【 TiDB 使用环境】生产环境
【 TiDB 版本】8.5.3
【复现路径】无
【遇到的问题:问题现象及影响】
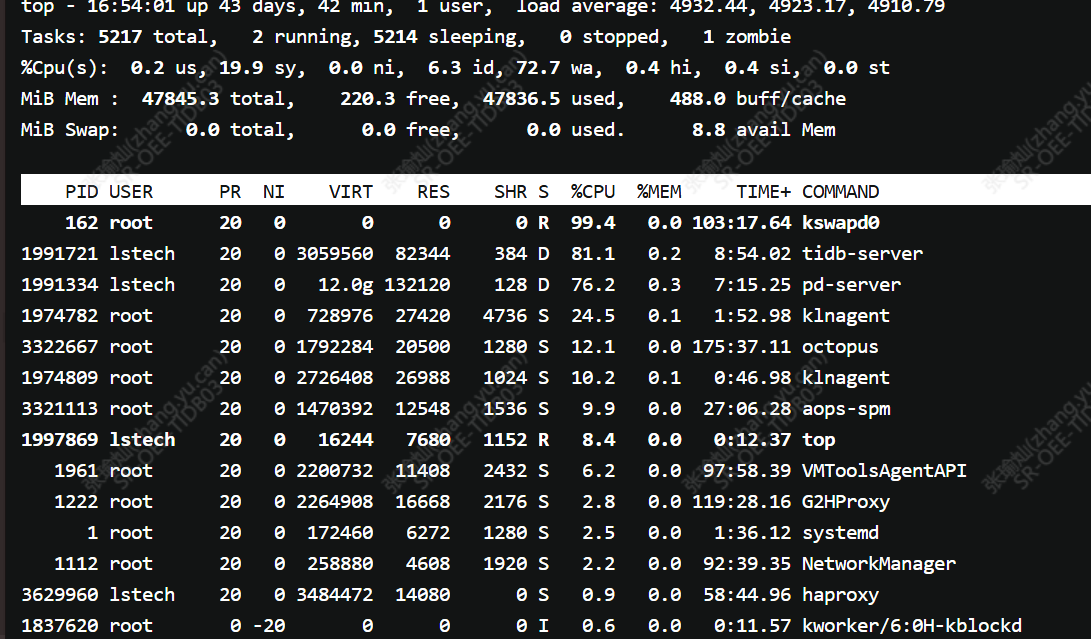
整个集群崩了, pd,tidb,tikv,tiflash 先后挂了,且无法重启. 共9台机子,3台tidb和3pd,其中tidb和pd共用两台,其中一台装haproxy负载, 目前试运行阶段,数量和请求都不大. 最大的一个慢查询20秒,约10多万数量,查询很快,发送占用大部分时间
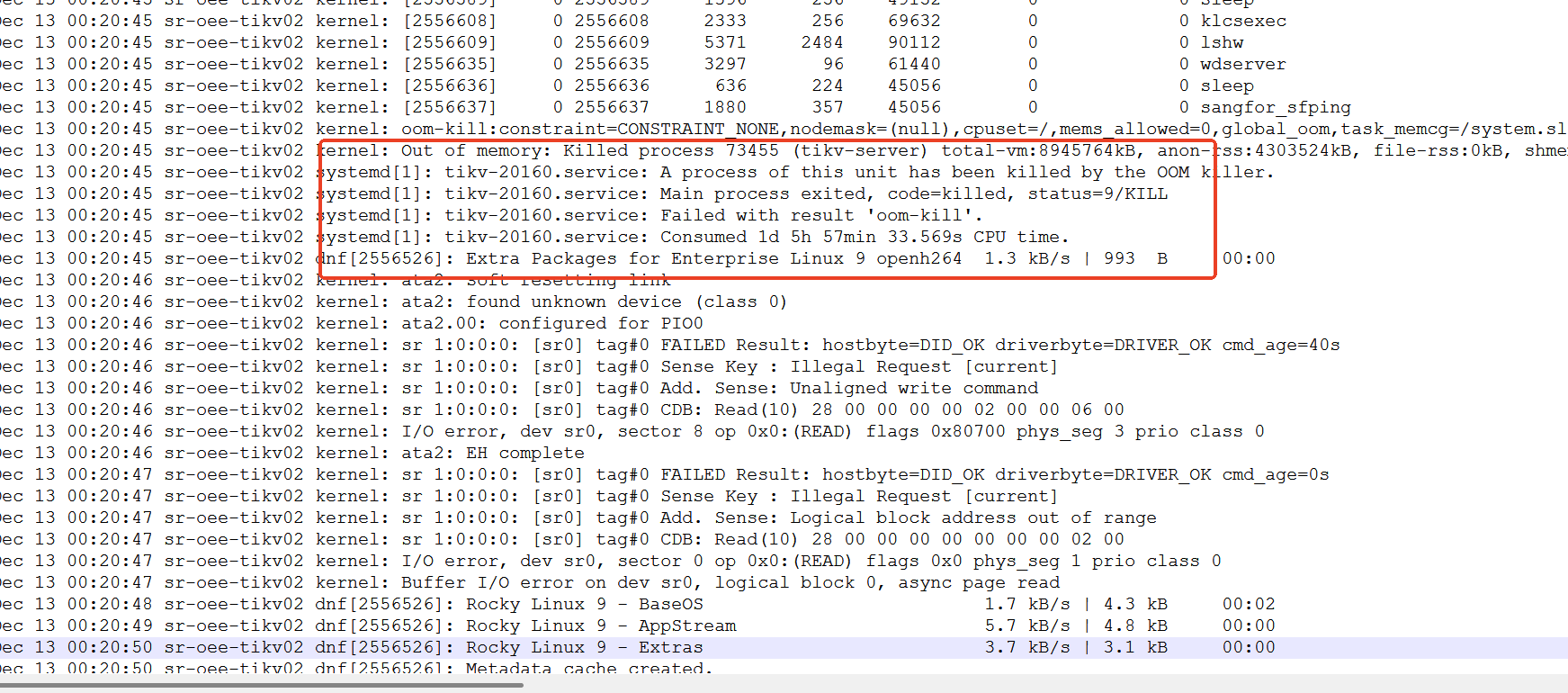
程序被操作系统oom kill后,系统服务自动重启失败
【 TiDB 使用环境】生产环境
【 TiDB 版本】8.5.3
【复现路径】无
【遇到的问题:问题现象及影响】
整个集群崩了, pd,tidb,tikv,tiflash 先后挂了,且无法重启. 共9台机子,3台tidb和3pd,其中tidb和pd共用两台,其中一台装haproxy负载, 目前试运行阶段,数量和请求都不大. 最大的一个慢查询20秒,约10多万数量,查询很快,发送占用大部分时间
程序被操作系统oom kill后,系统服务自动重启失败
检查一下系统的 ulimit -n,如果 FD limit 设置过低,TiKV(通常需要高并发文件句柄)在启动时可能因无法打开 SST 文件而卡死或崩溃。
但凡有办法,别把服务都部署在一个节点,资源争抢,优化很闹心的
尽量还是单部,避免混部(混部的机器配置得高一些)
从sql入手看看能不能优化,你这个不是混合部署的问题
先登录每台节点,收集 OOM 相关日志和组件日志,定位具体内存耗尽的组件, 临时释放节点内存, 再逐个重启组件
先通过系统日志定位 OOM 进程,清理环境后分步重启集群,再通过调整配置、优化查询、规划节点资源避免复发
看着是节点资源共用导致内存竞争 + 内存配置不合理导致的问题
测试阶段,平时内存占用只有一点. 已经是64G内存了
64G内存的机子