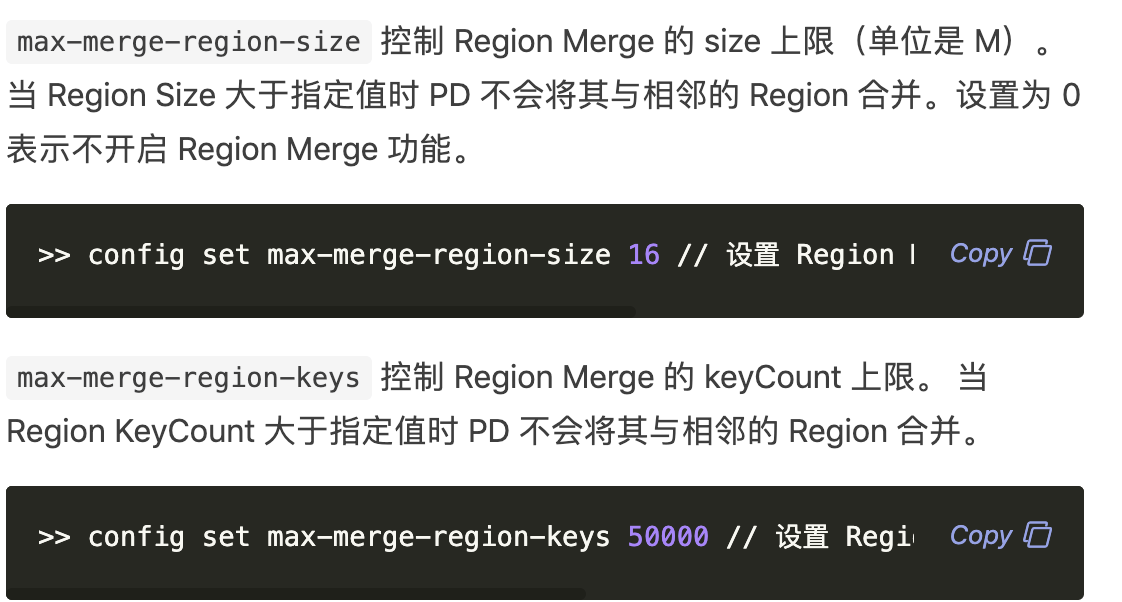
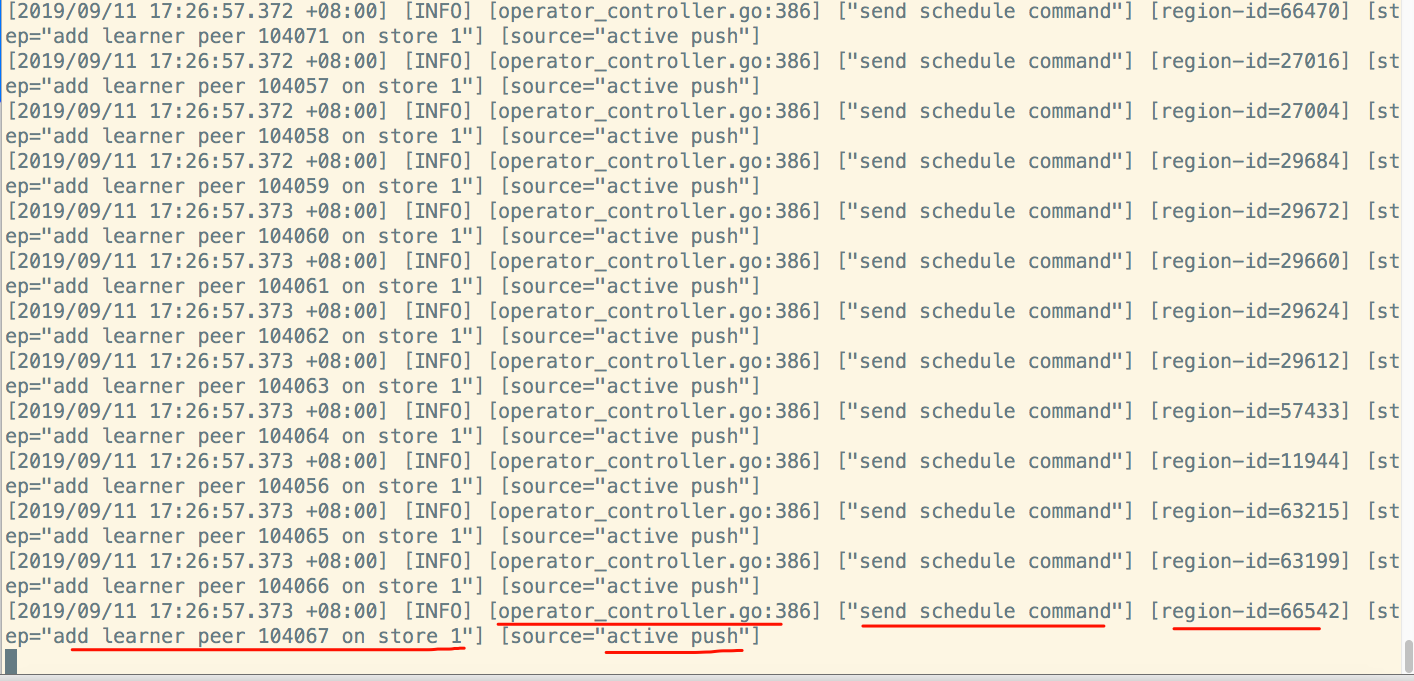
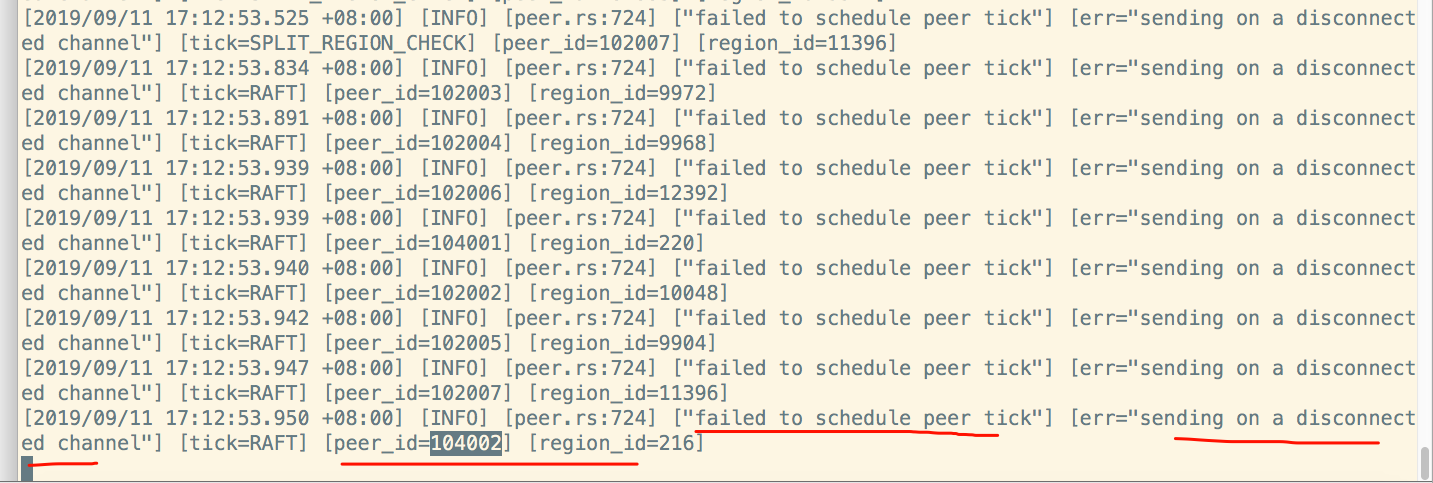
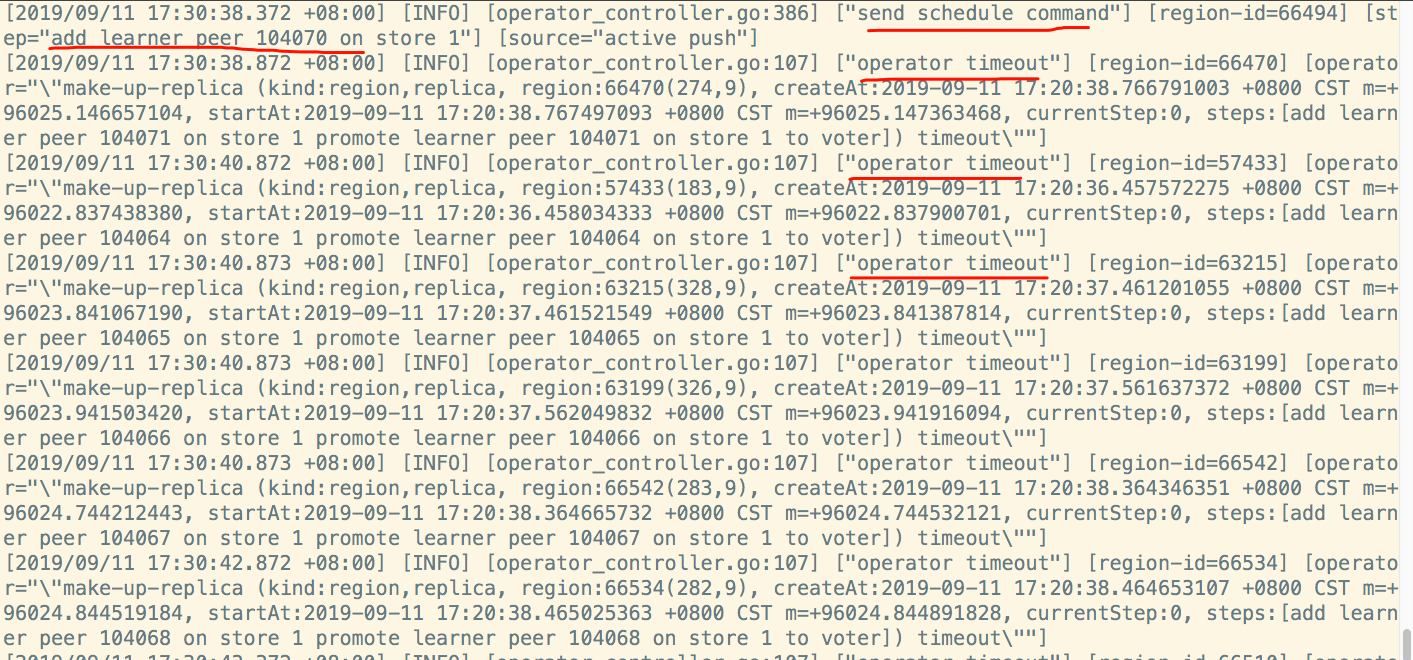
