为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
ID Role Host
10.10.10.207:9093 alertmanager 10.10.10.207
10.10.10.207:3000 grafana 10.10.10.207
10.10.10.207:2379 pd 10.10.10.207
10.10.10.208:2379 pd 10.10.10.208
10.10.10.209:2379 pd 10.10.10.209
10.10.10.207:9090 prometheus 10.10.10.207
10.10.10.207:4000 tidb 10.10.10.207
10.10.10.208:4000 tidb 10.10.10.208
10.10.10.209:4000 tidb 10.10.10.209
10.10.10.207:9000 tiflash 10.10.10.207
10.10.10.207:20160 tikv 10.10.10.207
10.10.10.208:20160 tikv 10.10.10.208
10.10.10.209:20160 tikv 10.10.10.209
[root@dbserver01 ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
【概述】 场景 + 问题概述
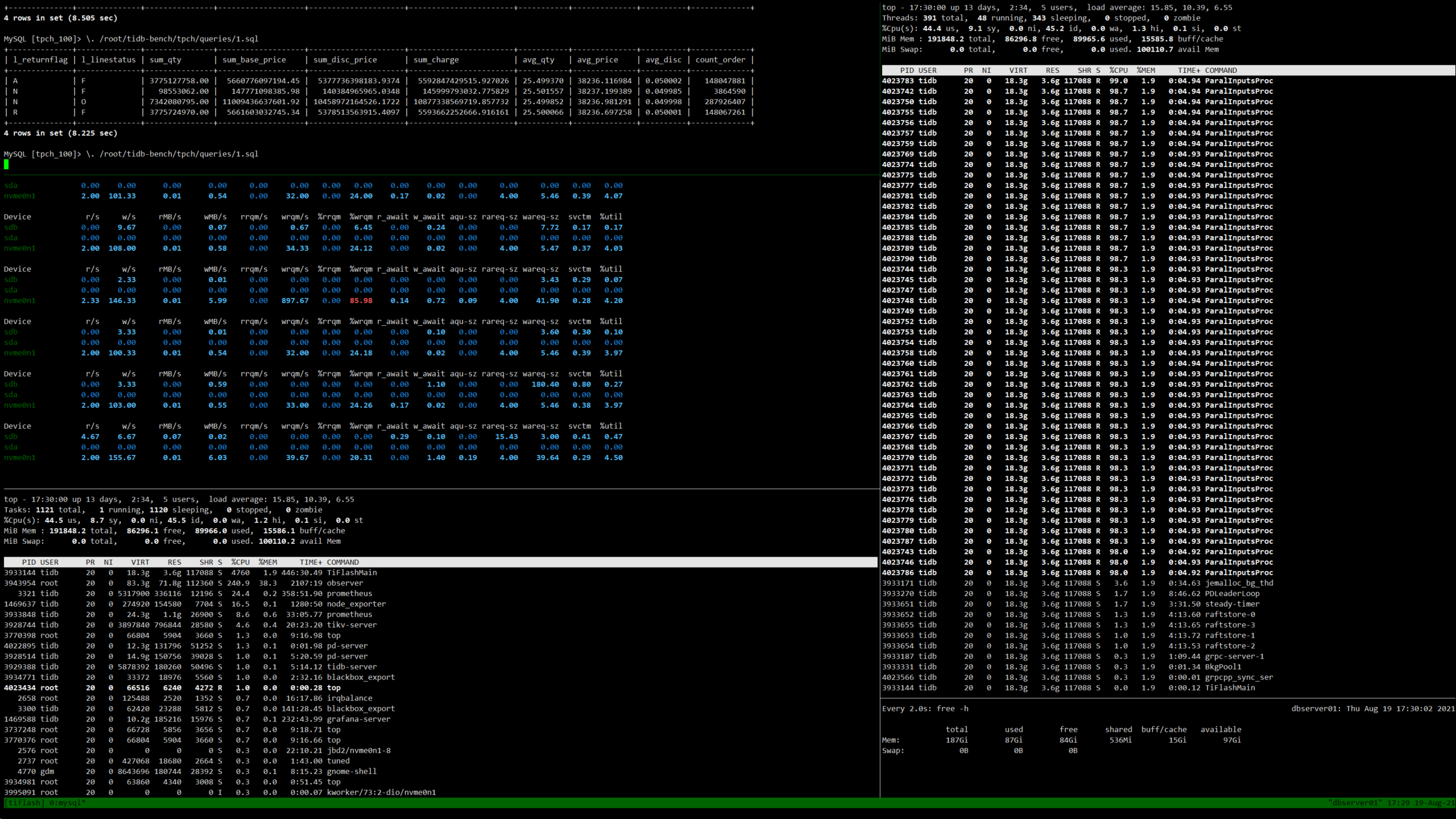
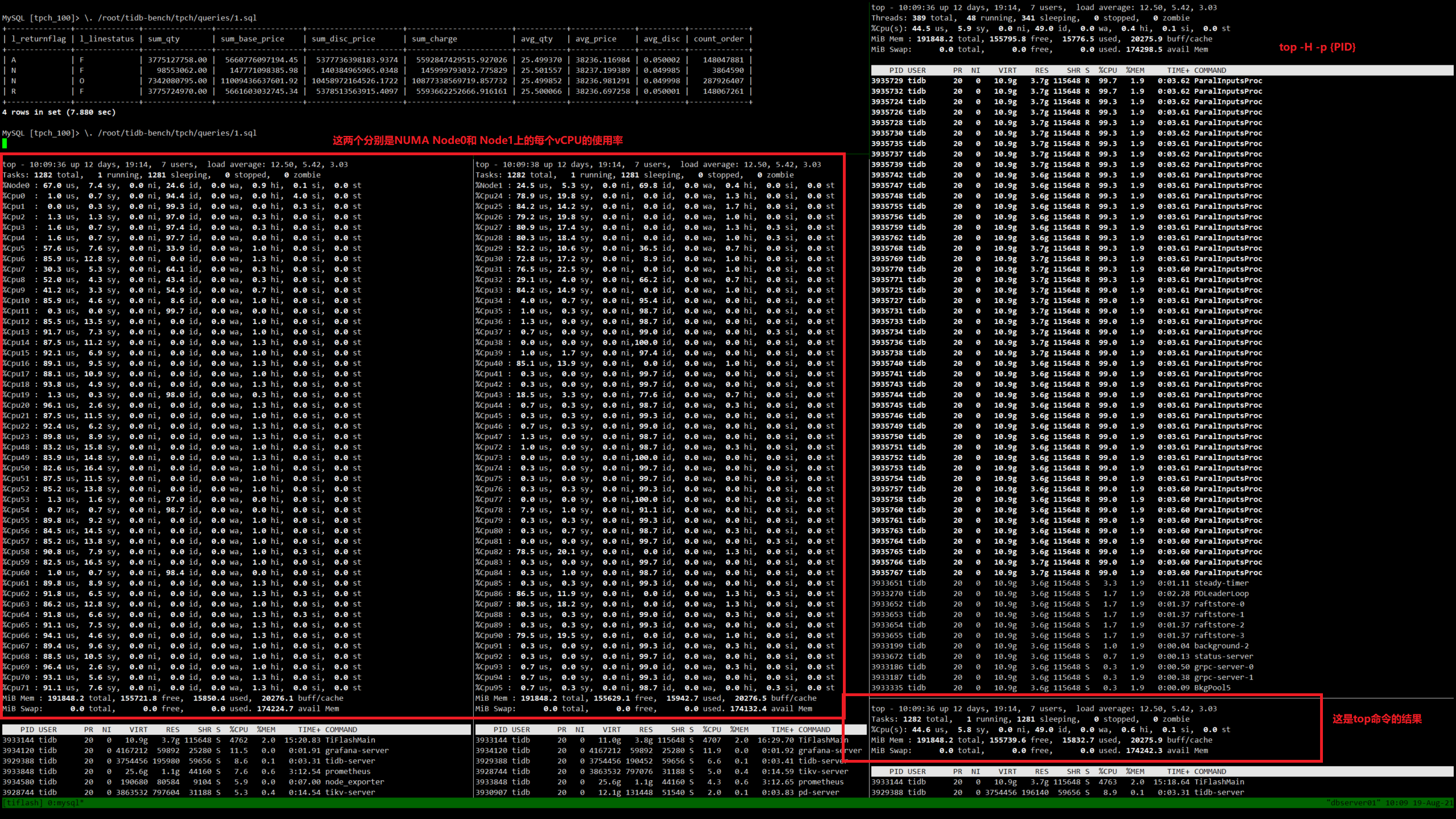
我想要使用TPC-H测试TiDB环境在 引入了 TiFlash组件之后的性能指标,我发现在我执行TPC-H的SQL语句时,TiFlash进程只能创建出48个线程(我的CPU的物理核数量就是48),从top的结果来看,几乎只用了50%的逻辑核,剩余的核都处于几乎闲置的状态
【背景】 做过哪些优化
set @@tidb_isolation_read_engines=‘tidb,tiflash’;
