作者介绍
杨牧,京东云数据库产品经理,总体负责京东云的数据库产品在云上的规划、落地以及整个京东集团数据库上云的相关工作。
本文根据京东云数据库产品经理杨牧在【PingCAP DevCon 2021】上的演讲整理而成。
- 视频回顾: 【PingCAP DevCon 2021】京东云 杨牧 - 从 MySQL 到 Cloud TiDB:京东物流在云数据库上的选择和实战_哔哩哔哩_bilibili
- 讲义下载: 京东云-杨牧-从 MySQL 到 Cloud TiDB.pdf (2.0 MB)
本文介绍了京东物流从 MySQL 到 Cloud-TiDB 的应用实践及未来规划。 TiDB 不仅解决了京东物流在 MySQL 架构下遗留的“快、慢、烦”三大问题,更带来了意外的惊喜:按两年为周期计算,IT 成本将下降到原来的 1/3 。TiDB 在部分业务系统的应用带来的成本改善和效率提升,已经成为集团内部的标杆案例。预计到 2021 年年底,京东集团内部使用 TiDB 的规模会再增长 100%。
压力山大 —— 业务的困难与挑战
随着京东业务发展的快速发展,数据量的增长也越来越快,带来了几个方面的挑战: 第一,快。 业务增长快、数据量增长快,系统频繁需要扩容,每次扩容都比较麻烦,从资源申请的流程到风险评估,预案的准备以及跟业务方的沟通等,给我们的架构师带来了不少麻烦。 第二, 慢。 随着数据量的增加以及业务复杂度的上涨,SQL 查询的效率变得越来越低,研发需要持续不断地对系统进行优化,这给研发也造成了比较大的压力。 第三,烦。 为了解决数据量的问题,不少系统采用了分库分表的方式,但是这种架构运维比较繁琐而且容易出错,这个时候,运维踩雷可能性就急剧地上升了。

随着业务和数据量的不断增长,给架构师、研发和运维都带来了各种各样的挑战,我们也探索了一些业界主流的方案,比如说像分库分表。分库分表通常只适用于一些比较简单的业务,对业务的侵入性以及改造成本比较高,使用场景也比较受限,比如难以支撑跨分片的查询,一些复杂 SQL 不支持等,而且大型集群的运维比较困难。
在一些分析和查询的场景,我们还尝试使用了 ElasticSearch 和 ClickHouse。这两种方案都需要把数据从交易库 MySQL 里面同步过来,还需要对业务进行代码改造。除此之外,还存在一些其他的限制,例如 ClickHouse 不支持事务且并发低等。

柳暗花明 —— 打造一款适合 Cloud 的 TiDB
