使用 n8n 完成 TiDB 跨 IDC 的自动化迁移实践
1. 背景与问题定义
在实际生产环境中,TiDB 跨 IDC 迁移往往不是一次简单的“备份 + 恢复”操作,而是一个 长时间、强依赖外部环境、且对稳定性要求极高的连续流程。
本次迁移的基本条件如下:
-
存在 两个物理隔离的 IDC
- A 集群:现网生产集群
- B 集群:目标新集群
-
两个 IDC 网络连接不稳定
- 不具备可靠的大带宽直连
- 不适合直接 BR Backup → Restore
-
迁移路径被约束为:
A 集群 → OSS A → OSS B → B 集群
同时,迁移过程还存在几个强约束条件:
-
迁移时间窗口固定
- 总体预计 30–40 小时
- 中间过程不可频繁人工干预
-
迁移失败必须可回滚
- 任意阶段失败,A 集群仍需保持完整可用
-
连续性操作
- BR 备份
- 跨 OSS 同步
- BR 恢复
- 每一步都是“长任务 + 不确定完成时间”
-
人工值守成本不可接受
- 人工轮班盯 40 小时几乎不可持续
- 且人工介入反而容易引入误操作
因此,核心问题可以抽象为一句话:
如何在网络不稳定、任务耗时长、可失败回退的前提下,可靠地编排一次 TiDB 跨 IDC 迁移?
2. 为什么选择 n8n 作为调度与编排工具
在这个问题中,我们并不缺少“执行能力”:
- TiDB BR 已经足够成熟
- rclone 已能胜任 OSS 同步
- 各阶段状态都可以通过 CLI / 日志 查询
真正缺失的是一个 “流程级”的自动化控制平面。
2.1 传统方案的不足
| 方案 | 问题 |
|---|---|
