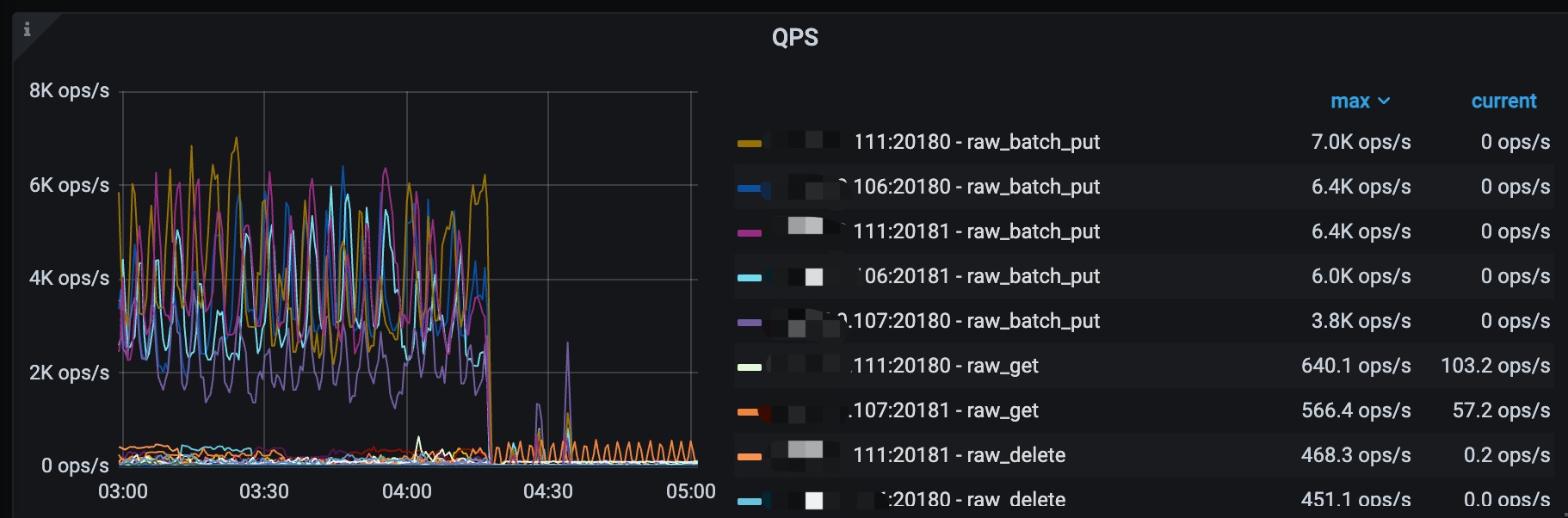
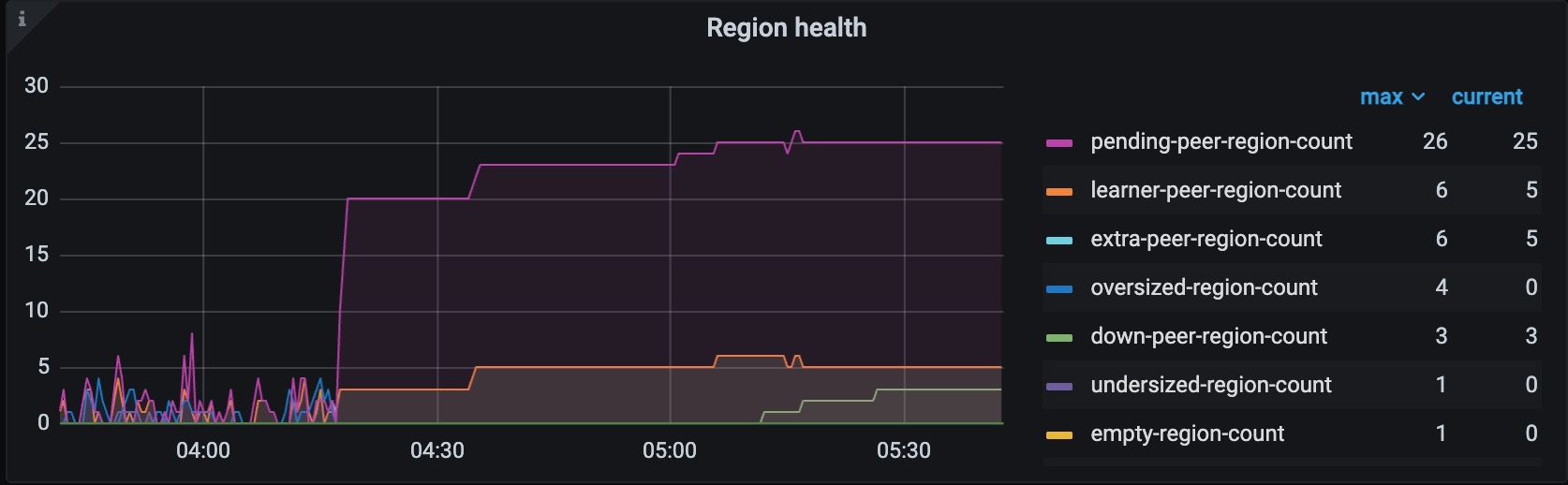
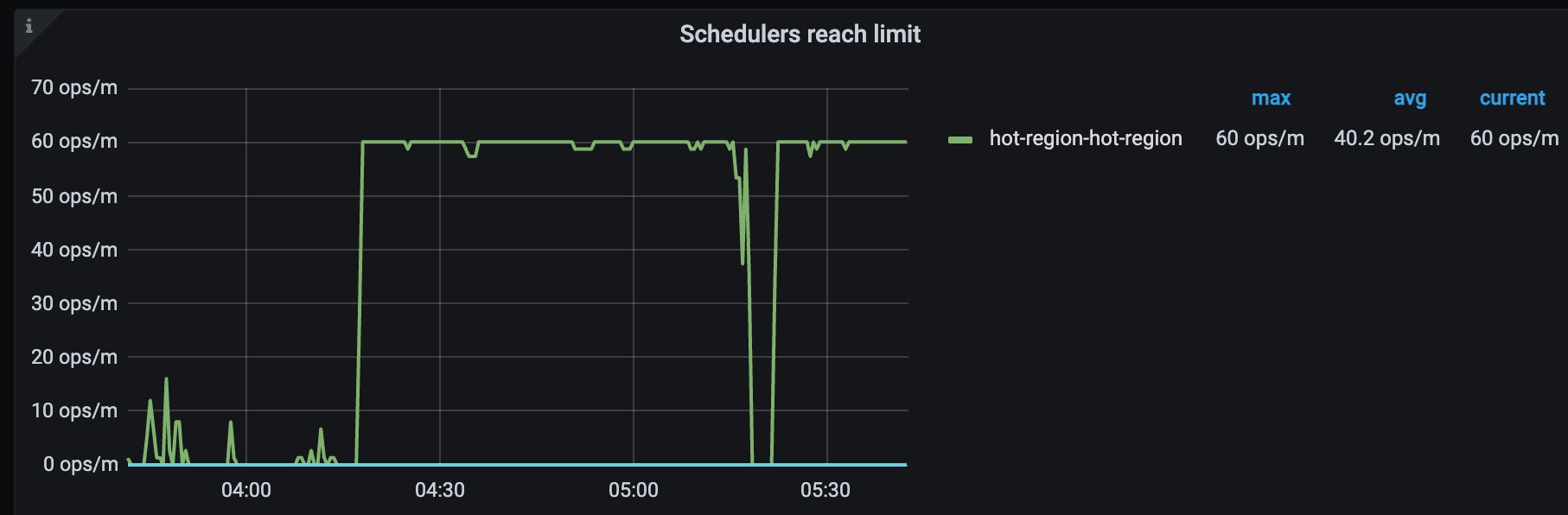
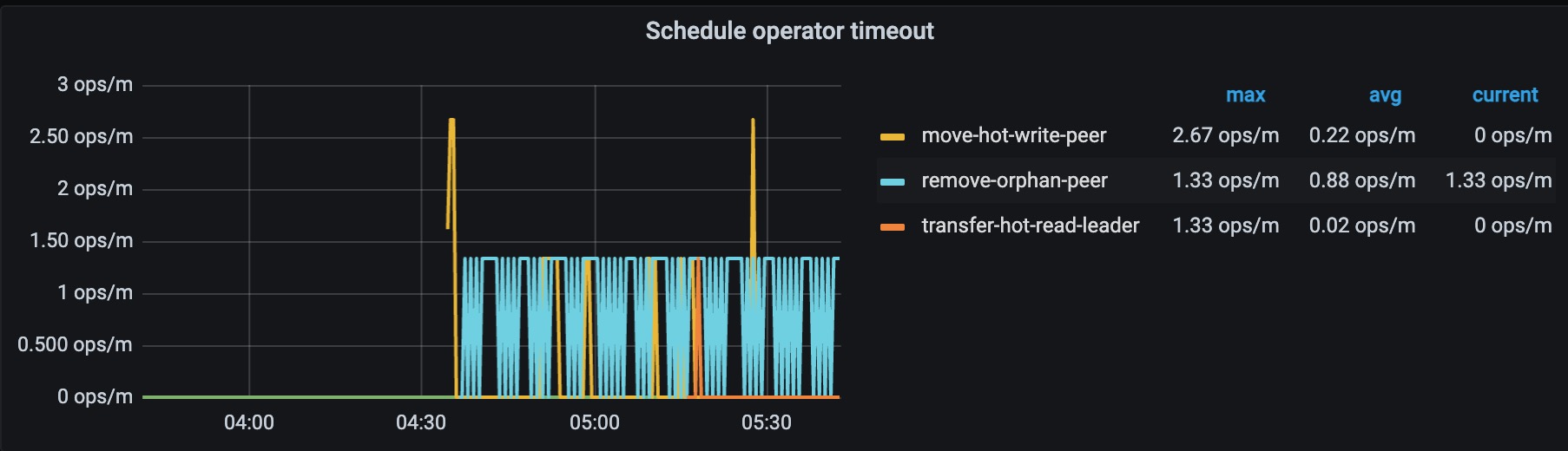
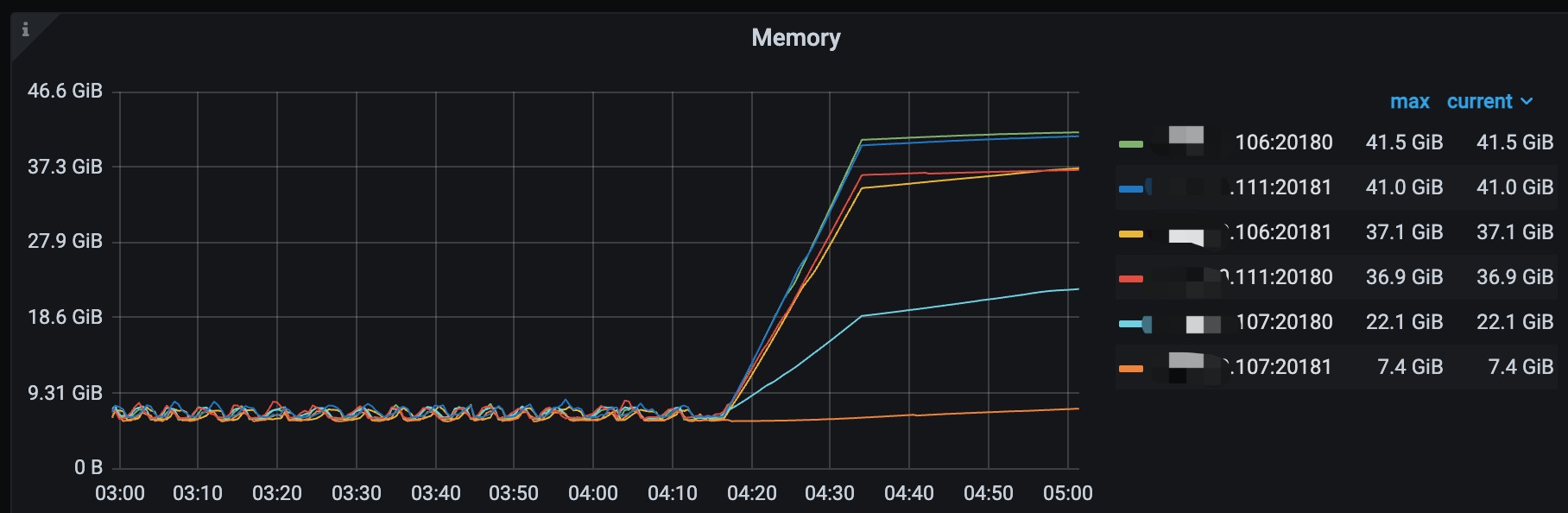
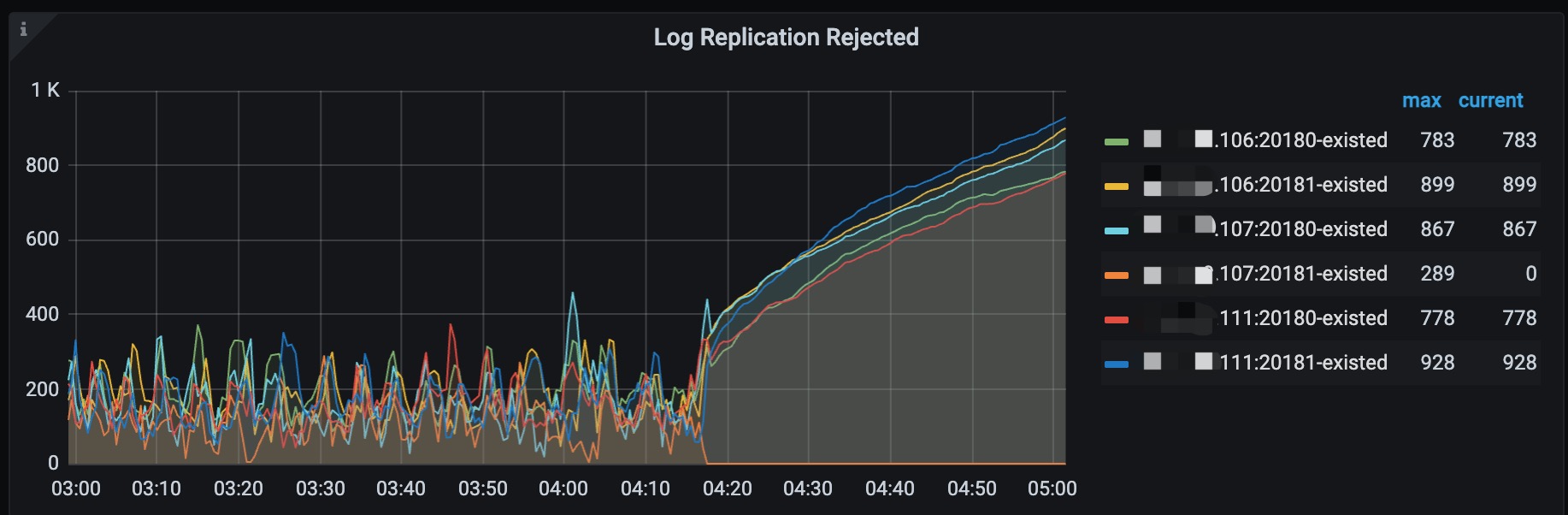
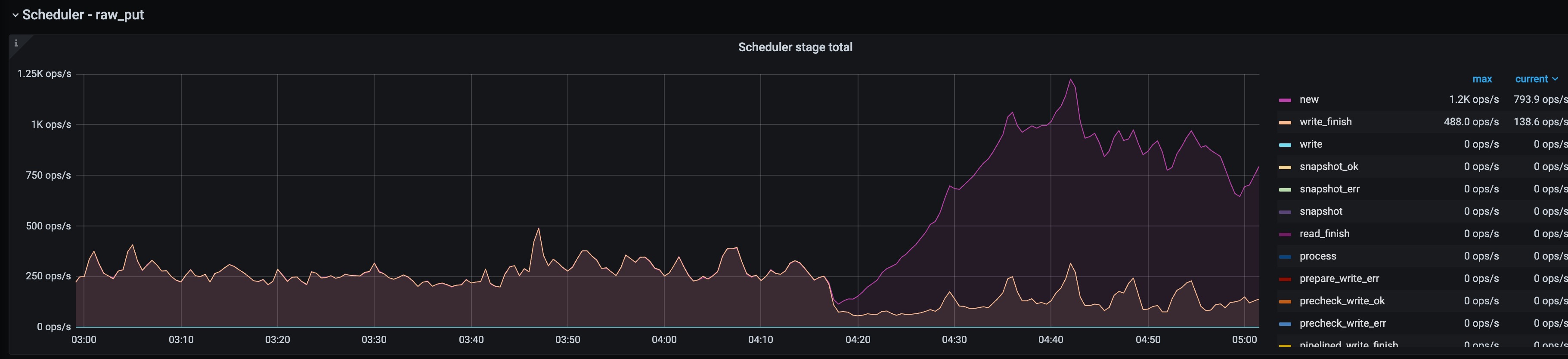
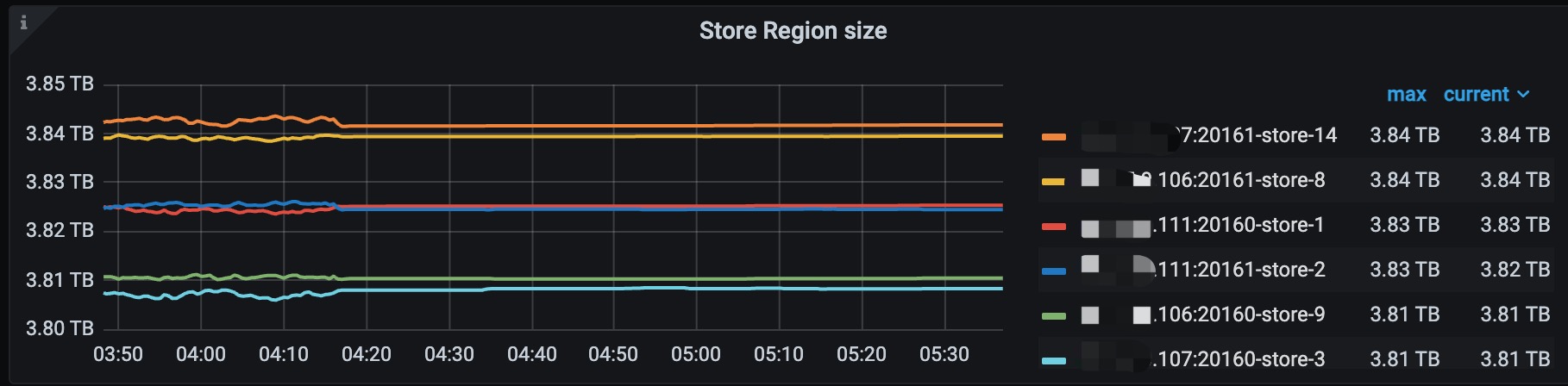
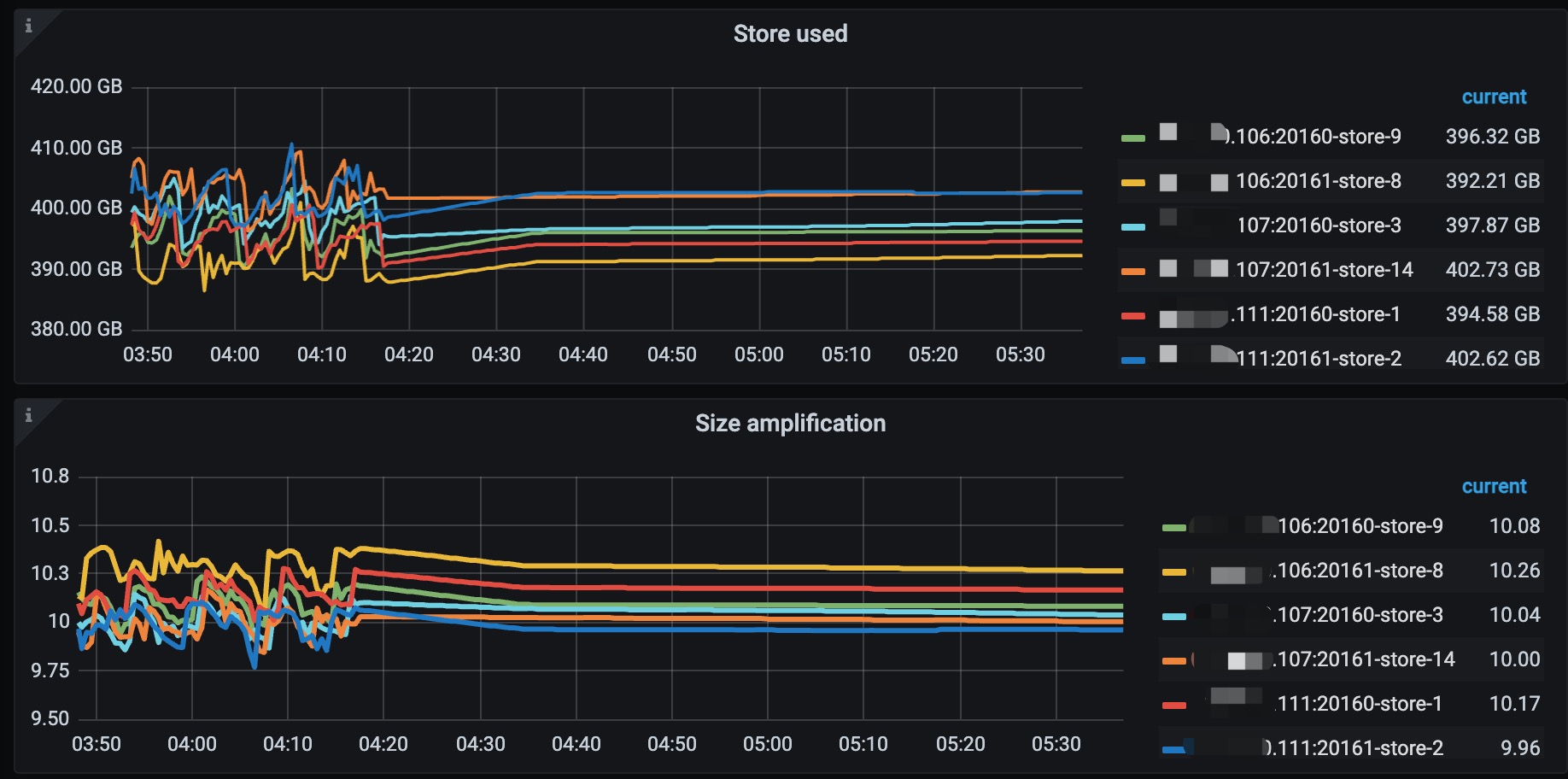
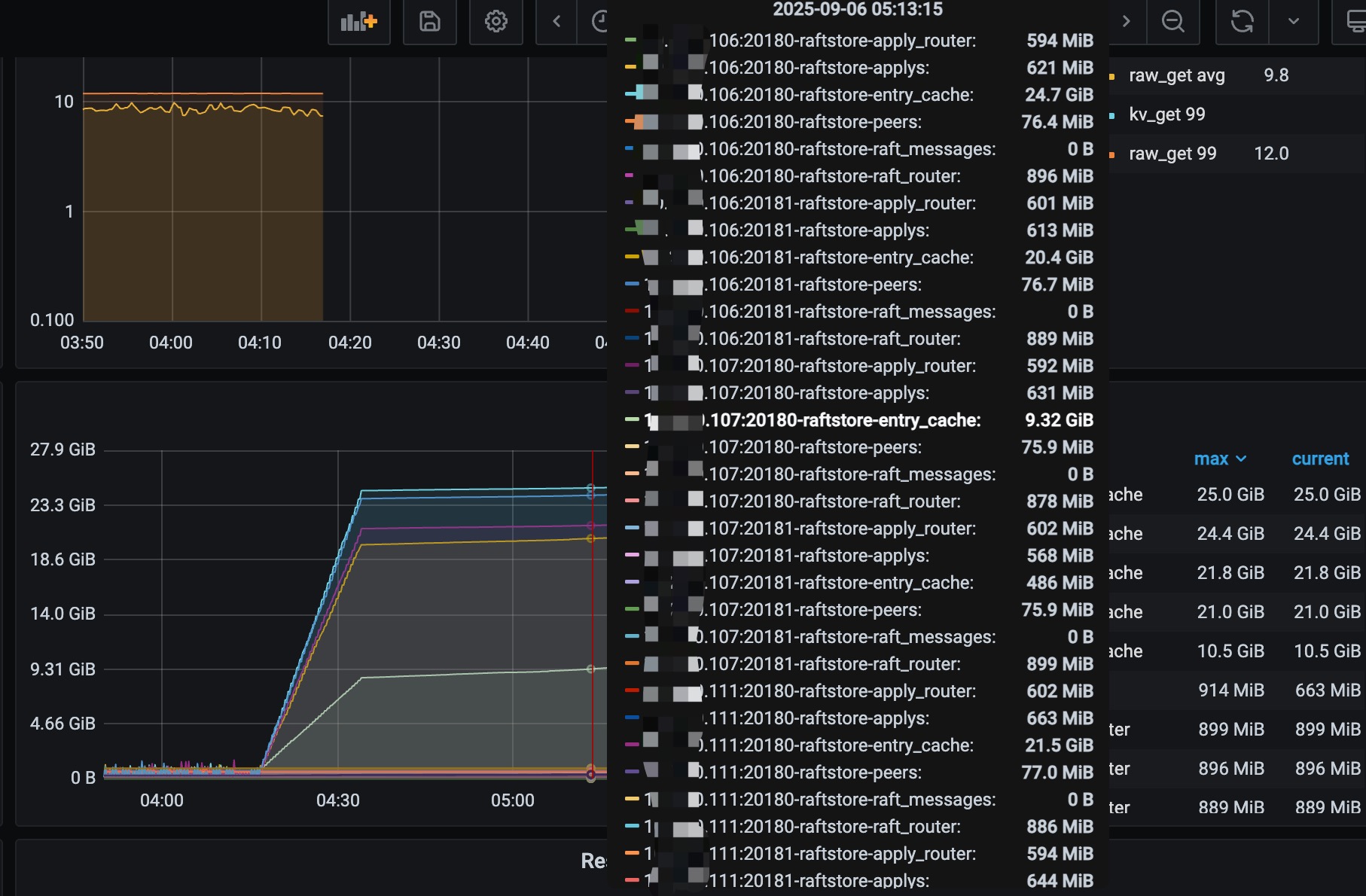