京东云联合集团内部各个业务团队的专家进行了调研和分析,最后我们和 PingCAP 展开了深度合作,联合推出了云上的分布式数据库—— Cloud-TiDB,提供京东云上的 TiDB 服务。京东云上的 TiDB 服务主要有以下三个特点: 一键部署、一键扩容和多维监控告警 。
- 一键部署是指在创建集群的时候,可以自定义节点的规格、节点的数目,同时也支持 TiFlash,还可以在线的升级数据库版本,这些操作都是通过鼠标的点击,很轻易地完成。
- 一键扩容是说无论是 TiDB、TiKV 还是 TiFlash 节点,均可在线的水平增加节点的数目,提升整个集群的容量和处理能力,而且整个扩容过程,几乎是无感知的,对业务毫无影响。
- 多维监控告警是指我们将云上的云监控,和 TiDB 的 Grafana 和 Dashboard 有机地结合,进一步帮助我们的开发、运维人员更好地使用 TiDB。
总而言之,对于用户来说就只管使用,其他的都可以交给京东云来处理。
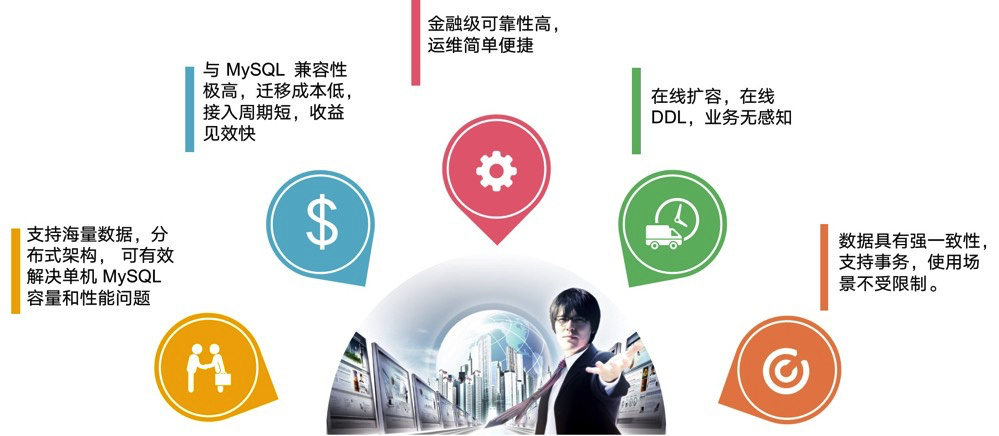
我们选择 Cloud-TiDB 作为京东一些海量业务的支撑,主要是基于以下几方面考虑:
- TiDB 采用的分布式架构支撑海量数据扩展,可以有效地解决单机 MySQL 容量和性能的瓶颈问题。
- 最重要的一点, TiDB 与 MySQL 兼容性非常好,迁移成本很低 ,接入周期短,收益见效快。
- TiDB 提供金融级可靠性,运维简单便捷。
- 支持在线扩容和在线 DDL,业务几乎无感知。
- 数据具有强一致性,支持事务,使用场景不受限制。
意外惊喜 —— Cloud-TiDB 的方案和收益
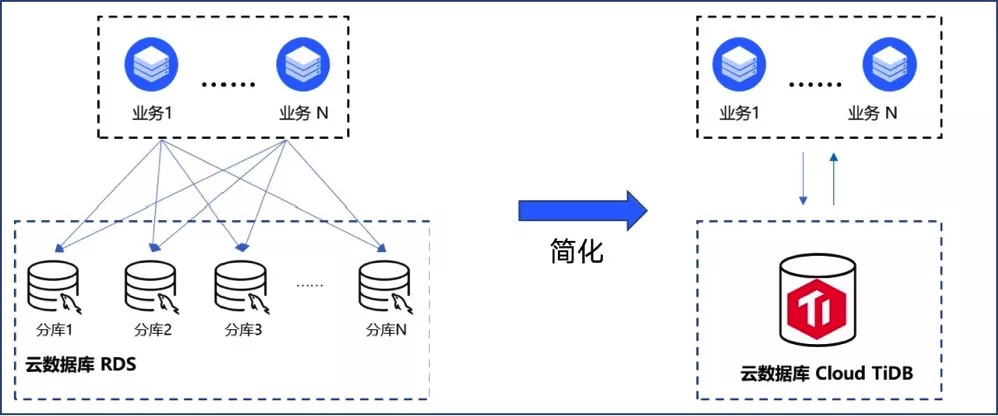
下面我们来看一下京东实际的一个案例,这个是物流业务跟一些费用相关的系统,这个系统的数据量比较大,我们能够看到它的几个主表的数量分别是 20 亿、50 亿和 100 亿,系统上线了半年后数据翻倍到了 220 亿。因为数据量比较大,所以在最开始的时候,采用的就是基于 MySQL 的分库分表架构。在运行了一段时间之后,分库分表的架构就遇到了我们所说过的一些问题,比方说一些复杂的 SQL 不支持,一些跨分片统计报表难于实现等等。经过调研、测试之后,我们决定把这个数据库从 MySQL 切换到 TiDB。
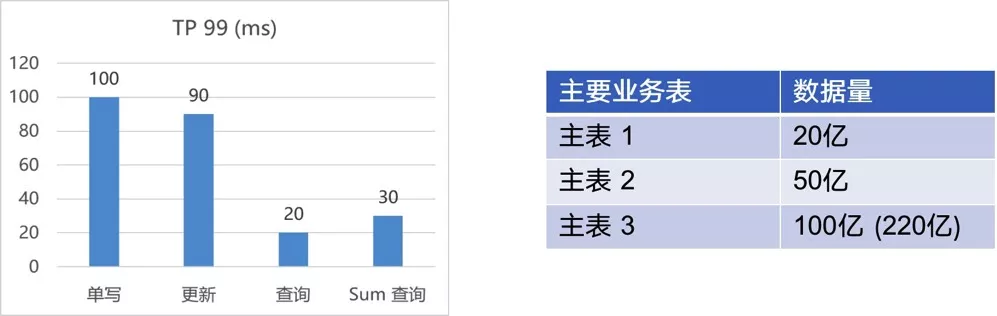