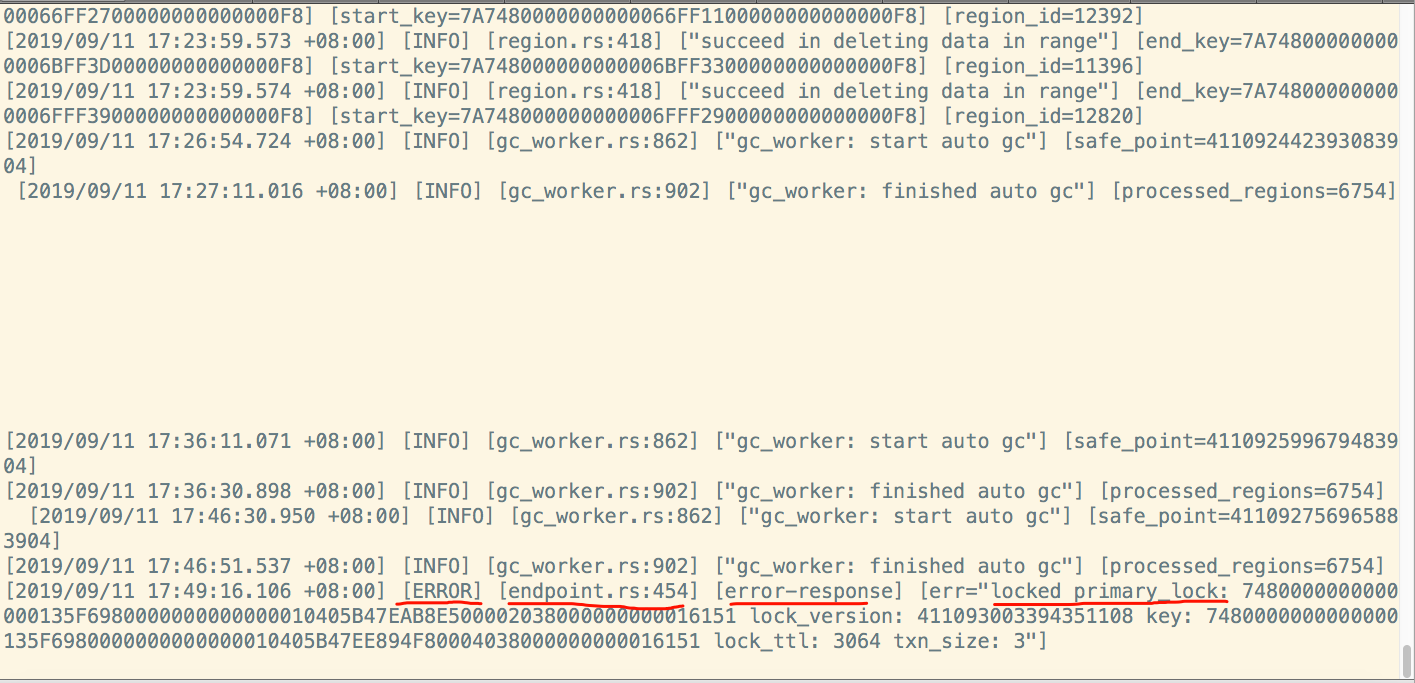
- 系统版本 & kernel 版本:CentOS-7.2.1511 && 3.10.0-327.36.3.el7.x86_64
- TiDB 版本:3.0.1(tidb,pd,tikv)
- 磁盘型号:普通机械盘