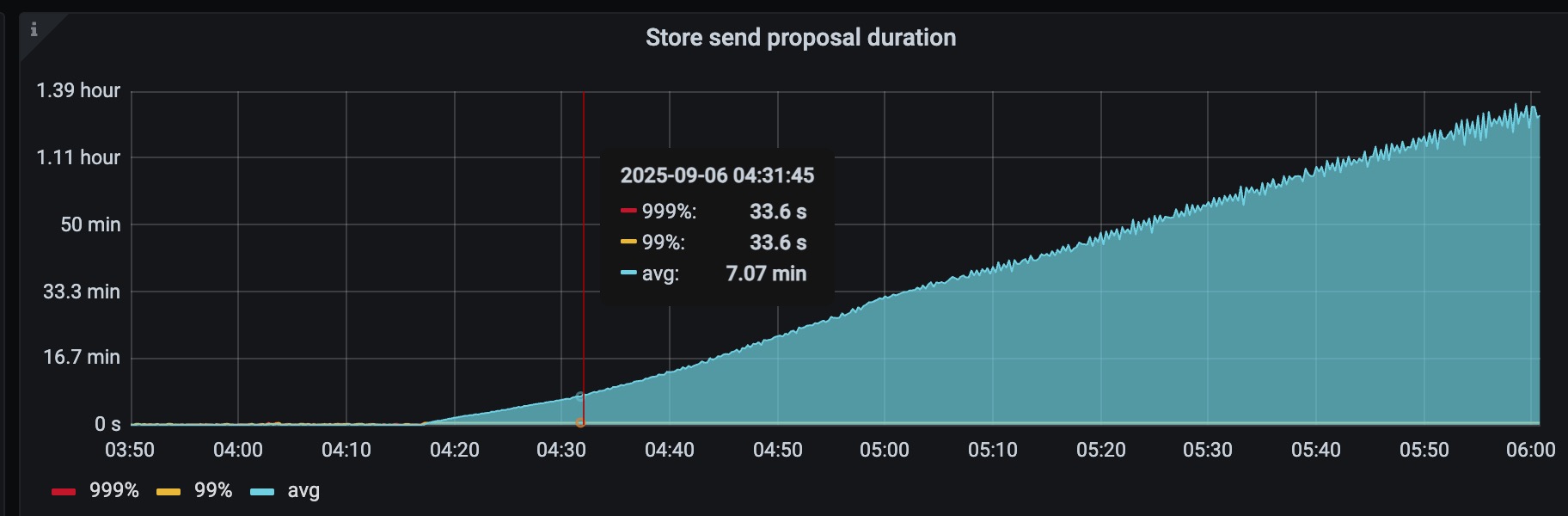
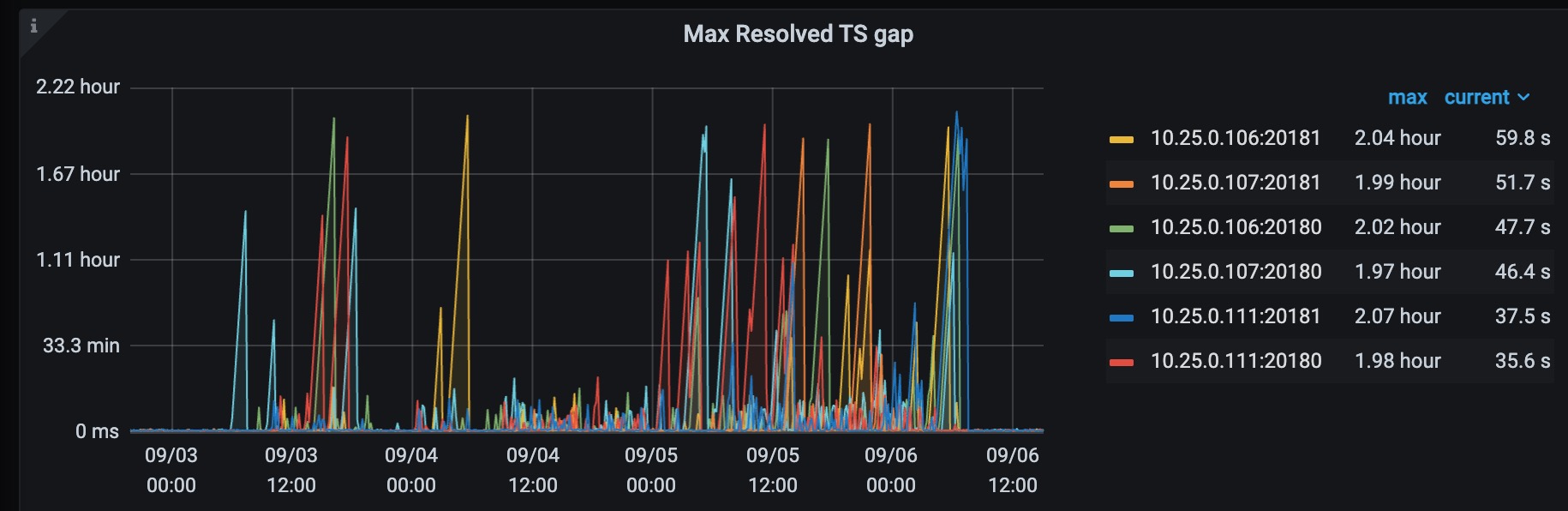
主要导出来的是04:16开始出故障那几分钟的日志,各个store的日志情况如下:
每个节点都在大量的刷:
[2025/09/06 01:19:14.458 +08:00] [ERROR] [peer.rs:614] ["handle raft message err"] [err_code=KV:Raft:StepLocalMsg] [err="Raft raft: cannot step raft local message"] [peer_id=1112637] [region_id=1088709]
下面的日志是过滤掉上述错误的
107:20180(store-3),这个节点最可疑,能明显的看到他不停的尝试新增leaner节点,但是卡住了