迁到 TiDB 之后,整体的性能表现比较优秀,写入和更新的效率在 100 毫秒左右,查询和 Sum 查询只有 20-30 毫秒 。大家可以猜一下,一个几百亿数据量的系统从 MySQL 迁移到 TiDB,需要修改多少代码?实际业务代码是零修改的,系统只是更换了 JDBC 连接的用户名和密码,真正地实现了从 MySQL 到 TiDB 的零代码修改和无缝迁移。TiDB 和 MySQL 良好的兼容性让我们在使用 TiDB 的时候,试错、测试和迁移的成本比较低,而且收益的周期也非常短,见效快。
除此之外,迁移到 TiDB 还给了我们一个意外的惊喜, 我们做了一个评估, 如果按两年的周期计算,TiDB 的使用成本仅为 MySQL 的 37% 。为什么这么说?因为 TiDB 对数据的压缩率非常好,这是当时测试的结果,在 MySQL 里的数据占到 10.8 T,迁移到 TiDB 之后只有 3.2 T,而且这 3.2 T 还是三副本的总数据量。所以,MySQL 与 TiDB 的空间使用比是 3.4:1。
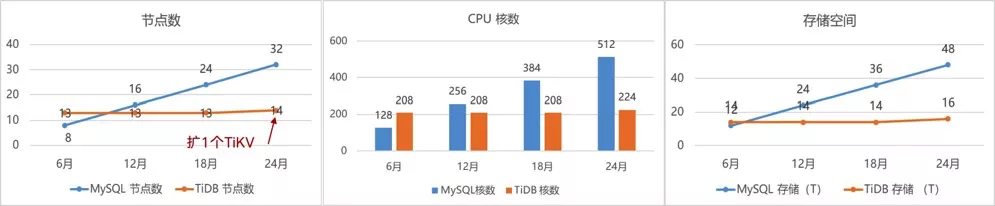
原先的架构是一个四分片的 MySQL 集群,按照目前数据增长的速度,大概是每六个月就要进行扩容,每次要扩四套主备实例。TiDB 按实际需要扩容就行了。可以看到在第 24 个月的时候,MySQL 有 32 个节点,TiDB 只有 14 个节点,使用的 CPU 核数 MySQL 是 512 个,而 TiDB 只要 200 多个,不到 MySQL 的一半。在存储空间上,TiDB 更是只有 MySQL 的 1/3。所以说,TiDB 带给我们的惊喜就是帮助我们整个业务部门极大地降低了 IT 的投入成本。

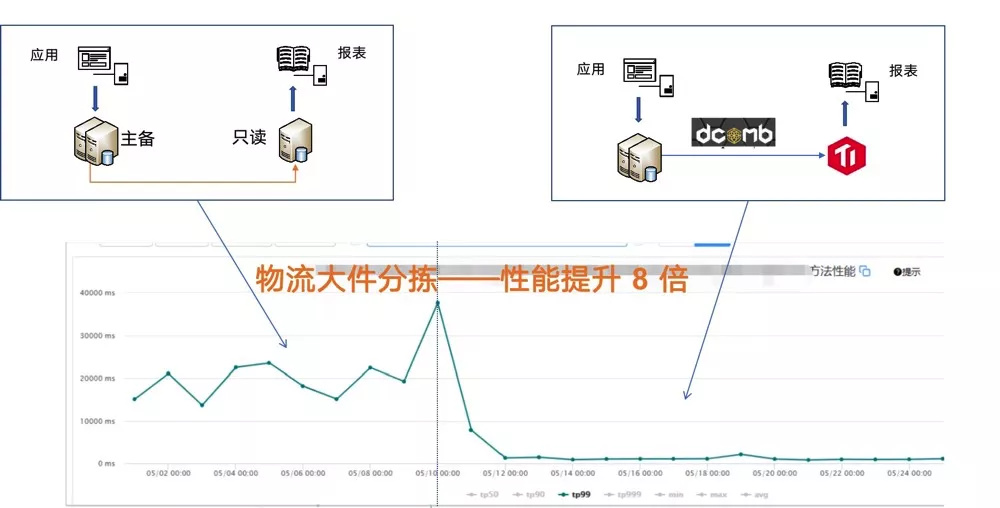
第二个案例是京东物流大件分拣的业务系统。以前这个系统的一些实时看板和核心报表都是跑在 MySQL 上。随着数据量增加,而且 SQL 比较复杂,报表和看板的性能比较低,用户的体验不是特别好。当时我们也尝试过分库分表的方式,但是这种方式对代码侵入性比较大,架构需要大幅调整,风险比较高。
最后,我们选择了 TiDB 支撑业务的实时看板和核心报表。在 MySQL 和 TiDB 之间,用我们自研的蜂巢系统进行数据的准实时同步。从右下角的监控图可以看到,从 MySQL 迁移到 TiDB 后,总共数百个指标,整体性能提升了 8 倍。
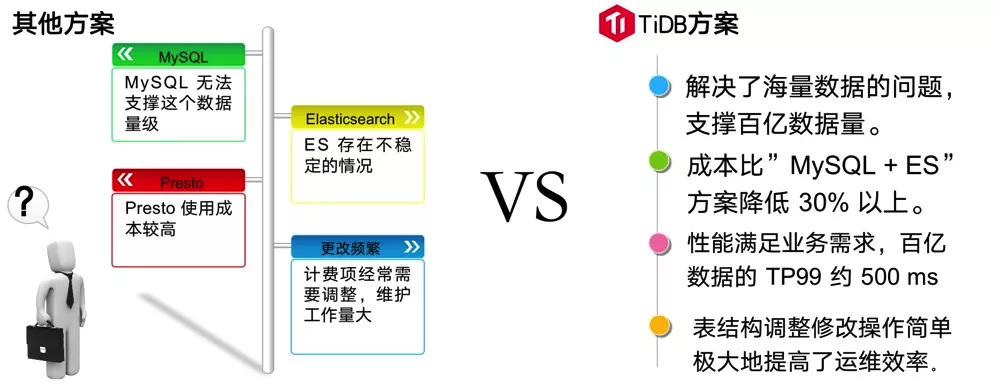
第三个系统是京东物流的运单计提明细系统,主要是记录部分运单的明细数据,每天的数据增长大概在千万级别,单表最大记录接近 200 亿条。很显然,这样一个数据量用 MySQL 是很难支撑的。我们曾经尝试使用 Presto,其性能和容量都还可以,但对我们来说使用成本比较高,所以后来使用 ElasticSearch 来做查询工作。ElasticSearch 存在着不稳定的情况,由于业务的特性,例如计费项经常需要调整意味着表结构的变化,所以维护的工作量很大。