set @@tidb_allow_mpp=1;
set @@tidb_mem_quota_query = 10 << 30;
当前的TiFlash配置文件:
[root@dbserver01 ~]# cat /tidb-deploy/tiflash-9000/conf/tiflash.toml
default_profile = “default”
display_name = “TiFlash”
http_port = 8123
listen_host = “0.0.0.0”
mark_cache_size = 5368709120
path = “/tiflash_data/tiflash-9000”
tcp_port = 9000
tmp_path = “/tiflash_data/tiflash-9000/tmp”
[application]
runAsDaemon = true
[flash]
service_addr = “10.10.10.207:3930”
tidb_status_addr = “10.10.10.207:10080,10.10.10.208:10080,10.10.10.209:10080”
[flash.flash_cluster]
cluster_manager_path = “/tidb-deploy/tiflash-9000/bin/tiflash/flash_cluster_manager”
log = “/tidb-deploy/tiflash-9000/log/tiflash_cluster_manager.log”
master_ttl = 60
refresh_interval = 20
update_rule_interval = 5
[flash.proxy]
config = “/tidb-deploy/tiflash-9000/conf/tiflash-learner.toml”
[logger]
count = 20
errorlog = “/tidb-deploy/tiflash-9000/log/tiflash_error.log”
level = “info”