| Shell 脚本 | 可读性差、状态管理弱、失败难恢复 |
| Cron + 人工介入 | 需要值守,且上下文断裂 |
| 单体程序 | 研发成本高,不利于快速调整流程 |
2.2 n8n 的适配点
n8n 在这个场景下有几个关键优势:
-
可视化 DAG
- 非线性流程(循环 / 判断)表达清晰
-
天然支持长时间任务
- Wait / Polling 不会占用执行线程
-
良好的失败控制能力
- Retry、分支、条件判断
-
“弱编排、强执行”
- 不替代 BR / rclone,只负责调度与判断
-
低心智负担
- 运维 / SRE 可直接维护,无需重新开发系统
在本次迁移中,n8n 的角色被明确限定为:
迁移流程的“自动化指挥官”,而不是数据面的执行者
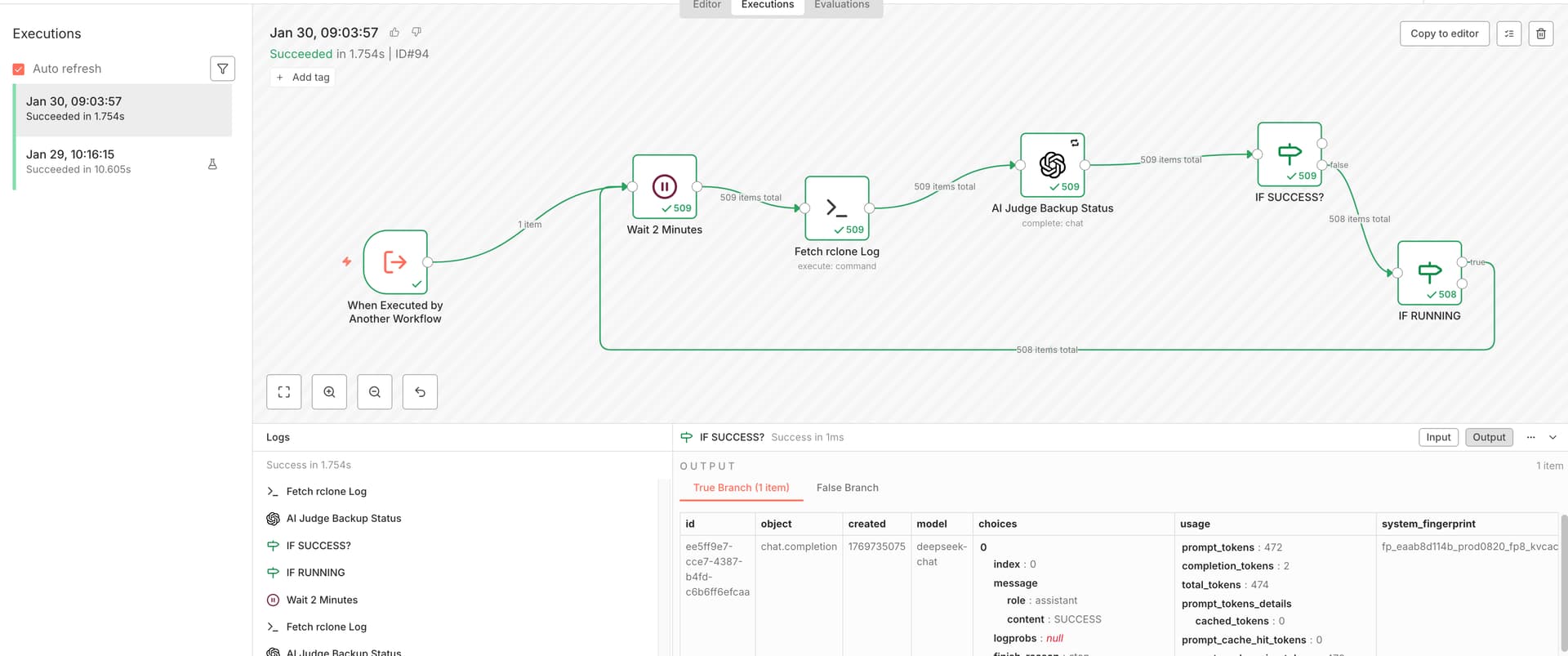
2.3 为什么引入 LLM 判断日志状态
BR / rclone 的日志具备几个特点:
- 非结构化
- 不同版本输出略有差异
- 失败信息分散在多行
如果使用纯正则判断:
- 规则复杂
- 容易漏判
- 可维护性差
因此,在 n8n 中引入 LLM 作为“状态判定器”,其职责被严格限定为:
从日志中,归一化判断任务状态
![]() 重要原则:
重要原则:
- LLM 不参与决策
- 只输出三态结果
- 不做任何“建议性推理”
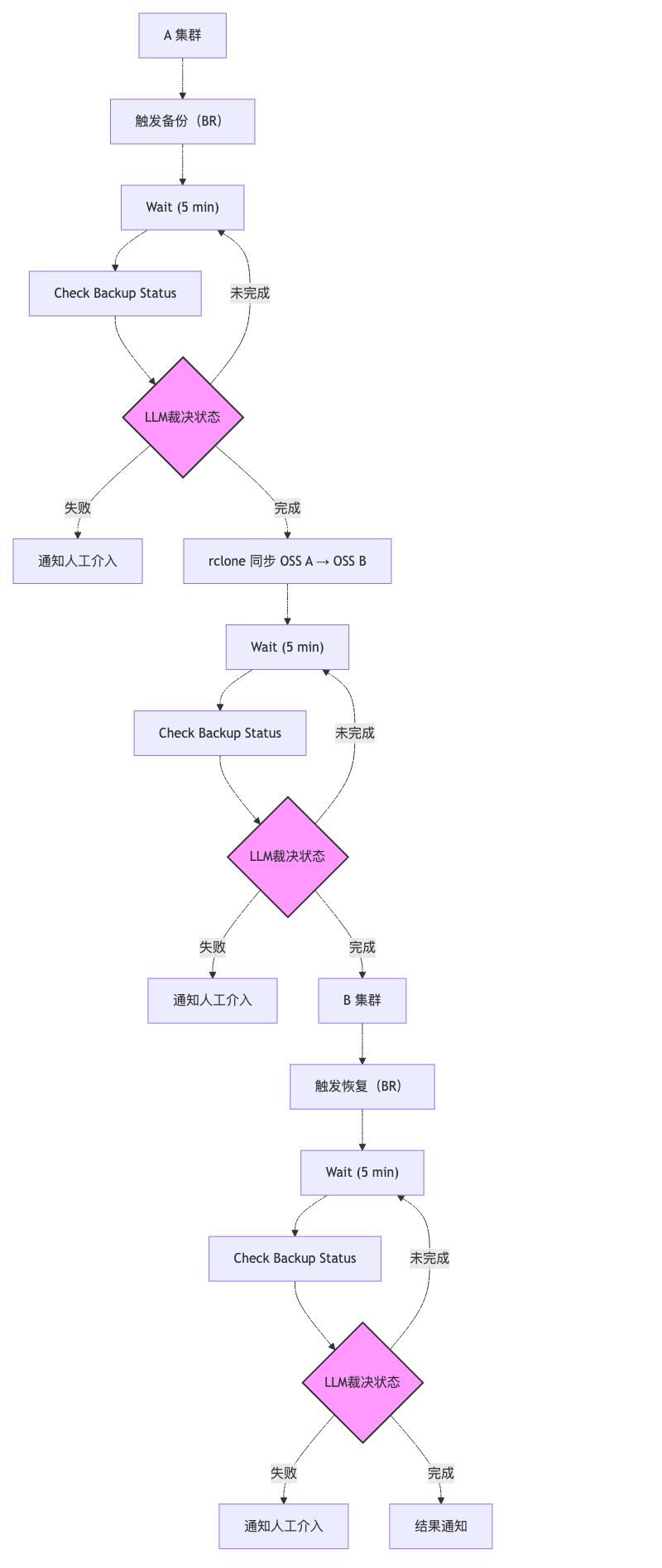
3. 整体迁移架构与流程设计
3.1 逻辑架构
A 集群
│
│ (BR Backup)
▼
OSS A
│
│ (rclone)
