tidb v5.0.3版本
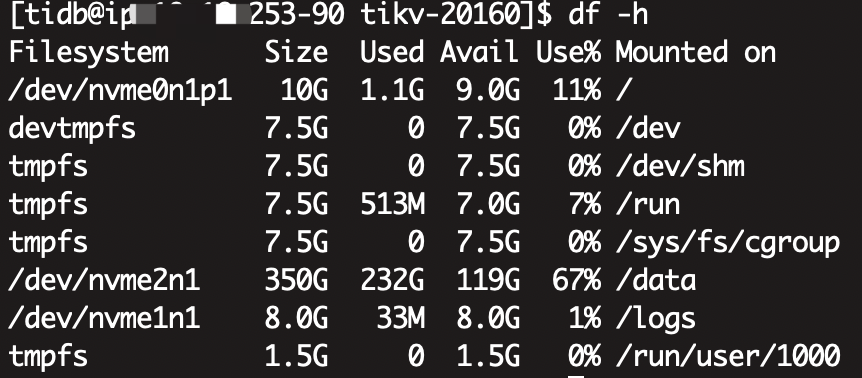
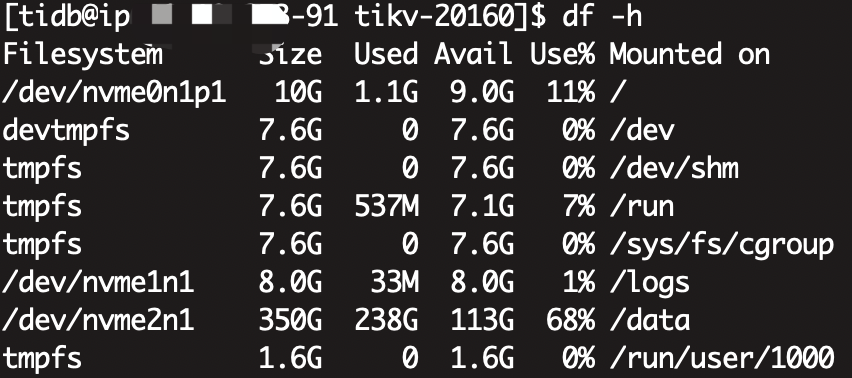
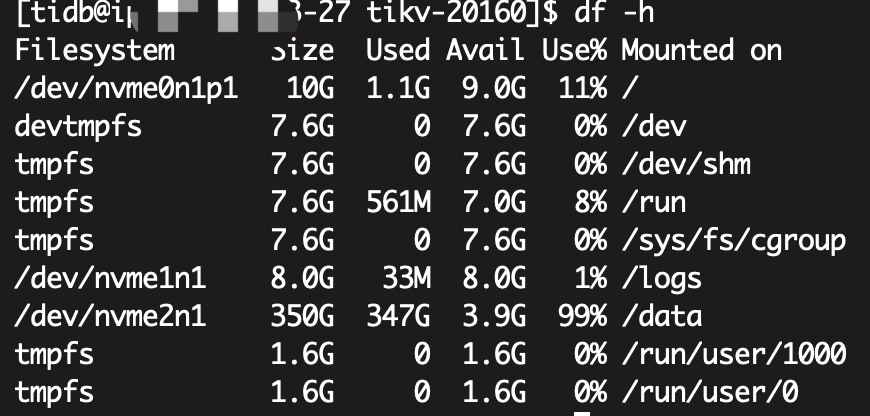
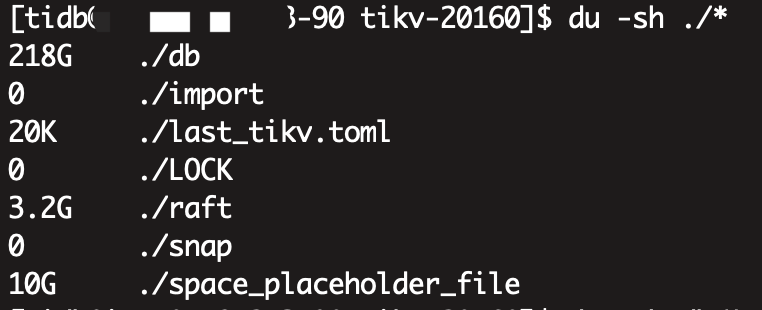
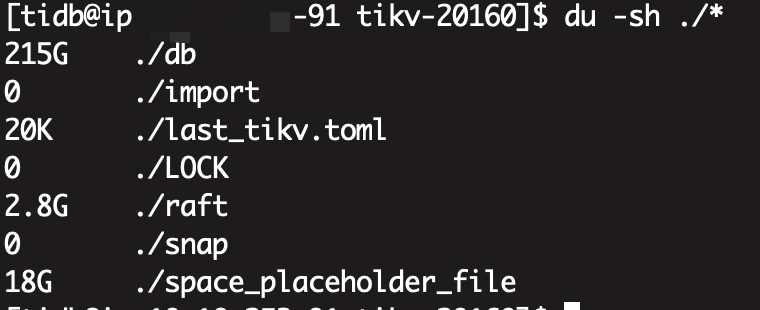
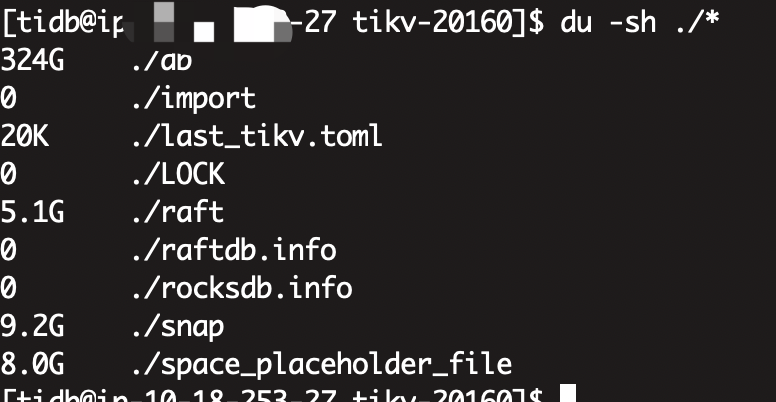
三个tikv节点,硬盘350G,副本数也是3个,按理来说应该是每台机器一个整套数据的,三台机器数据应该是完全一致的,但是我们现在两个节点占用了240G,有一个节点却占了350G沾满了,导致起不来,删除space_placeholder_file也起不来,对db目录排序取最大的文件,发现,那两个节点的最大文件也就200M左右,而这个爆满的节点db目录最大的很多2G的文件
这是df -h 查看占用:
这是查看 tikv_data目录:
在查看db目录中大文件排行:
另外有个细节是,这次宕机的是27这个节点,实际上昨天晚上91节点就被写爆宕机了,然后我们扩容后(当时是300G),91节点的磁盘占用又下来了,也就是现在的240G左右,那应该是根本达不到300G的,为啥会写爆,以及这个27节点也是,为啥会比别的节点多出来这么多数据
1 个赞
yilong
(yi888long)
2
1.是 tiup 部署的吗? tiup cluster display 目前其他两个节点是正常的吧,业务有影响吗?
2. 最大的这个节点,看下日志 tikv.log 有没有可以清理的,看看清理后,能否启动。
1 个赞
1.是tiup部署的,其他节点正常,写入业务都停止了,查询业务暂时未受影响
2.可以清理的都清理了,包括那个space余留文件,删了后自己又创建了,且改参数改为2G,不起作用
3.看上面的截图,占用都在db目录,且有大量的大的SST文件
4.为啥会出现这种不均衡的情况?为什么这个节点的文件会比其他节点多这么多,3个tikv,3个备份,理论上是磁盘占用应该是一致的
2 个赞
@yilong 这是我们第二个集群了,用的5.0.3,我们上一个集群是4.0.13没遇到过这个问题,分布很均匀,这是5.0.3的bug?
2 个赞
