为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
- 【系统版本 & kernel 版本】
- 【TiDB 版本】
- 【磁盘型号】
- 【集群节点分布】
- 【数据量 & region 数量 & 副本数】数据量40亿行左右
- 【问题描述(我做了什么)】一个数据量很大的表,如何快速添加新的索引?
- 【关键词】大数据量表;新增索引
为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
1、建议在业务低峰期执行添加索引的操作。
2、适当调整下述参数:
tidb_ddl_reorg_batch_size
tidb_ddl_reorg_worker_cnt
tidb_ddl_reorg_priority
tidb_ddl_reorg_worker_cnt 同时并发工作的worker数量 默认值 16
tidb_ddl_reorg_batch_size 默认值1024
tidb_ddl_reorg_priority 优先级 可设置为 PRIORITY_LOW/PRIORITY_NORMAL/PRIORITY_HIGH
请问下 前两个数值的设定有没有建议值,还是需要自己做下尝试?
一般情况下 3个 tidb server ,建议 16个 worker ,batch_size 建议:4096 。具体的参数需要根据当前系统的负载情况进行调整。可以参考下述链接
https://pingcap.com/docs-cn/v3.0/benchmark/add-index-with-load/#线上负载与-add-index-相互影响测试
好的,感谢。
你好,请问下执行过程中如果失败了,如连接中断,出现索引没建成功(show index没有),再建时却提示已存在该索引,这种情况该怎么处理。
是这样的,如果发起了 create index 的操作,等待客户端返回 success 后,终端可以正常关闭。这个 create index 的 job 会添加到 add index 的队列中,此时可以通过 admin show ddl 相关命令查看该 job 的执行情况,添加索引需要回填数据。如果是 2.1 及以上版本,那么普通的 ddl 和 index 做了拆分,具体需要看你的版本号到底是什么。如果要停止弄个 ddl job 可以使用 cancel 。
1、查询 ddl 状态的相关命令如下:
https://pingcap.com/docs-cn/v2.1/reference/sql/statements/admin/#admin-语句
2、tidb online ddl 的介绍:
https://github.com/ngaut/builddatabase/blob/master/f1/schema-change-implement.md
你是 add index 的操作没有执行完,然后就 提交了很多个 drop 这个 index 的操作吗?
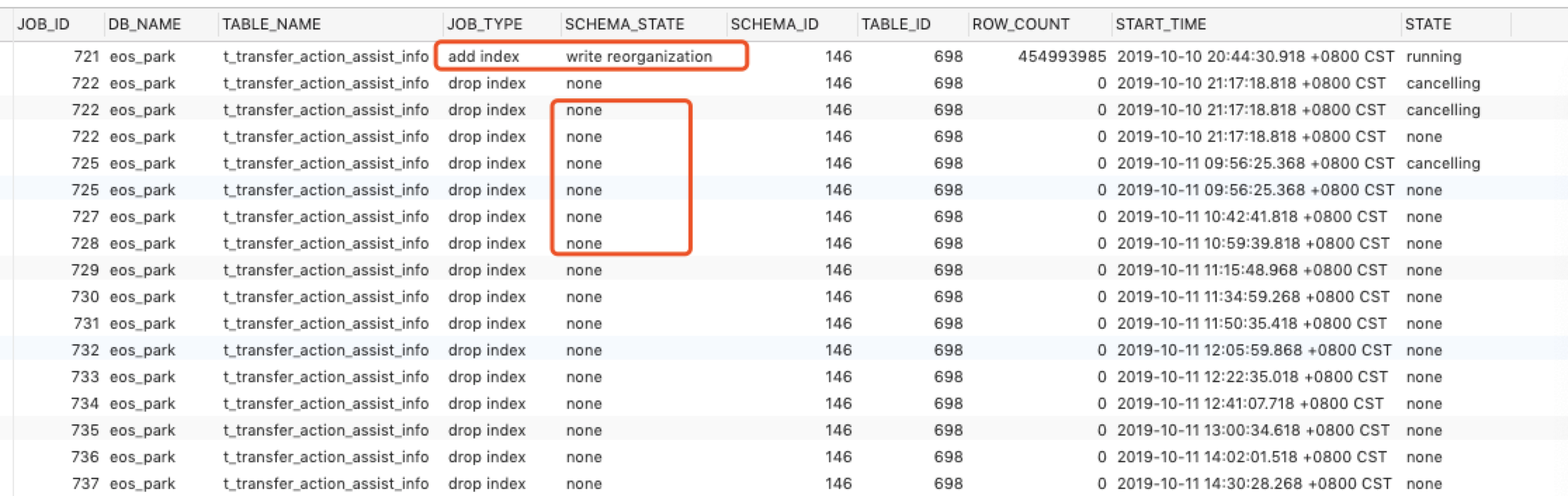
1、add index 的并且 job id 是 721 的正在执行,可以定时刷新下,schema_state 状态是 write reorg 表示正在回写数据
2、drop index 的其他 job ,状态是 schema_state 是 none 表示:
