如何在TiCDC同步数据到Kafka时,根据表中租户ID字段的值将数据路由到Topic的不同分区,并确保同一租户的数据严格有序?
【TiDB 使用环境】测试环境
【TiDB 版本】v8.5.3
【部署方式】云上部署
【操作系统/CPU 架构/芯片详情】
【机器部署详情】CPU大小/内存大小/磁盘大小
【集群数据量】
【集群节点数】
【问题复现路径】
数据库中每个表 均有 tenant_id 字段,且该字段创建了索引,使用 canal-json 协议, Partition 分发器 5中分发器 测试均不满足需求,同一个事务多个表数据会 分发到 kafka的不同分区,以下是 测试时创建 changefeeds的核心配置:
"dispatchers": [
{
"matcher": [
"*.*"
],
"partition": "index-value",
"index":"idx_tenant_id"
}
]
"dispatchers": [
{
"matcher": [
"*.*"
],
"partition": "columns",
"columns":["tenant_id"]
}
]
使用 columns 分发器 + tenant_id 字段路由,配合 max_in_flight_requests_per_connection: 1 确保顺序
{
“changefeed_id”: “tidb-to-kafka-tenant-routing”,
“sink_uri”: “kafka://kafka-cluster:9092/tidb_changestream?partition-num=5&version=2.0&max-message-bytes=1048576”,
“protocol”: “canal-json”,
“table_filter”: [
“.” // 同步所有表(可按需求过滤,如 “db1.", "db2.t_”)
],
“dispatchers”: [
{
“matcher”: [“.”], // 匹配所有表(支持精细化匹配,如 “db1.t_user”, “db2.*”)
“partition”: “columns”, // 基于字段路由分区
“columns”: [“tenant_id”], // 路由字段:tenant_id(所有表必须含该字段)
“hash”: “crc32” // 哈希算法(默认 crc32,可选 murmur3,效果一致)
}
],
“sync_point”: {
“enable”: true,
“interval”: 300 // 定期保存同步 checkpoint,避免重启后重放全量数据
},
“sink”: {
“kafka”: {
“compression”: “snappy”, // 压缩算法,提升传输效率
“acks”: “1”, // 消息确认机制(根据 Kafka 集群稳定性调整,1 为默认)
“max_in_flight_requests_per_connection”: 1 // 限制单连接并发请求数,避免乱序(关键!)
}
}
}
最新的测试及结果, 看现象 columns 类型 partition 分发器 并没有生效,以下是测试配置:
{
"sink_uri": "kafka://xxx/tidb_binlog_topic?protocol=canal-json&kafka-version=2.8.2&max-message-bytes=67108864&replication-factor=3",
"replica_config": {
"filter": {
"rules": [
"*.*"
]
},
"ignore_ineligible_table": true,
"sink": {
"dispatchers": [
{
"matcher": [
"*.*",
"!*.global_sequence"
],
"partition": "columns",
"columns":["global_seq"]
}
]
}
}
}
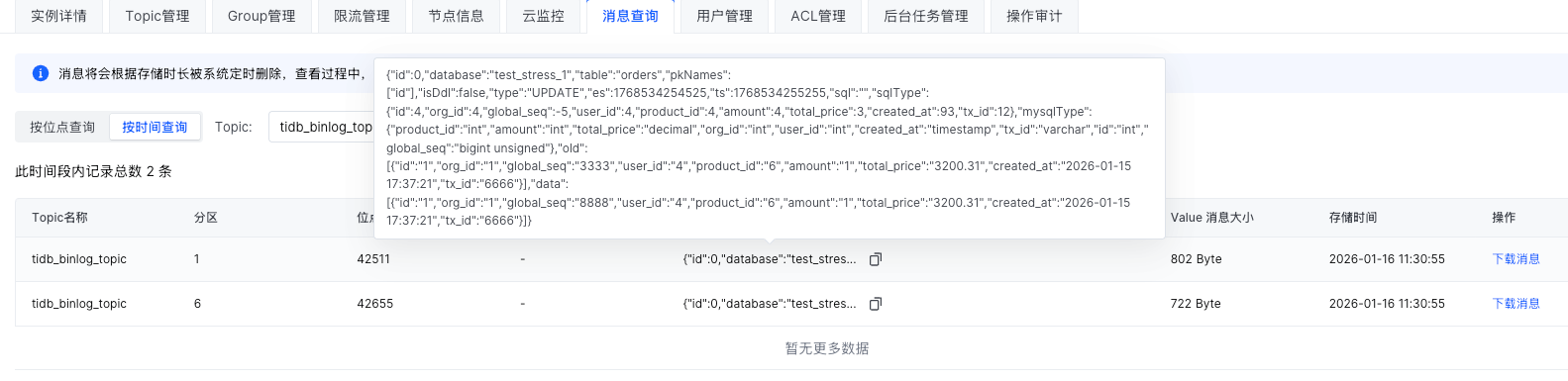
对应的kafka topic tidb_binlog_topic 有 12个分区 。
TiDB 中测试脚本:
begin;
update orders set global_seq =8888 where id < 2;
update products set global_seq=8888 where id < 2;
commit ;
kafka 消息 被路由到了两个分区: