dba-kit
(张天师)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
TiDB v5.1.0,Aliyun ECS自建SSD集群,包含2台tidb,3台tipd,3台tikv。主要存的是用户资产信息,用了聚簇索引,主键是『账户 + 交易账号』,在数据分布上已经被打散了。使用场景分两类:
- 批量写入:每10min检查基金是否有净值更新,如果有更新,会触发批量更新持有对应基金的交易账号信息
- OLTP查询:查询都是以「账户」为纬度查询。
【现象】 业务和数据库现象
业务使用场景:每天都会清空前一天的数据,也就是每天对应的表都会从空表增加。在19点后会启动Spark Job,接收基金净值更新的kafka Topic,每10min更新一次TiDB中的多个表,在写入时候负载比较高。
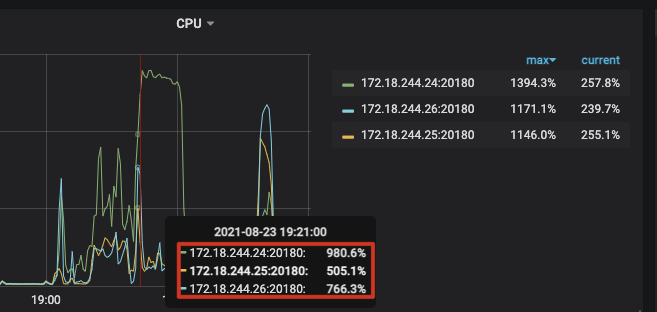
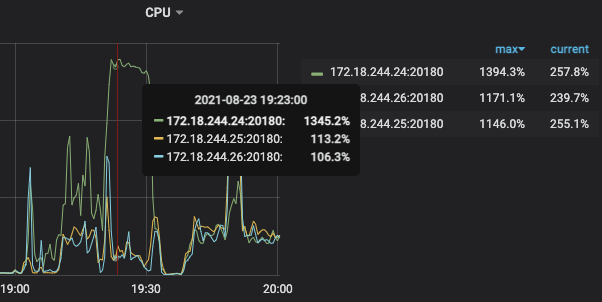
现象:在19:20更新资产时,三台TiKV负载都比较高(分别为5/7/9,虽然有些不均匀但还可以接受),但是批量更新JOB结束后,有一台TiKV节点负载开始飙升(16C64G机器,用了13C,剩下两个节点只用了1、2个核),期间落到该节点的查询都一直被卡死,没有响应。
【问题排查】 当前遇到的问题
根据tikv.log日志信息,当时每分钟的slow-query日志输出达到1k多甚至2k:
通过详细看故障阶段的日志,剔除掉正常的日志报错,发现有两种异常的日志:
173 KvService response batch commands fail
1747 Coprocessor task terminated due to exceeding the deadline
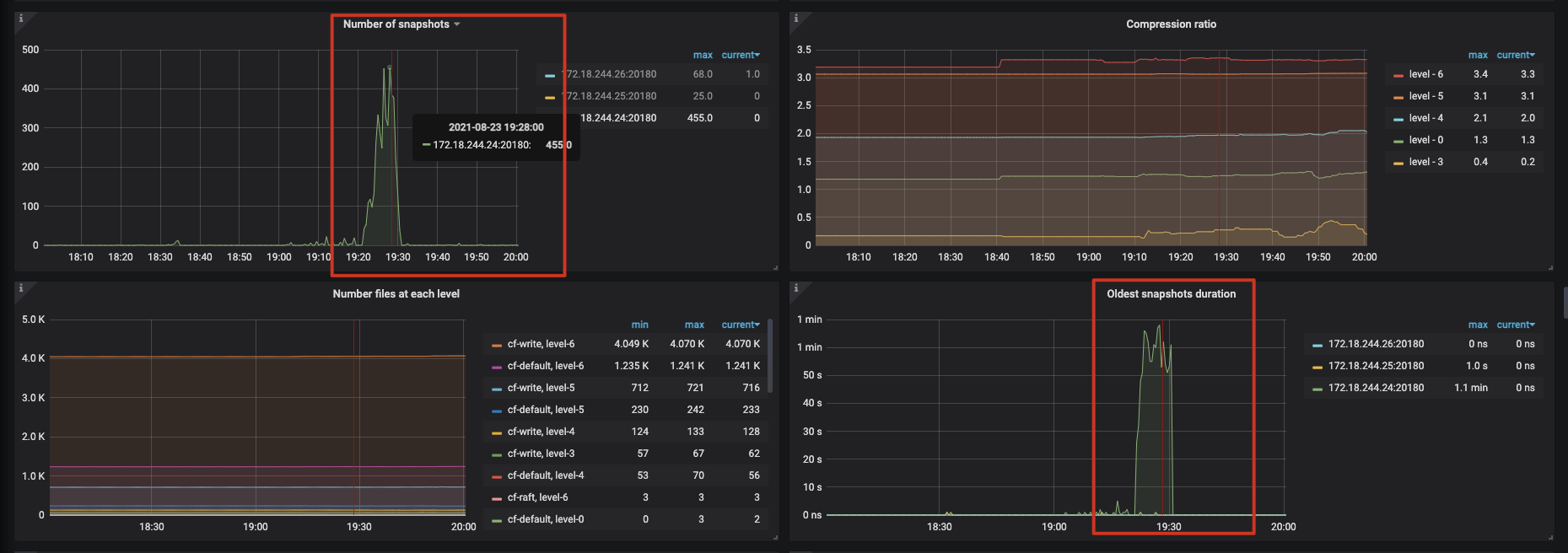
看监控的话,在故障节点多个指标的Duration都比正常时大了很多。
不过TiKV-Detail ==> RocksDB-kv ==> Number of Snapshots指标,正常时候应该是0的,故障节点达到了400多,不清楚是否有关联
现在怀疑这些都是因为表迅速扩大,导致Region热点出现,但是业务在这种场景下已经跑了有一个月了,没有出现过问题,现在也是正常的。希望能找出当时故障的最终原因,达到避免的目的。
