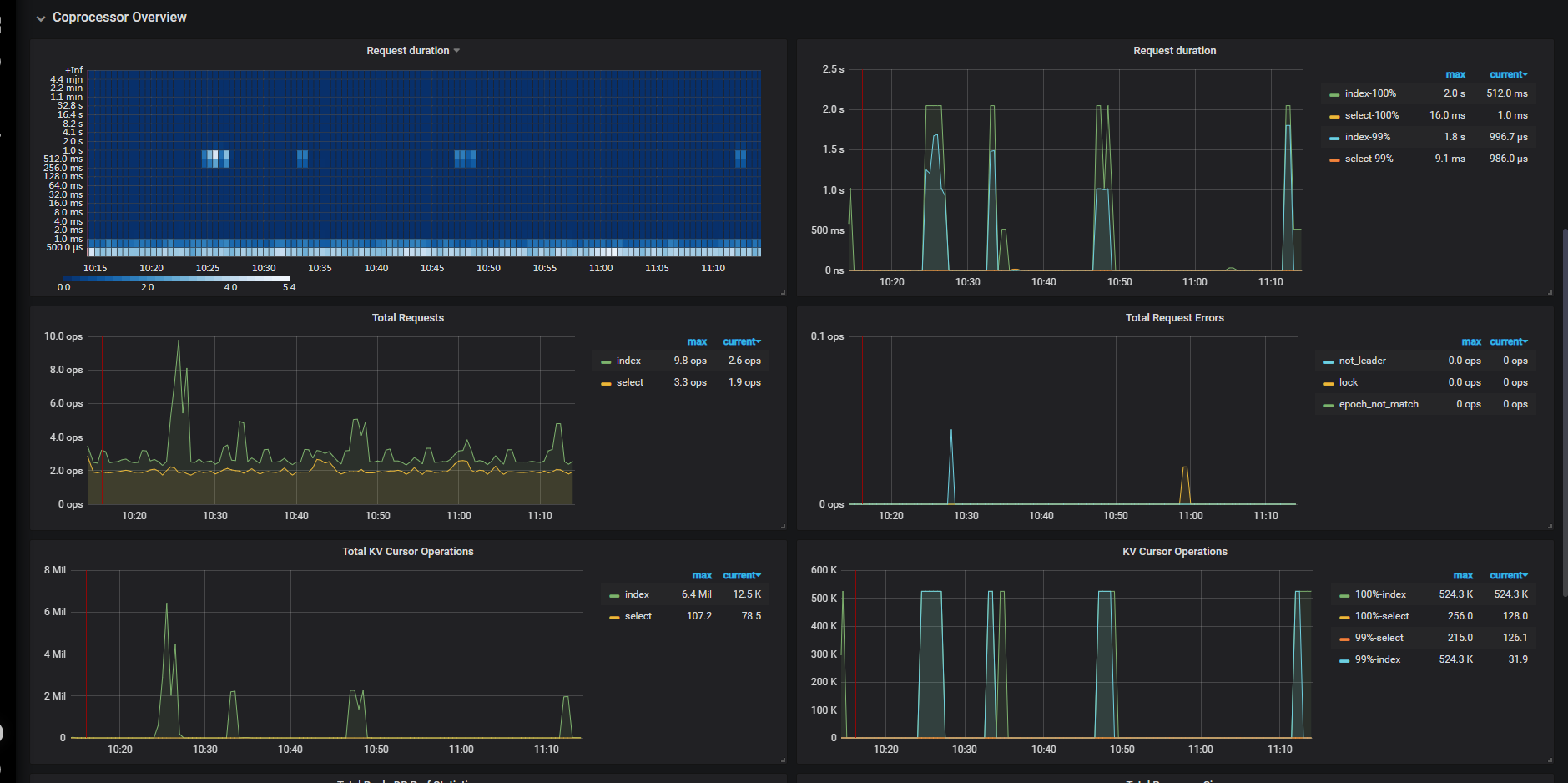
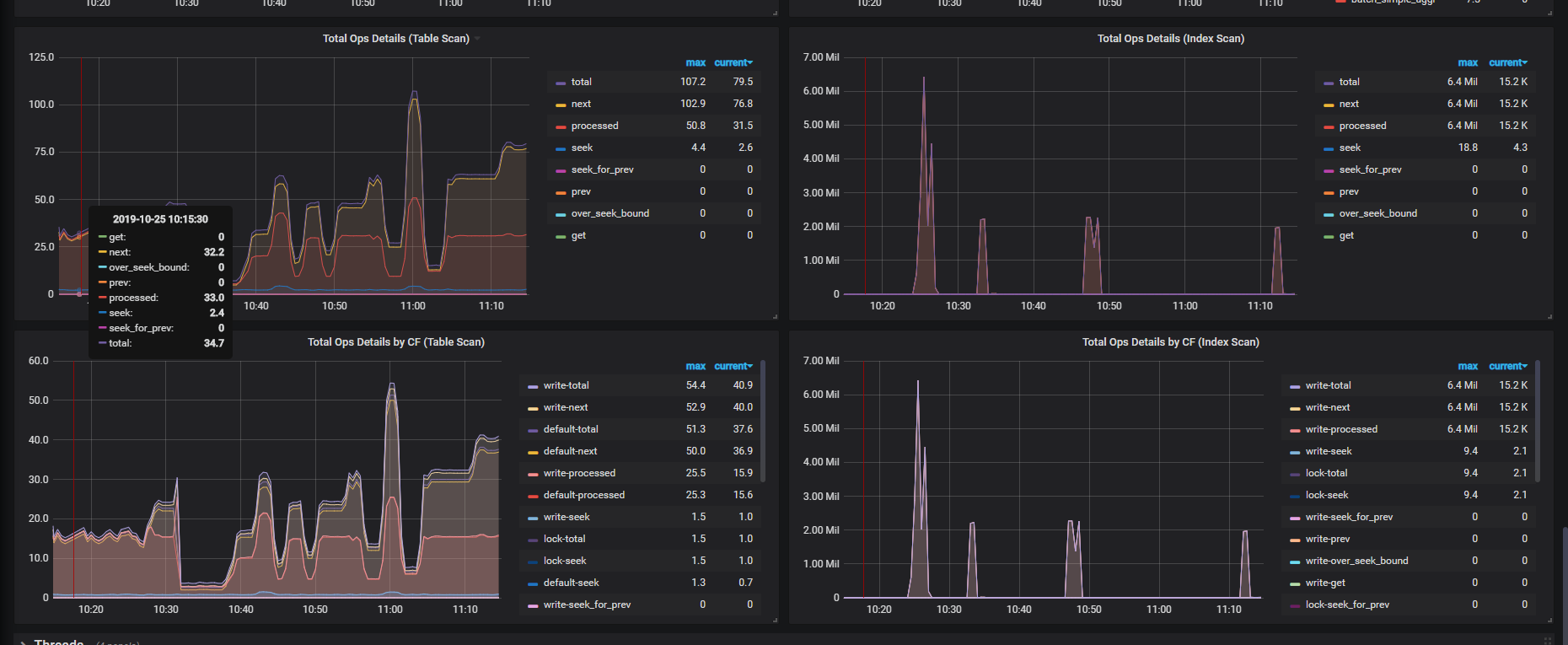
4台16C32G 的tikv节点,一张一亿的表,count(id)一下需要5s,集群默认安装
表结构
MySQL [sbtest]> desc sbtest1 ;
±------±----------±-----±-----±--------±---------------+
| Field | Type | Null | Key | Default | Extra |
±------±----------±-----±-----±--------±---------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| k | int(11) | NO | MUL | 0 | |
| c | char(120) | NO | | | |
| pad | char(60) | NO | | | |
±------±----------±-----±-----±--------±---------------+
慢查询
Time: 2019-10-25T10:47:50.227020873+08:00
Txn_start_ts: 412082940265889793
Conn_ID: 14892
Query_time: 4.735534417
Parse_time: 0.000135677
Compile_time: 0.000328002
Process_time: 64.186 Wait_time: 0.093 Request_count: 110 Total_keys: 100000110 Process_keys: 100000000
