【TiDB 使用环境】生产环境 /测试/ Poc
【TiDB 版本】7.1
【操作系统】 银河麒麟v10 SP3
【部署方式】硬盘 海光
【集群数据量】只用到了tidb-server
【集群节点数】
【问题复现路径】重启tidb
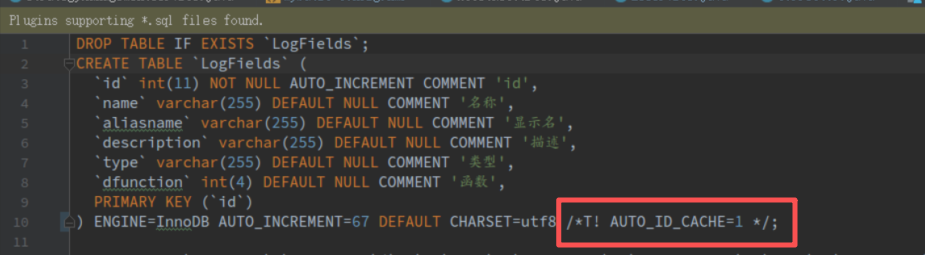
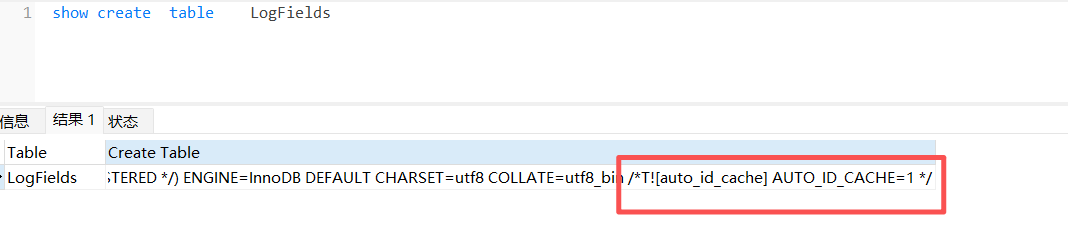
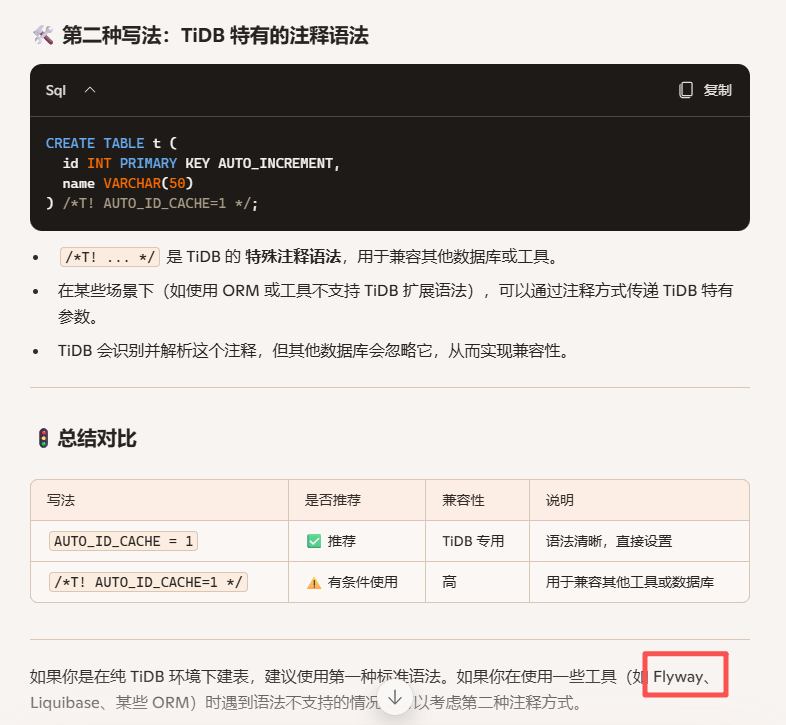
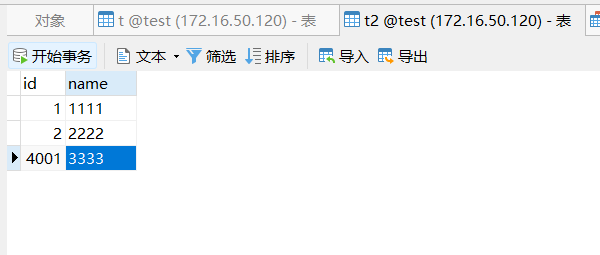
【遇到的问题:问题现象及影响】 我这边表已经设置了/*T! AUTO_ID_CACHE=1 */ ,但是我每次重启tidb后,字段还是增长了差不多4000,请问这是怎么回事?是我哪里设置的有问题吗?谢谢了
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
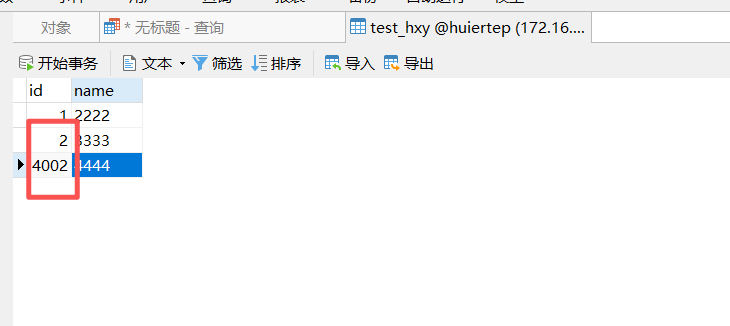
我用的flyway来建表的,之前没有设置/*T! AUTO_ID_CACHE=1 */的时候,每重启一次增长差不多30000 。现在设置了差不多4000.
Kongdom
(Kongdom)
5
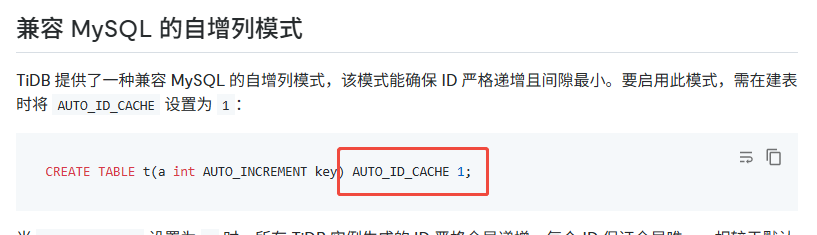