- 问题描述(我做了什么):

监控region health发现有 缺副本的 Region高达10.54k
- miss-peer:缺副本的 Region
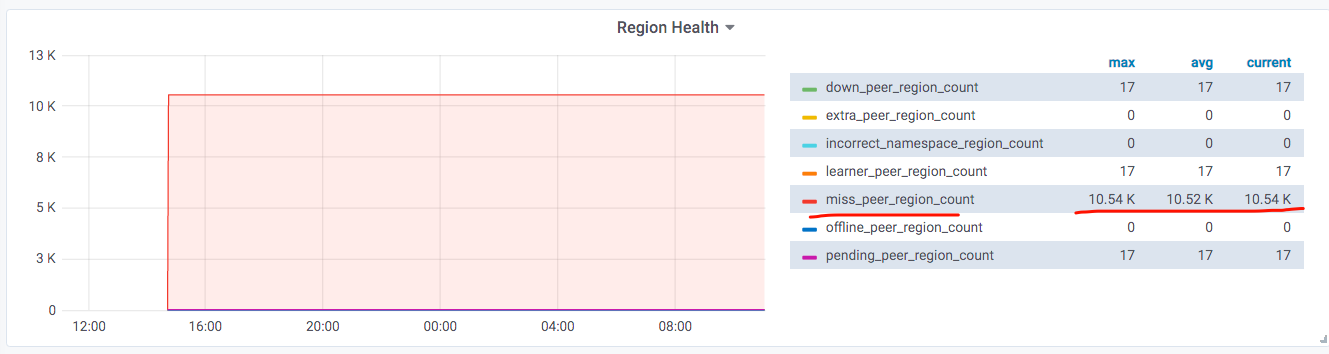

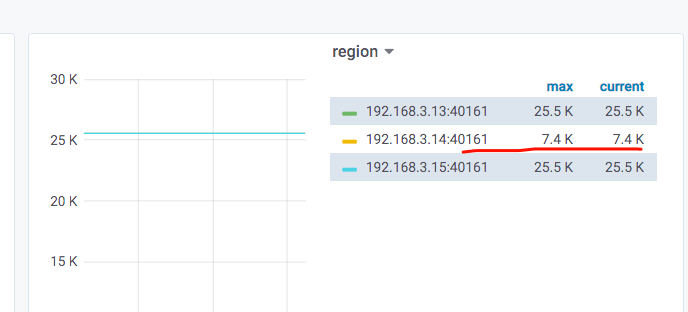
从上图来看,3.14上的tikv的region数量,确实与3.13和3.15上的tikv的region数量,相差1万多。
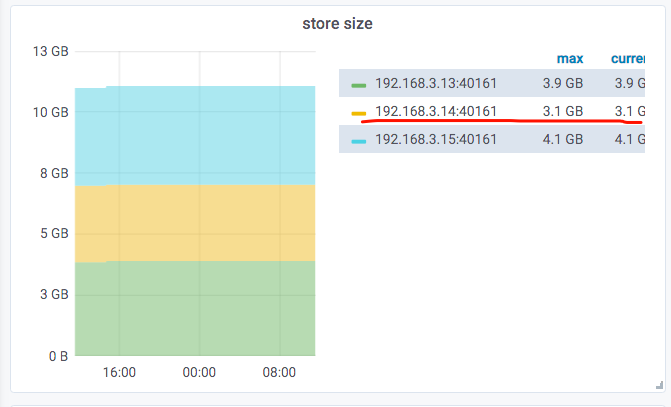
想请问一下,如何把3.14上tikv缺失的这1万+的regions恢复?谢谢!