【TiDB 使用环境】生产环境 /测试/ Poc
【TiDB 版本】7.5.3
【操作系统】centos7.9
【部署方式】
【集群数据量】
【集群节点数】
【问题复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
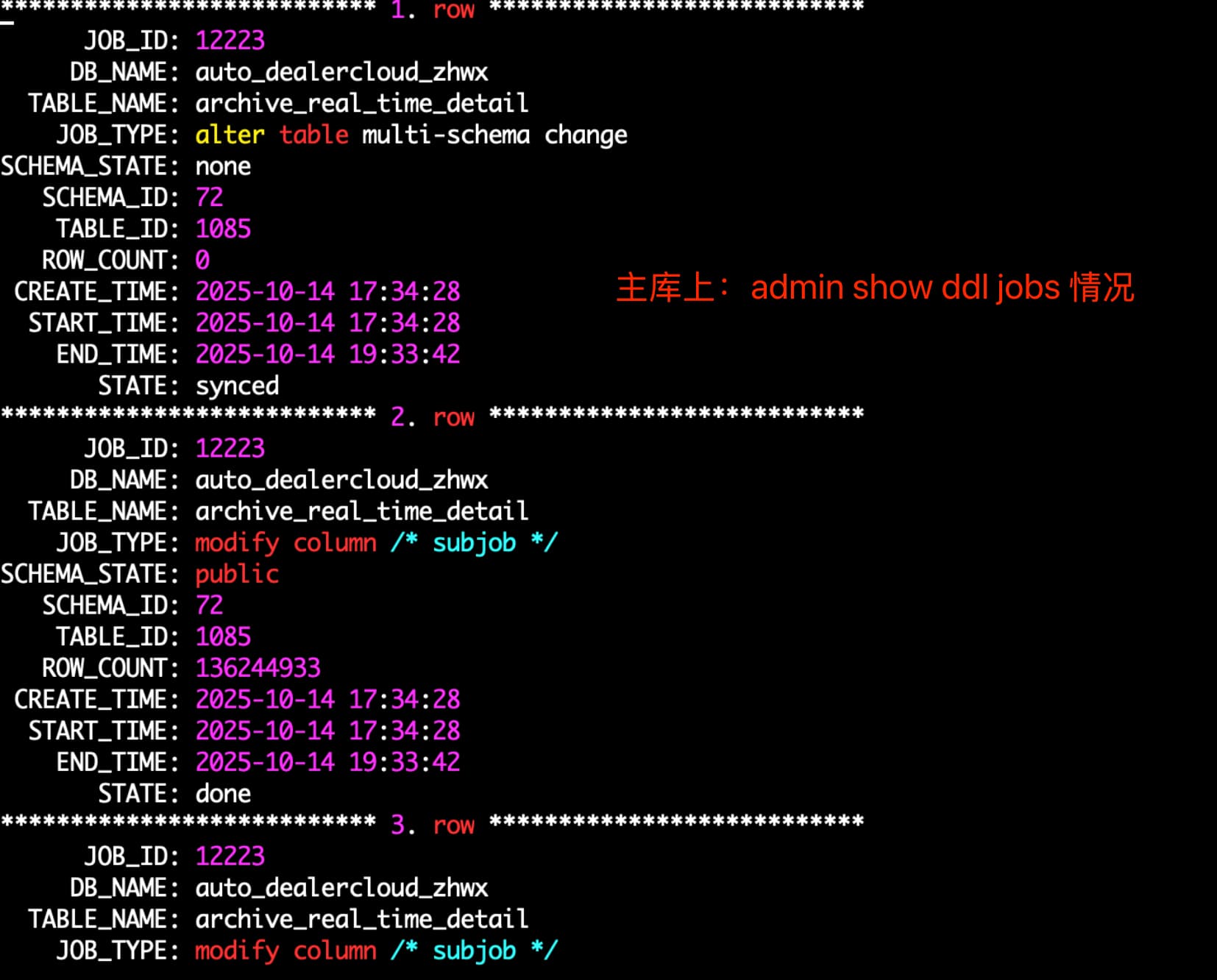
问题: 主从集群通过CDC同步,主库改大表结构导致CDC同步异常
1)在主库改大表(3亿数据),主库耗费约2小时
ALTER TABLE archive_real_time_detail MODIFY COLUMN policy_interests VARCHAR(100) NOT NULL DEFAULT ‘-1’ COMMENT ‘政策关注1:厂方政策、2:店端政策’, MODIFY COLUMN customer_concerns VARCHAR(255) NOT NULL DEFAULT ‘-1’ COMMENT ‘客户关注点 1:外饰 2内饰’;
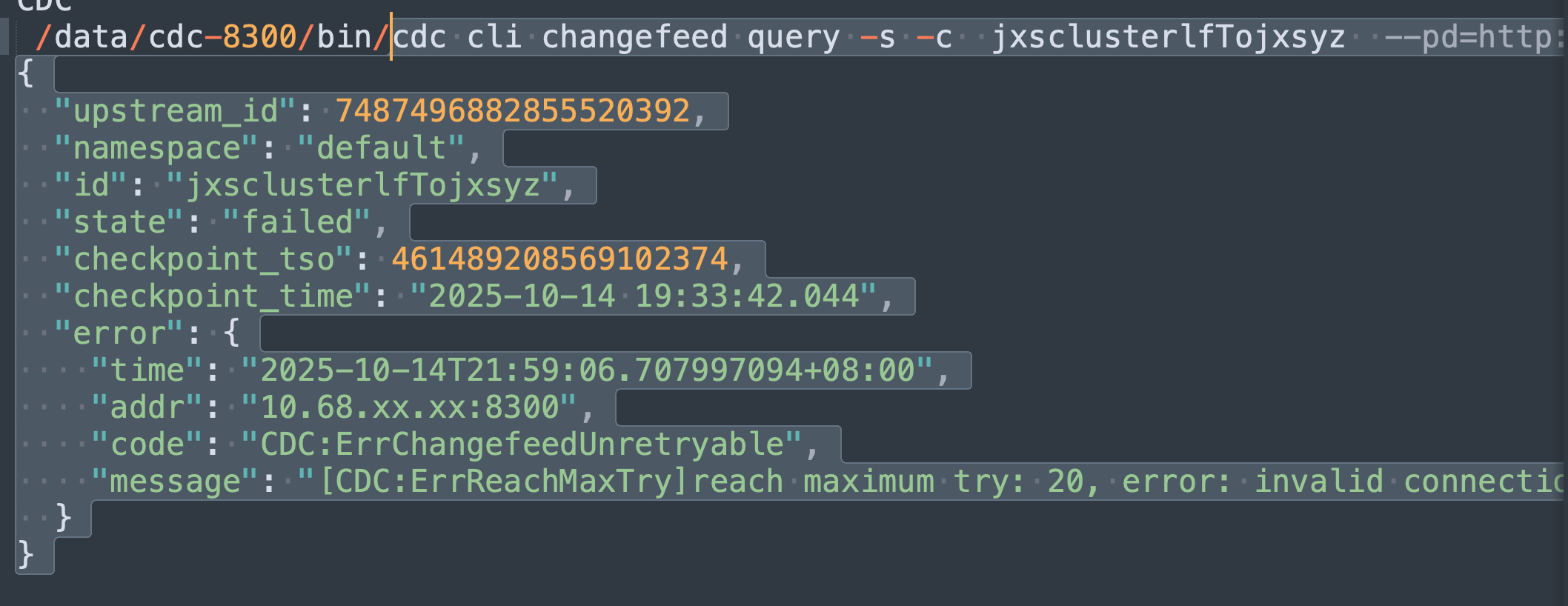
2)发现CDC同步中断
2.1)CDC同错