是的,这是tidb特有的注释语法,我的意思是参照官方文档设置,看看是否正常,如果不正常就是有bug。
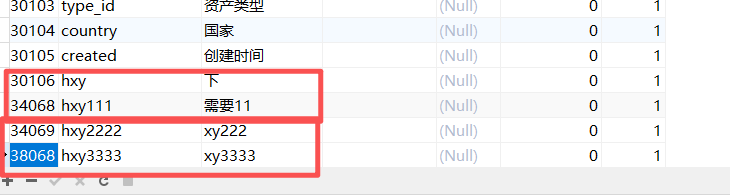
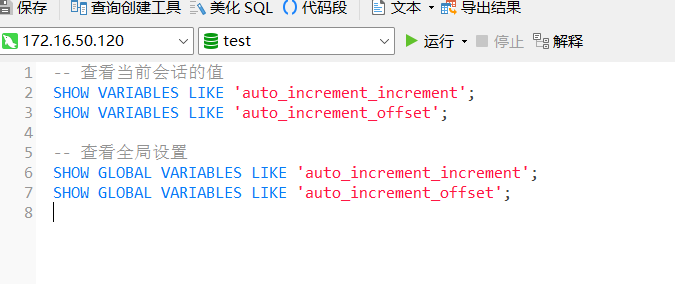
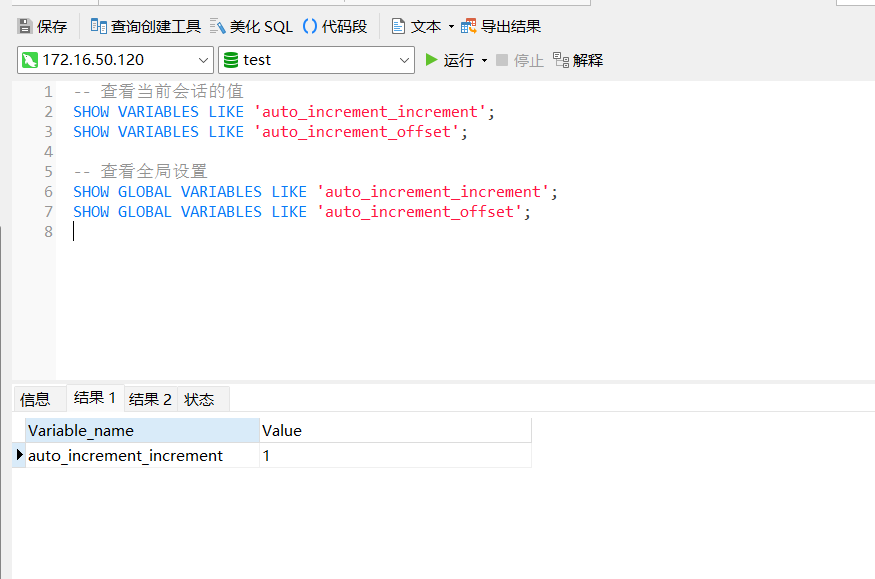
4个变量都是1.而且我又建了2个表,一个是AUTO_ID_CACHE=1,一个没有,没有的增长30000,有的增长4000.
版本信息:
我看文档说是6.4以上就支持了。我们现在用的7.1.0
现在已经在用7.1.0了,要换很麻烦。我看文档说6.4以上就支持了。我再下载一个试试吧,感觉是不是和操作系统有关,我用的国产操作系统,有些代码没同步吗?
nobody
(不定时出现)
14
还是和实现机制有关系,tidb/pkg/autoid_service/autoid.go at dc2548aac79a712265e831cff2a3a896bc0a5a38 · pingcap/tidb · GitHub
mysql 兼容的自增 ID 分配机制,其实是集群里的某一个 tidb-server 作为中心化的节点,提前申请一批 ID 在内存里,其他 tidb-server 来这个节点的内存中申请,以此来实现较好的性能,避免每次都去 tikv 申请。
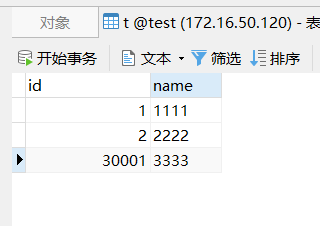