▼
OSS B
│
│ (BR Restore)
▼
B 集群
关键设计原则:
-
任何时刻 A 集群不被破坏
-
所有写操作只发生在:
- OSS A(备份)
- OSS B(同步)
- B 集群(恢复)
-
不存在 “A → B” 的直连强依赖
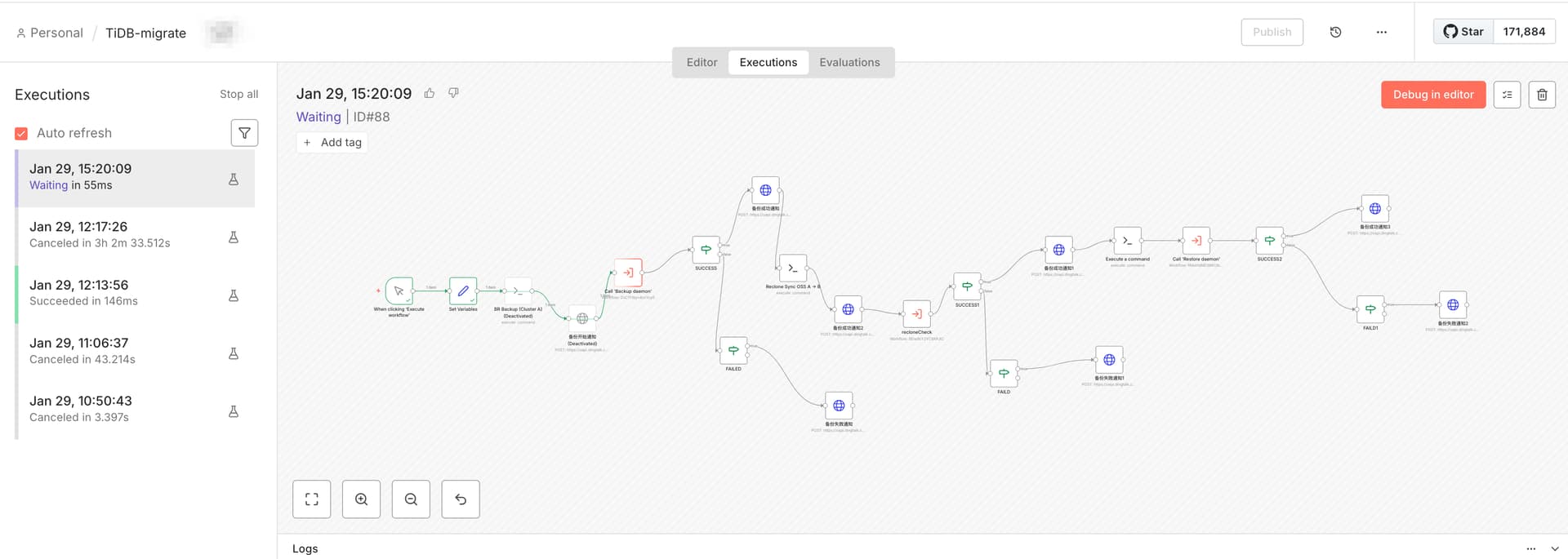
4. n8n 工作流设计说明
4.1 全流程 DAG
4.2 阶段一:A 集群备份(BR Backup)
目标:生成一份完整、可恢复的逻辑快照。
-
n8n 触发:
- 调用 BR Backup
-
关键参数:
- backup-type:full
- storage:OSS A
- concurrency:根据 A 集群负载评估
状态检查设计
在 30–40 小时的连续迁移中,以下情况非常常见:
- SSH 会话中断
- 执行节点重启
- n8n workflow 被恢复 / 重跑
因此,本方案刻意不依赖单次命令执行结果,而是统一采用:
“日志驱动的状态判断模型”
即:
-
执行与状态解耦
-
执行只负责“启动任务”
-
状态统一通过 读取日志内容 判断
-
判断维度:
- RUNNING/SUCCESS/FAILED
-
失败策略:
- 直接中止流程
- 通知人工介入
- 不影响 A 集群线上流量
4.3 阶段二:OSS A → OSS B 同步(rclone)
这是跨 IDC 场景的关键步骤。
设计要点:
-
使用 断点续传 + 校验 的同步工具
-
n8n 不直接参与数据传输,仅做:
- 启动
- 轮询
- 判断完成状态
为什么要单独拆一段流程?