把这个业务系统迁移到 TiDB 之后,首先解决了海量数据的问题,TiDB 可以毫无压力地支撑百亿级的数据量。其次, TiDB 成本比起以前使用的 MySQL + ElasticSearch 方案降低了 30% 。此外,TiDB 性能也满足业务的要求,从百亿的单表里面查询出业务数据的 TP99 大概在 500 毫秒左右。还有一点比较重要,TiDB 整个表结构的调整修改操作非常简单,给我们带来了运维敏捷和成本下降。
京东物流使用 TiDB 的收益主要体现在成本、效率和体验三大方面。TiDB 帮助我们降低了 IT 系统的投入成本和运营成本,成本降低之后,就意味着这个系统的架构师有了成绩,业务性能的提升可以极大地改善用户体验。研发也不再需要成天优化系统了,可以早点回家去过自己的二人世界了。运维效率得到了极大的提升,运维同学就不再需要经常熬夜去支持系统运维了,可以把精力投入到其他更有价值的业务中去。不熬夜之后,我们的头发也可以少掉几根。
目前京东集团在云上已经使用了数十套 TiDB 系统,支撑了集团多个 0 级业务系统,0 级业务系统是指如果这个系统发生故障超过 30 分钟就要上报到 CEO,所以说 0 级业务系统属于京东的关键业务系统。 这几十套 TiDB 系统都经过了京东 618 大促的严格考验,期间没有发生过任何故障,性能也很平稳 。同时,TiDB 在部分业务系统的应用带来的成本改善和效率提升,已经成为集团内部的标杆案例。我们预计到 2021 年年底,京东集团内部使用 TiDB 的规模会再增长 100%,总 CPU 核数将超过 10000 核。
除了 TiDB 之外,市面上还有一些其他的分布式数据库,我们在当初选型的时候,也做了一些对比。从集群规模来看,TiDB 可以支持数百个节点,而其他的分布式数据库大都是 1 主 15 从,共支持 16 个节点,从节点规模上来说就差了一个数量级。从读写的扩展上看,TiDB 是一个多活架构,其所有对外提供服务的 TiDB 节点都是可以读可以写的,都是对等的,而其他产品多数只有主节点可以写,从节点只能提供读的能力,写还是和以前 MySQL 一样受限于单机能力,没法得到提升。从数据容量上来看,TiDB 可以达到 PB 级的数据量,而其他数据库都是在 100 TB 左右。除此之外,TiDB 支持实时数据分析,而其他的数据库不具备这个能力。TiDB 的备份效率会稍低一些,希望 TiDB 今后在这方面有更多的提升。
