阿ken
(Aken)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
生产环境
【概述】场景+问题概述
监控发现有个tikv节点服务挂了,上机发现tikv-server还在,启动时间忘了,有一段时间了,所以当时觉得很奇怪。然后查看tikv相关时间段日志,未发现明显导致服务挂掉的异常。tiup reload 该 tikv 后,tikv 进程可以起来,但是会一直重启,报错 [ERROR] [kv.rs:603] [“KvService::batch_raft send response fail”] [err=RemoteStopped] 。
【背景】做过哪些操作
【现象】业务和数据库现象
【业务影响】
【TiDB 版本】
V4.0.12
【附件】
-
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
阿ken
(Aken)
2
tikv 监控down掉时间日志
2021080810_tikv.log.tar.gz (4.9 MB)
日志中的关键点:
10:22 的时候,开始了一轮新选举,然后开始transfre leader,随即有一个failed gc.
从 10:22 开始,这个机器的iO就瞬间拉满。
阿ken
(Aken)
4
可以正常处理业务请求
查看tikv truouble shooting面板和 tidb dashboard,并没发现有读热点现象。
不一定是热点,可能是低效 SQL,比如大量 cop stask 请求 或者 全表扫 场景,可能在这个 TiKV 有大量的 cop 请求计算,导致 TiKV OOM。先查一下 TIKV 是否 oom ,可以通过 /var/demsg 日志查看服务状态。
阿ken
(Aken)
6
确实有oom,但是时间点不太对
这种情况,找到对应的查询,解决掉就好了吗
查看 7 常见问题处理思路 - 7.4 TiDB OOM 的常见原因 - 《TiDB实战(TiDB in Action)》 - 书栈网 · BookStack 文档
按照里面的 tikv-server oom 三种问题排查
都没有匹配上
阿ken
(Aken)
8
查了一遍没有很明显匹配上的点。不过有两个地方有点怀疑。
还有就是集群上周有个节点磁盘损坏了,就把它缩容了,然后重新扩入,端口什么的都一样,只是部署目录不一样,示例也起来了,老的stroe也置为Tombstone状态了,怎么删也删不掉,remove也不行。
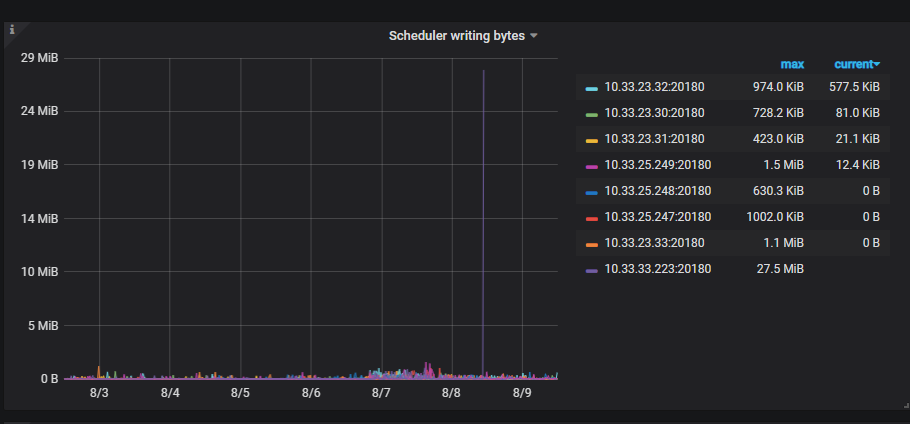
然后我看这台tikv(不是缩容又重扩的那台)事发左右的日志中,有频繁请求Tombstone节点服务的错误,再结合你贴的文章,发现了这个监控。
辛苦帮忙看下噶~
TiKV log 里面有没有 slow query 的 table id ,找一下对应的 table id 对应的 slow query log 里面记录看看那。
system
(system)
关闭
10
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。