所以如果这个中心化的 tidb-server 节点一旦重启,那么就会丢失已缓存的 4000 个 ID(由于其他节点会使用一部分,所以有可能少于4000)。
好的, 我的确是每次都重启了tidb-server,而且下载了v7.1.6,尝试centos,kylin2个操作系统,都是增长了4000.
谢谢解答
但是如果 [每次重启tidb后,字段还是增长了差不多4000,什么情况下只会增长1 ?除了正常运行的以外。 感觉这样AUTO_ID_CACHE = 1参数的含义不是很大?
nobody
(不定时出现)
17
这个更多的是解决早期有些业务或者框架,依赖自增 ID 的严格递增来实现的业务逻辑。有没有意义是针对使用方来说的,如果没有使用场景,即使没有 GAP 也是没有意义的。
我们是一个老旧的mysql用户,自增长id都是int,移植过来2种选择:
1.设置AUTO_ID_CACHE = 1
2,将自增长id改成bigint。
但是人力有限,而且为了快一点,所以选择了方法1 。但是看上去方法1也不是很适应 
nobody
(不定时出现)
19
其实如果你的业务对严格递增没有要求,用默认的配置就行 
默认的配置是不设置AUTO_ID_CACHE = 1 的意思吗?如果不设置,每重启一次就增加30000条,我们是int类型,担心id会爆,因为不知道现场会是什么情况,虽然说现在数据量不大。