DB: sbtest
Index_names: [sbtest1:k_1]
Is_internal: false
Digest: 1f61de15725a7b1d1caba706b2743946e007f3fa9a29126864060d9de25a1693
Stats: sbtest1:412082675762593797
Num_cop_tasks: 110
Cop_proc_avg: 0.58350909 Cop_proc_p90: 0.837 Cop_proc_max: 1.045 Cop_proc_addr: 172.21.48.216:20160
Cop_wait_avg: 0.000845454 Cop_wait_p90: 0.001 Cop_wait_max: 0.002 Cop_wait_addr: 172.21.48.214:20160
Mem_max: 186
Prepared: false
Has_more_results: false
Succ: true
select count(id) from sbtest1;
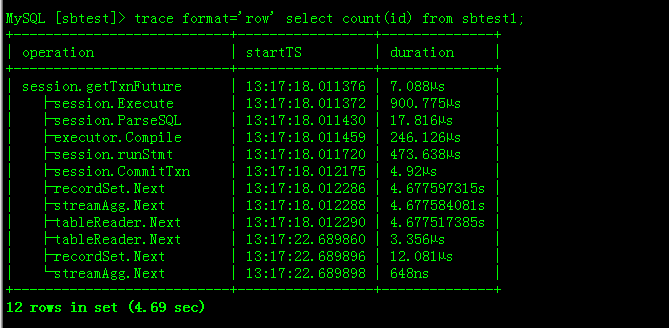
trace format='row' select count(id) from sbtest1;
这个结果发下
可以看到大量的时间消耗是在 recordset.next 。就是在扫索引,扫索引,也是要完整扫过5亿行,目前还没有做一些比较特殊的优化操作。5s 现在比较正常,后续我们会持续优化索引。
system
2022 年10 月 31 日 19:04
8
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。