cdc cli changefeed query -s -c jxsclusterlfTojxsyz
“namespace”: “default”,
“id”: “jxsclusterlfTojxsyz”,
“state”: “failed”,
“checkpoint_tso”: 461489208569102374,
“checkpoint_time”: “2025-10-14 19:33:42.044”,
“error”: {
“time”: “2025-10-14T21:59:06.707997094+08:00”,
“addr”: “10.68.128.218:8300”,
“code”: “CDC:ErrChangefeedUnretryable”,
“message”: “[CDC:ErrReachMaxTry]reach maximum try: 20, error: invalid connection: invalid connection”
}
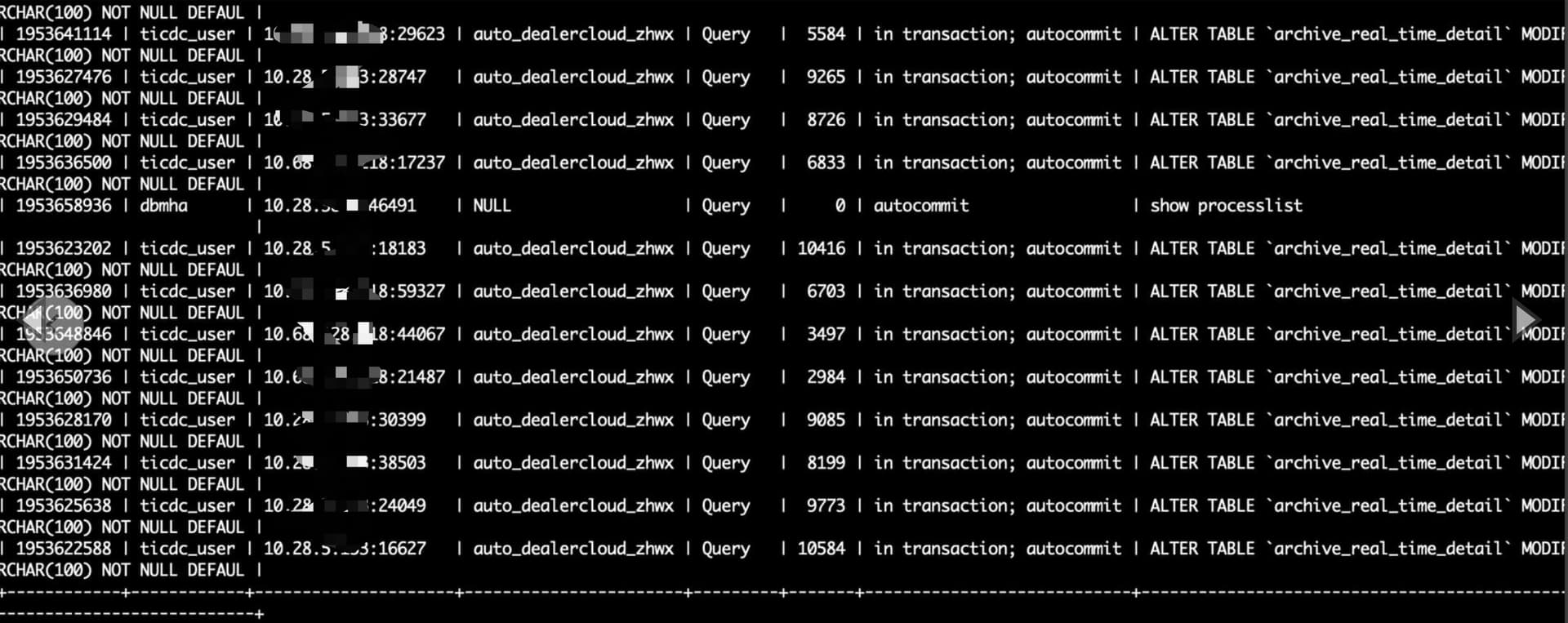
3)检查发现从库上show processslist有很多条相同的alert table SQL .
当时执行admin show ddl jobs ; 也确实有多条相同alert sql,有些在队列中。
问:1)问题原因及如何解决?
** 2)为什么从库上会有很多alert SQL呢?**
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
主库上ddl情况:
CDC同步错误:
问题当时从库状态:
CDC日志:
grep -i “ddl.*error” cdc.log.20251014
[2025/10/14 20:50:22.817 +08:00] [INFO] [shared_stream.go:226] [“event feed receive from grpc stream failed”] [namespace=default] [changefeed=jxsclusterlfTojxsyz_processor_ddl_puller] [streamID=23] [storeID=7] [addr=10.68.129.23:20161] [code=Canceled] [error=“rpc error: code = Canceled desc = context canceled”]