log = “/tidb-deploy/tiflash-9000/log/tiflash.log”
size = “1000M”
[profiles]
[profiles.default]
max_memory_usage = 10000000000000
cop_pool_size = 80
batch_cop_pool_size = 80
[raft]
pd_addr = “10.10.10.207:2379,10.10.10.208:2379,10.10.10.209:2379”
[status]
metrics_port = 8234
[root@dbserver01 ~]# cat /tidb-deploy/tiflash-9000/conf/tiflash-learner.toml
log-file = “/tidb-deploy/tiflash-9000/log/tiflash_tikv.log”
log-level = “info”
[raftstore]
apply-pool-size = 4
store-pool-size = 4
[rocksdb]
wal-dir = “”
[security]
ca-path = “”
cert-path = “”
key-path = “”
[server]
addr = “0.0.0.0:20170”
advertise-addr = “10.10.10.207:20170”
advertise-status-addr = “10.10.10.207:20292”
engine-addr = “10.10.10.207:3930”
status-addr = “0.0.0.0:20292”
[storage]
data-dir = “/tiflash_data/tiflash-9000/flash”
【问题】 当前遇到的问题
问题一:是什么原因,导致TiFlash进程只能创建和物理核数量的一致的线程数?
问题二:如何修改配置文件或者修改global/session变量可以使TiFlash占用更高的CPU呢?
【TiDB 版本】
Cluster version: v5.1.0