【TiDB 使用环境】生产环境
4013
【操作系统】
【问题复现路径】做过哪些操作出现的问题
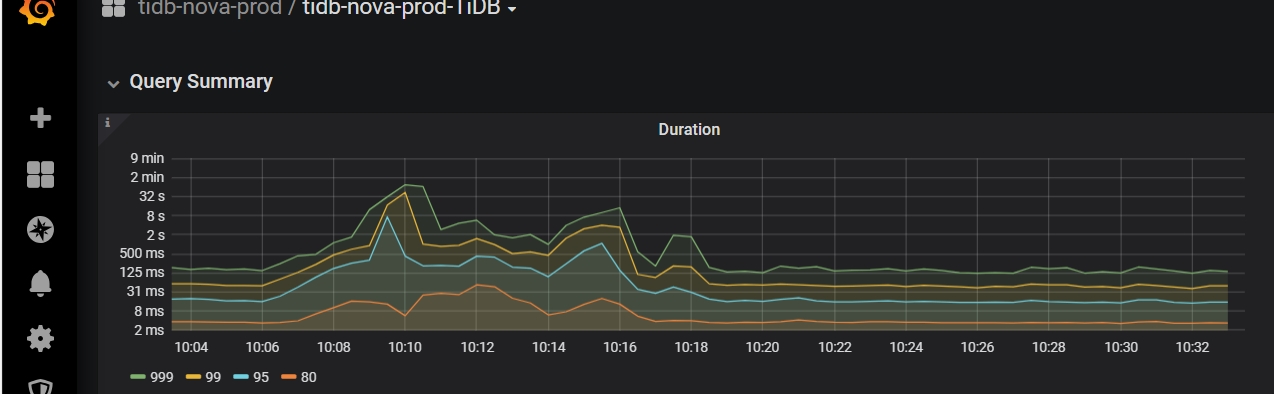
ticdc有两个节点,重启了其中一个节点,导致数据库during拉的很高, 平时跑的慢的sql,都特别慢,差不多10分钟左右才恢复正常
【TiDB 使用环境】生产环境
4013
【操作系统】
【问题复现路径】做过哪些操作出现的问题
ticdc有两个节点,重启了其中一个节点,导致数据库during拉的很高, 平时跑的慢的sql,都特别慢,差不多10分钟左右才恢复正常
理论上应该没啥影响吧
你的版本太老了 4.0版本的ticdc那时候问题挺多的
升级一下吧
重启一个节点不会影响
真不一定,实际用起来还是不一样
是不是版本8.5.1
不影响 群集
版本升级一下?
不会影响
可能是重启单个节点后触发日志追赶、负载转移、调度抖动的连锁反应,最终传导至 SQL 层导致慢 SQL 激增
短期内处理方式可以通过扩容 TiCDC、调整拉取并发、关闭非必要调度快速降负载
长久使用可以试试优化 TiCDC/TiKV/PD 的资源配置和同步策略,避免单节点故障导致的负载集中
会不会是重启了owner角色的ticc.要切换角色,新的owner角色可能需要向tiKV请求变更日志,tikv变得异常繁忙
PD RPC failed: [4013] failed to get timestamp
``` 有这个吗?有机会的话,升机一下,后续会少一些问题。
看回复都支持你做CDC升级版本
因为他的版本真是太老了, 后面又很多优化
关于节点,TiDB的处理方式是多副本机制,这点与其他数据库有所不同。 具体实施时还需要根据实际情况调整。