大佬,你终于来了
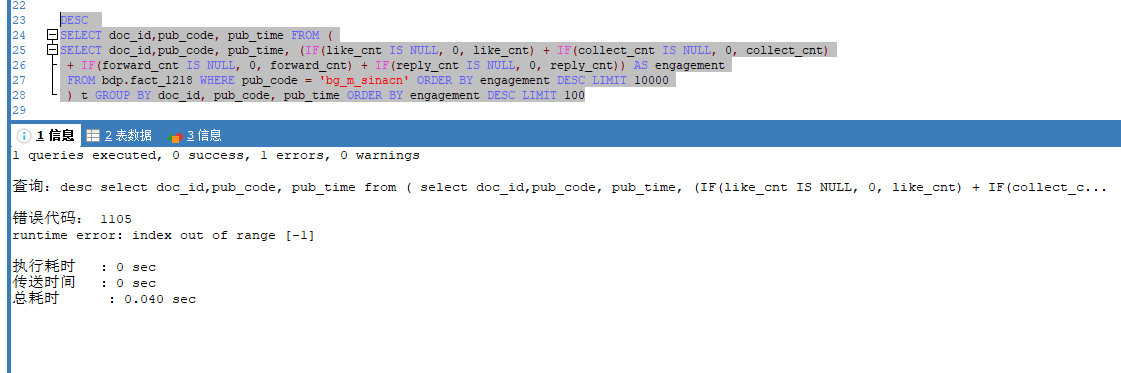
CREATE TABLE fact_3860 (
id varchar(40) NOT NULL,
doc_id varchar(40) DEFAULT NULL,
account_id varchar(40) DEFAULT NULL,
pub_code varchar(40) DEFAULT NULL,
pub_type varchar(2) DEFAULT NULL,
pub_time datetime DEFAULT NULL,
subject1_id varchar(50) DEFAULT NULL,
subject2_id varchar(50) DEFAULT NULL,
subject3_id varchar(50) DEFAULT NULL,
subject4_id varchar(50) DEFAULT NULL,
subject5_id varchar(50) DEFAULT NULL,
subject6_id varchar(50) DEFAULT NULL,
subject_keyword text DEFAULT NULL,
aspect1_id varchar(50) DEFAULT NULL,
aspect2_id varchar(50) DEFAULT NULL,
aspect3_id varchar(50) DEFAULT NULL,
aspect4_id varchar(50) DEFAULT NULL,
aspect5_id varchar(50) DEFAULT NULL,
aspect6_id varchar(50) DEFAULT NULL,
aspect_keyword text DEFAULT NULL,
subject_sentiment_type_id int(11) DEFAULT NULL,
subject_sentiment_keyword text DEFAULT NULL,
sentiment_type_id int(11) DEFAULT NULL,
unit_content text DEFAULT NULL,
bi_status_id varchar(20) DEFAULT NULL,
bi_attr_id int(11) DEFAULT NULL,
process_start_time datetime DEFAULT NULL,
process_end_time datetime DEFAULT NULL,
reply_cnt int(11) DEFAULT NULL,
view_cnt int(11) DEFAULT NULL,
like_cnt int(11) DEFAULT NULL,
forward_cnt int(11) DEFAULT NULL,
dislike_cnt int(11) DEFAULT NULL,
collect_cnt int(11) DEFAULT NULL,
play_cnt int(11) DEFAULT NULL,
haha_cnt int(11) DEFAULT NULL,
love_cnt int(11) DEFAULT NULL,
wow_cnt int(11) DEFAULT NULL,
angry_cnt int(11) DEFAULT NULL,
sad_cnt int(11) DEFAULT NULL,
care_cnt int(11) DEFAULT NULL,
coin_cnt int(11) DEFAULT NULL,
danmaku_cnt int(11) DEFAULT NULL,
pv int(11) DEFAULT NULL,
keyword varchar(1000) DEFAULT NULL,
keyword_frequency varchar(500) DEFAULT NULL,
media_id int(11) DEFAULT NULL,
media_type_id int(11) DEFAULT NULL,
dedup_label varchar(5) DEFAULT NULL,
doc_type varchar(5) DEFAULT NULL,
author_tag varchar(5) DEFAULT NULL,
flag_qc tinyint(1) DEFAULT NULL,
flag_reject tinyint(1) DEFAULT NULL,
PRIMARY KEY (id),
KEY doc_id (doc_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
表结构.txt (2.2 KB)