但是这些 drop index 的 job 的 state 的状态是:
表示,这些 drop index 的 job 已经在队里中等待执行,或者等待取消。
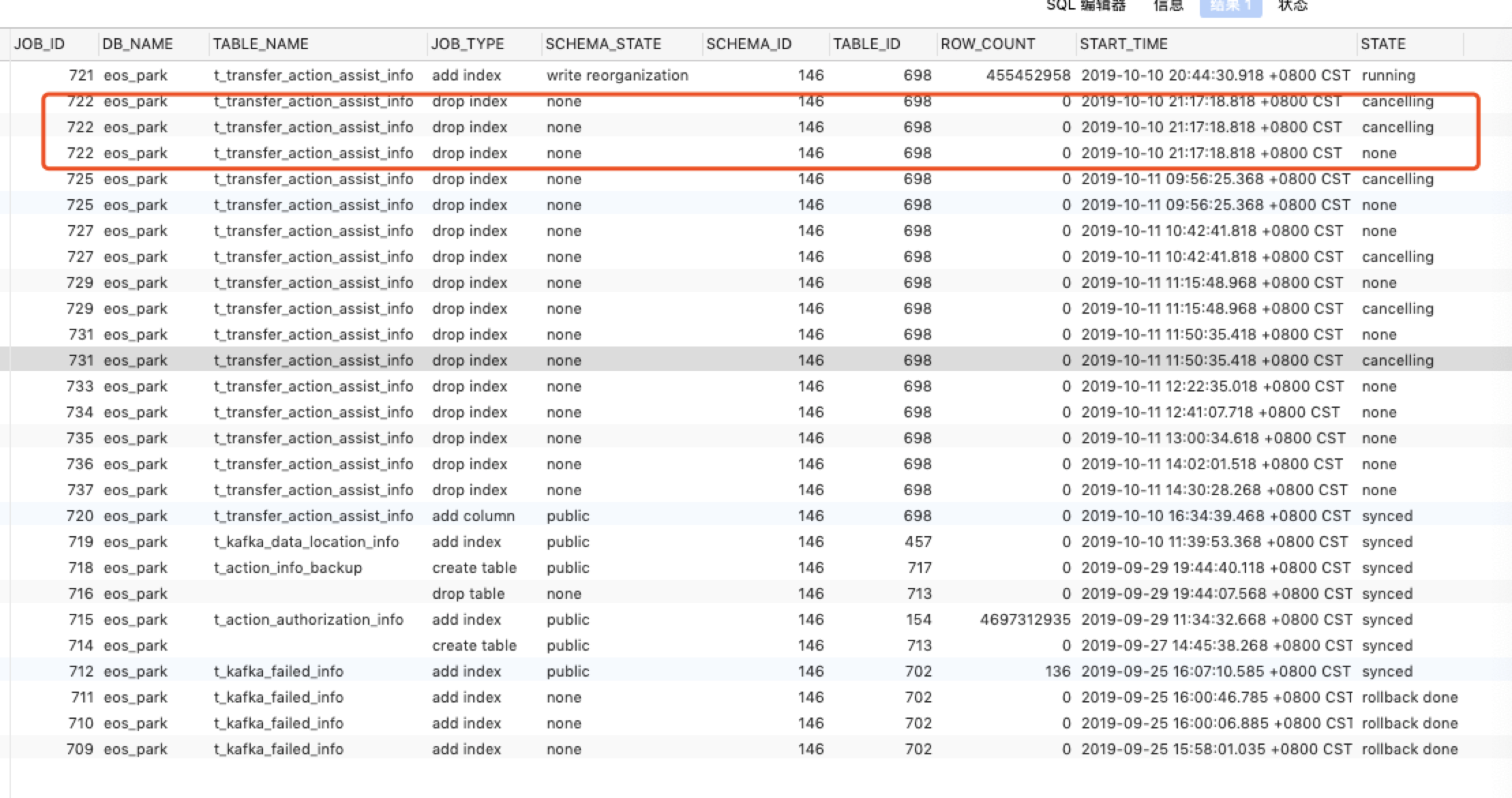
之前 add index 时连接中断了,以为执行失败了,后面想再 add index 时,提示已存在,就试着执行 drop index。 那我需要使用 ADMIN CANCEL DDL JOBS 手动取消这些 drop index 的任务是吗? 这个 add index 速度很慢,因为之前没有调整参数(tidb_ddl_reorg_worker_cnt、tidb_ddl_reorg_batch_size、tidb_ddl_reorg_priority),如果现在调整会有效果吗?
1、建议把后面 drop index 的操作都 cancel掉,有些 任务已经在队列中等待执行了,如果不 cancel,add index 的操作执行完会接着执行 drop 的操作的。
2、现在调整参数对已经运行的任务不生效。
好的,谢谢!![]()
命令 ADMIN SHOW DDL,返回的是 ID:722, Type:drop index, State:none, SchemaState:none, SchemaID:146, TableID:698, RowCount:0, ArgLen:0, start time: 2019-10-10 21:17:18.818 +0800 CST, Err:, ErrCount:0, SnapshotVersion:0
ID:721, Type:add index, State:running, SchemaState:write reorganization, SchemaID:146, TableID:698, RowCount:455656946, ArgLen:0, start time: 2019-10-10 20:44:30.918 +0800 CST, Err:[kv:9007]Write conflict, txnStartTS=411771139330670593, conflictStartTS=411754809751764993, conflictCommitTS=0, key={tableID=698, handle=391317290} primary={tableID=698, indexID=5, indexValues={0, 391317246, }} [try again later], ErrCount:313, SnapshotVersion:411752587989614594
这边是不是冲突了?
你那边用的是什么版本?版本信息发下
怎么查看版本信息呢?
1、从 tidb.log 可以看
2、数据库中 select version() 也可以看
版本:5.7.25-TiDB-v3.0.0
我这边将之前的任务取消了,然后重建,速度快了很多,应该是add index 和 drop index冲突导致速度慢了。
问下,你用的客户端是?navicat(这个显示有问题,job id 位数显示有问题)?可以用 mysql client 执行试一下。
“Write conflict” 是写冲突了。
客户端是navicat,还有这个问题!!我看下。。。。
现在是正常了!!!![]()