为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
数仓储存
【概述】 场景 + 问题概述
数仓全量数据在tidb中,有时需要全量复写或者新增全量数据。使用flink jdbc批量写入但是写入的速率和单条数据的写入速率差不多没有量级的提升,请问一下这个是什么原因。是我缺失什么设置了吗。
【Flink + TiDB 上下游关系和逻辑】
flink etl后将数据写入tidb
【背景】 做过哪些操作
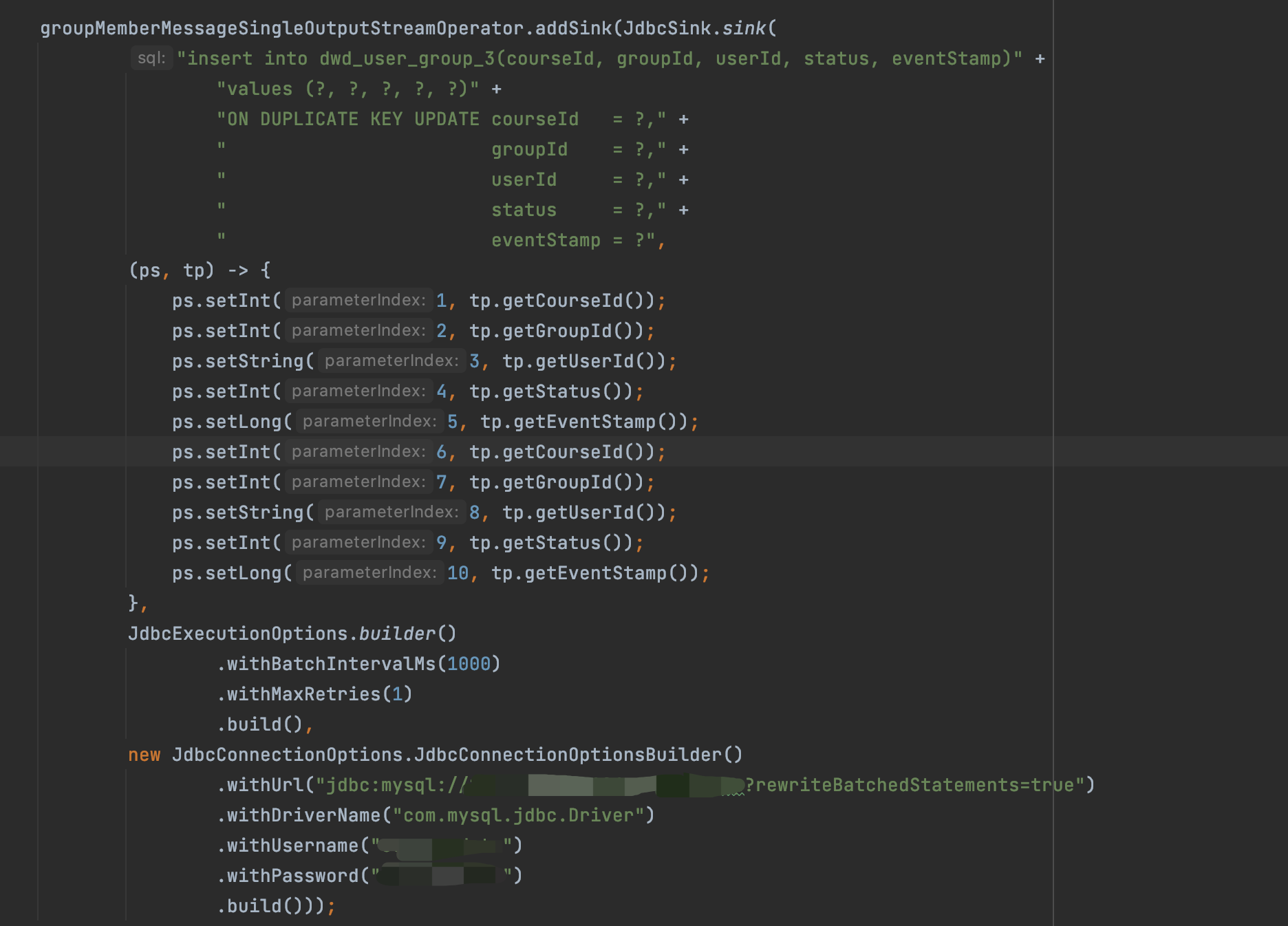
1.使用Flink jdbc写入
2.在连接中新增rewriteBatchedStatements=true
3.在连接中新增 useServerPrepStmts = true & cachePrepStmts = true
【现象】 业务和数据库现象
使用flink jdbc批量写入和自己实现单条写入效率差不多
flink10个并发,写入tidb的速率:
JDBC批量写入:5000/min
单条写入:4300/min