-
同步时间不确定
-
网络抖动可能导致多次失败 / 重试
-
必须允许:
- 同步重启
- 不影响已完成数据
n8n 的循环 + Wait 模型非常适合这个阶段。
4.4 阶段三:B 集群恢复(BR Restore)
这是唯一一个会影响目标集群状态的阶段。
B 集群必须是“干净的新集群,这是整个方案能够成立的核心前提之一。
所谓“干净的新集群”,具体包括:
- 未承载任何线上业务流量
- 不存在历史遗留数据
- 未执行过任何 Restore / Import 操作
- 系统表、用户表均为初始化状态
原因在于:
-
BR Restore 是破坏性操作
-
无法对“部分已有数据”的集群做安全合并
-
在失败场景下:
- 只能 整体重建 B 集群
- 而不是回滚到某个中间状态
因此,本方案的隐含设计是:
B 集群 = 可随时销毁并重建的目标环境
这也进一步保证了:
-
所有失败风险都被限制在:
- OSS
- B 集群
-
A 集群始终不承受任何风险
恢复执行:
-
触发 BR Restore
-
同样采用:
- Wait + 状态轮询
- 明确成功 / 失败分支
5. 失败兜底与可回滚性设计
5.1 任意阶段失败的系统状态
| 阶段 | A 集群 | OSS A | OSS B | B 集群 |
|---|---|---|---|---|
| Backup 失败 | ||||
| 同步失败 | ||||
| Restore 失败 |
结论:
整个迁移流程中,A 集群始终不被破坏,具备天然回滚能力。
5.2 n8n 的失败处理策略
-
明确区分:
- 业务失败(BR / rclone 失败)
- 流程失败(节点异常)
-
所有失败路径:
- 立即停止后续执行
- 发出告警(IM / 邮件 / Webhook)
-
不做“自动重试恢复数据”这种高风险操作
6. 总结
在这套设计中,n8n 的核心职责可以总结为一句话:
执行任务 + 读取日志 + 驱动状态机
状态流转逻辑始终保持一致:
RUNNING → Wait → Check → RUNNING
SUCCESS → 进入下一阶段
FAILED → 终止流程 + 通知
优点非常明确:
- 不依赖单点执行状态
- Workflow 可随时恢复
- 长时间任务天然友好
- 逻辑清晰、可审计
我们将一次高风险、长时间的 TiDB 跨 IDC 迁移:
转化为一个可观测、可中断、可恢复的自动化工程流程
三阶段状态判断 Prompt 设计说明
3.1 第一阶段:BR Backup 状态判断
适用场景
- A 集群 Full Backup
- 日志来源:BR stdout / 文件日志
Prompt 设计
你是 TiDB 运维专家。
br备份中 包含 Full backup failed summary 表示备份失败
包含 Full Backup success summary 表示备份成功
其他代表正在备份中
以下是 BR Backup 日志片段:
{{$json["stdout"]}}
请判断当前状态,只能返回以下三个之一:
RUNNING
SUCCESS
FAILED
判定语义约束
| 返回值 | 含义 |
|---|---|
| RUNNING | 任务仍在执行,需继续轮询 |
| SUCCESS | 备份完成,可进入 OSS 同步 |
| FAILED | 立即终止流程,人工介入 |
n8n 中 IF 节点 仅基于字符串等值判断,不解析日志本身。
3.2 第二阶段:OSS A → OSS B(rclone)
设计说明
-
rclone 天然支持:
- 断点续传
- 校验
-
网络抖动场景下:
- 同步可能长时间处于 RUNNING
Prompt 设计
你是 rclone 专家。
rclone_sync 日志文件中 中 包含 100% 表示备份成功 即为 SUCCESS
其他代表正在备份中 RUNNING
以下是 rclone_sync 日志片段:
{{$json["stdout"]}}
请判断当前状态,只能返回以下两个之一:
RUNNING
SUCCESS
设计取舍说明
-
本阶段默认不主动识别 FAILED
-
原因:
-
rclone 失败通常是瞬时网络问题
-
更适合通过:
- 进程是否退出
- 超时机制
- 人工介入
-
-
在工程实践中:
- FAILED 分支更多作为 兜底异常路径
3.3 第三阶段:BR Restore 状态判断
适用场景
- B 集群 Full Restore
- 对集群影响最大的一步
Prompt 设计
你是 TiDB 运维专家。
br备份中 包含 Full Restore failed summary 表示备份失败
包含 Full Restore success summary 表示备份成功
其他代表正在备份中
以下是 BR Restore 日志片段:
{{$json["stdout"]}}
请判断当前状态,只能返回以下三个之一:
RUNNING
SUCCESS
FAILED