【TiDB 使用环境】生产环境
【TiDB 版本】v8.5.1
【操作系统】
【部署方式】云上部署(什么云)/机器部署(什么机器配置、什么硬盘)
【集群数据量】2T
【集群节点数】7

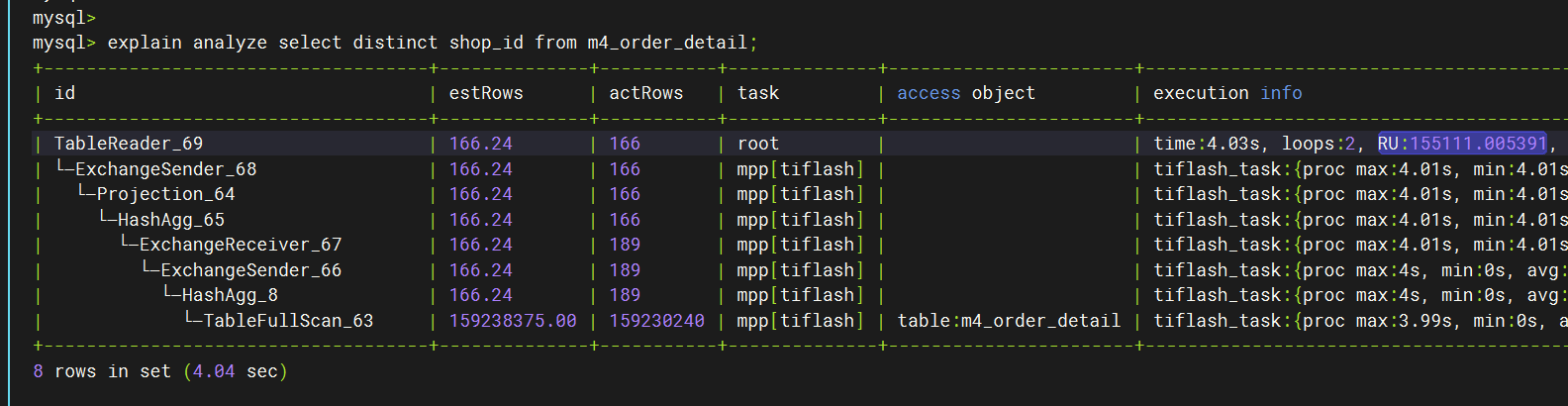
如图所示,用tiflash查表里面所有的shop_id,总共有166个shop_id。
RU 居然超过 15万,不太符合我对列式存储的认知。
补充一下,我使用的是联合主键,shop_id 是主键的第一个元素,PRIMARY KEY (shop_id,oid)
【TiDB 使用环境】生产环境
【TiDB 版本】v8.5.1
【操作系统】
【部署方式】云上部署(什么云)/机器部署(什么机器配置、什么硬盘)
【集群数据量】2T
【集群节点数】7
如图所示,用tiflash查表里面所有的shop_id,总共有166个shop_id。
RU 居然超过 15万,不太符合我对列式存储的认知。
补充一下,我使用的是联合主键,shop_id 是主键的第一个元素,PRIMARY KEY (shop_id,oid)
不用distinct,试试group by呢
加shop_id索引。。扫描行数会大量减少。
有 shop_id 索引的
效果一样咯
tiflash 扫整列的,扫了 1 亿多数据,资源消耗高也正常。
https://github.com/pingcap/tidb/blob/release-8.5/docs/design/2022-11-25-global-resource-control.md
![]() 列存不是只扫16条?
列存不是只扫16条?
为啥只扫 16 条?
![]() 列存,相同的值不应该合并嘛,一共16个shop_id,这个字段里不应该只存16条记录?distinct shop_id取值应该是扫16条吧。
列存,相同的值不应该合并嘛,一共16个shop_id,这个字段里不应该只存16条记录?distinct shop_id取值应该是扫16条吧。
他只是会同列数据进行高压缩存储,但不会自动合并相同值的记录,原始数据的行级信息仍被保留。
也就是 TiFlash 中该字段的存储仍会保留所有行的记录,所以你看他这个执行计划还是扫了很多数据的。所以 cpu 使用高也就是 ru 高了。。。。
不过 cpu 够的话,一亿多的列扫 4s 确实不算快。
![]() 那跟我理解的有偏差,为什么count、sum会快?哦,意思是会快,但是资源还是要消耗那么多?
那跟我理解的有偏差,为什么count、sum会快?哦,意思是会快,但是资源还是要消耗那么多?
count 和 sum 得看执行计划,计数和去重肯定还是有区别的。
实际上还是扫那么多数据肯定要消耗的。压缩应该只是减少了 io。
不过我也觉得 tiflash 本身肯定还是有一些优化空间的。
![]() 感谢大佬,确实是我理解偏差了。我以为直接压缩成16条记录了。
感谢大佬,确实是我理解偏差了。我以为直接压缩成16条记录了。 ![]()
若业务允许,可定期将 shop_id唯一值预聚合到单独的表中(如 dim_shop),查询时直接读预聚合表,避免每次全表扫描。