【问题】 当前遇到的问题
tidb写入过慢
【业务影响】
全量数量往往需要刷新10几个小时甚至可以到一天多
【 TiDB 版本】
4.0.12、k8s环境
【Flink 版本】
1.12.3
【附件】 相关日志及监控(https://metricstool.pingcap.com/)
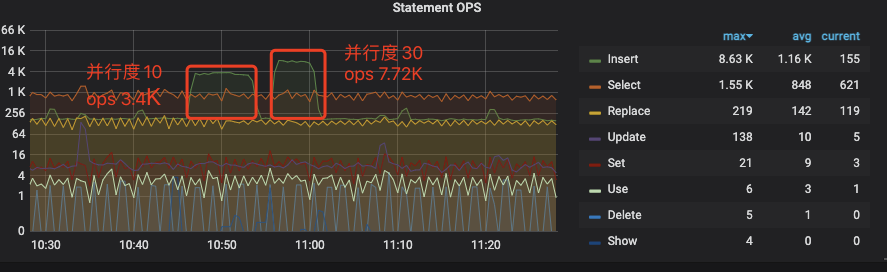
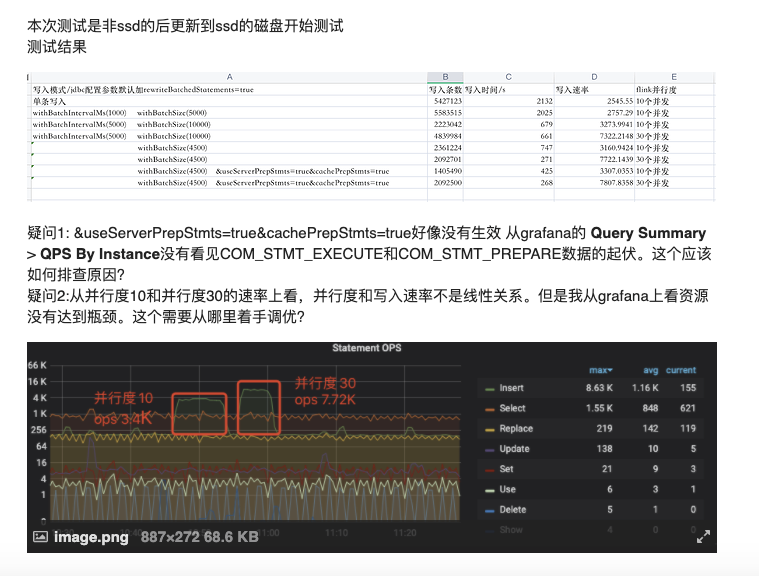
本次测试是非ssd的后更新到ssd的磁盘开始测试
测试结果

疑问1: &useServerPrepStmts=true&cachePrepStmts=true好像没有生效 从grafana的 Query Summary > QPS By Instance没有看见COM_STMT_EXECUTE和COM_STMT_PREPARE数据的起伏。这个应该如何排查原因?
疑问2:从并行度10和并行度30的速率上看,并行度和写入速率不是线性关系。但是我从grafana上看资源没有达到瓶颈。这个需要从哪里着手调优?