xfworld
(魔幻之翼)
2
这个数据是采用什么方式清空的?是 标准的delete,还是drop?
xfworld
(魔幻之翼)
5
慢查询需要持续优化,或者限制最大运行时间,不过 回收机制也需要等待,那么慢查询所占用的资源,不会及时释放,这个一定要注意!
xfworld
(魔幻之翼)
7
大量的数据 GC,慢查询, 等等都会导致这个负载高的问题 
要一点点的排查…
LSMTree 的特性,决定了Delete 释放的时间,所以我在问你,旧的数据是怎么清理的
dba-kit
(张天师)
8
至于我提到的「每天会清理旧表数据」,是想说明:这个表是从0开始增长的,所以前期会遇到「写热点」的问题,某个TiKV节点负载在批量写入时候负载高,这个是可以理解的。难以解释的是,为什么这个节点会在批量写入结束后,持续出现负载高的情况。
至于处理方式,现在每天下午15-16点之间的,会将旧表RENAME成备份表,然后用CREATE LIKE方式创建新表。之后在晚上19点开始,接收基金的净值更新消息,批量更新数据。OLTP查询是全天都会有,晚上20-22点是高峰期。出问题时是19:20 ~ 19:30之间,这个时候查询请求很少的
xfworld
(魔幻之翼)
10
写入的排查思路:
- 排除热点问题
- 排除硬件性能问题
可以参考下指南:
https://asktug.com/t/topic/95104
1 个赞
dba-kit
(张天师)
12
这两个报错信息代表什么含义,你知道么?官方文档里没找到对应的说明。。。
还有就是TiKV-Detail ==> RocksDB-kv ==> Number of Snapshots这个监控里的Snapshot是指什么也不清楚。这个值突然飙升代表什么含义?
官方把Snapshot在不同场景有不同含义,我找的有两种:
- 在隔离级别里:RC是基于Snapshot隔离的,每个事务创建时候,都会创建一个Snapshot
- 在TiKV 源码解析系列文章(十)Snapshot 的发送和接收 | PingCAP中:Snapshot是指状态机的快照
xfworld
(魔幻之翼)
14
Snapshots 就是指某个时间点数据的快照,
数据的版本越多,涉及的事务越多的话,快照必须越多
因为需要支持到隔离级别
system
(system)
关闭
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。