修改为0后,启动起来了,且目录数据瞬间下去了,且另外两个节点的磁盘空间也瞬间下去了。。。这又是啥情况。。。
2 个赞
yilong
(yi888long)
9
你是改了所有节点的参数,还是只在这一个tikv节点修改了参数? 如果都改了,是reload都重启了一遍? 所以其他两个节点少了 space hold 的占用?还是下降的比 10 G 还多?
1 个赞
只改了一个节点,只reload了这一个节点,这个节点起来后,三个节点的磁盘都大幅下降(27节点从340G降到144G,其他节点从238G降到140G左右),且过了一阵后,27这个刚起来的节点磁盘又大幅攀升(从144G涨到180G),又过了十几分钟,又大幅下降了到现在的127G,现在27这个节点是127G,另外两个节点140G左右( 真实数据目前是三台平衡了的,27节点少了13G是少了space那个文件的大小)
现在疑惑的就是,为什么某一个节点会被写爆,起来后为什么三个节点都大幅下降,且写爆的节点还有磁盘空间急速攀升和急速下降的情况
1 个赞
yilong
(yi888long)
11
麻烦帮忙收集下 pd.log , tikv.log 上传下,多谢。
1 个赞
@yilong. 先来一个pd的和tikv写爆的 , 另外两个比较大,我截取些再上传
pd_log.tar.gz (4.8 MB)
tikv_log_27.tar.gz (7.6 MB)
2 个赞
yilong
(yi888long)
13
tikv 麻烦都反馈一下,pd 如果是多个,反馈 leader 节点的日志,多谢。
1 个赞
yilong
(yi888long)
14
多谢,另外请 拿 pd 和 tikv-details 的监控,时间段覆盖大小反复变化的时段。
1 个赞
监控.zip (1.8 MB)
这两个面板导出时都卡在了98%,就直接导出了,这样是否可以
1 个赞
我就上传这一个文件,是25M,没超过48M也提示太大传不上来
最早宕机是晚上10点左右,然后中午11点起来的,磁盘爆增是不是跟compaction有关系?
@yilong 大佬,另外两个tikv节点日志地址如下:
链接: https://pan.baidu.com/s/1eFQzshhYtzV5TuEa-N8cVQ 提取码: wnjv 复制这段内容后打开百度网盘手机App,操作更方便哦
1 个赞
另外可以把爆盘节点的 ROCKSDB 的日志拿一份嘛?谢谢