最重要的是 TiDB 是一个开源的产品,不会被某个云厂商所绑定 ,基于 TiDB 用户可以很轻松地实施多云战略,可以把 TiDB 部署在任何一个云上,不受到任何的绑定。如果你用得不爽了,直接换个云就行了,不像以前很多企业都是用 Oracle 数据库,现在想换也换不了,非常痛苦。

蒸蒸日上——未来展望和经验分享
接下来分享一下我们在 TiDB 使用过程当中的一些实践经验。
第一个是 查询计划的改变 ,这是一个比较常见的情况,以前在 MySQL 有一些比较好的 SQL,在 TiDB 里面使用性能有一些问题,需要进行逐个地分析和优化,通过加一些索引以及查询计划,最后都可以得到解决。第二个就是 自增主键容易引起热点数据 ,可以通过使用 AUTO-RANDOM 来解决。第三,在 TiDB 的默认配置参数中,在大数据量下新建索引的时候,tidb_ddl_reorg_worker_cnt、 tidb_ddl_reorg_batch_size 两个参数配置比较小,我们可以调大一些,在重建索引的时候,性能可以得到比较大的改善。第四, TiDB 默认是严格区分大小写,而 MySQL 默认是不区分的 ,我们只能在数据库集群初始化的时候进行配置,后面修改不了。最后就是 SQL Mode,如果在 MySQL 中使用了一些特殊的 SQL Mode,迁移到 TiDB 中的时候,有些 SQL 可能没法正常执行,只需查看当前使用的 MySQL 的 SQL Mode 并直接替换就可以。
最后,结合我们的使用经验谈谈对 TiDB 的期望。首先,我们希望单个 TiKV 可支持更大的存储空间,目前官方给的建议是 2T,希望可以提升到 4T 或者是 5T,可以进一步降低 TiDB 的使用成本。第二,提升备份效率,TiDB 集群的数据量通常比较大,所以备份效率比较重要,希望 TiDB 今后能够通过其他一些方式,比如支持通过硬盘快照的方式进行备份和恢复。第三,希望 TiDB 能够支持一些外部表的读写,例如 OSS、HDFS、NFS等,用户可以把历史数据放到这些低成本的存储中,实现数据的冷热分层,降低使用成本。第四,进一步提升 TiCDC 的性能和稳定性,有些同步任务可以通过接口和 K8s Job 进行配置,希望通过在生产环境实现主从集群的方式,进一步扩大 TiDB 在京东内部的使用场景和规模。
我们希望 PingCAP 和 TiDB 能够发展得越来越好,成为国产数据库的一面旗帜,同时也欢迎大家来京东云试用 Cloud-TiDB。