[2025/09/06 04:33:55.994 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[peer { id: 7444996 store_id: 9 role: Learner } change_type: AddLearnerNode]"] [region_id=7217841]
[2025/09/06 04:33:55.994 +08:00] [INFO] [peer.rs:4612] ["there is a pending conf change, try later"] [peer_id=7444511] [region_id=7217841]
最终重启该节点,恢复了集群,重启前的日志显示有两个peer pending:
[2025/09/06 06:04:30.753 +08:00] [WARN] [store.rs:1035] ["[store 3] handle 2 pending peers include 2 ready, 0 entries, 4 messages and 0 snapshots"] [takes=1629]
[2025/09/06 06:04:31.445 +08:00] [INFO] [batch.rs:648] ["batch system raftstore-3 is stopped."]
store-3的其余日志:
[2025/09/06 04:16:00.011 +08:00] [INFO] [snap.rs:271] ["saving all snapshot files"] [takes=34.891021ms] [snap_key=7251415_183_3287215]
[2025/09/06 04:16:00.011 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:00.016 +08:00] [INFO] [raft_log.rs:627] ["log [committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0] starts to restore snapshot [index: 3287215, term: 183]"] [snapshot_term=183] [snapshot_index=3287215] [log="committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0"] [raft_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.016 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7443775, 7444805, 7439679} }, outgoing: Configuration { voters: {} } }, learners: {7444898}, learners_next: {}, auto_leave: false }"] [raft_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.016 +08:00] [INFO] [raft.rs:2630] ["restored snapshot"] [snapshot_term=183] [snapshot_index=3287215] [last_term=183] [last_index=3287215] [commit=3287215] [raft_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.016 +08:00] [INFO] [raft.rs:2511] ["[commit: 3287215, term: 183] restored snapshot [index: 3287215, term: 183]"] [snapshot_term=183] [snapshot_index=3287215] [commit=3287215] [term=183] [raft_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.016 +08:00] [INFO] [peer_storage.rs:578] ["begin to apply snapshot"] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.016 +08:00] [INFO] [peer_storage.rs:661] ["apply snapshot with state ok"] [state="applied_index: 3287215 truncated_state { index: 3287215 term: 183 }"] [region="id: 7251415 start_key: region_epoch { conf_ver: 65826 version: 74 } peers { id: 7439679 store_id: 9 } peers { id: 7443775 store_id: 14 } peers { id: 7444805 store_id: 1 } peers { id: 7444898 store_id: 3 role: Learner }"] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.017 +08:00] [INFO] [peer.rs:4734] ["snapshot is persisted"] [region="id: 7251415 start_key: region_epoch { conf_ver: 65826 version: 74 } peers { id: 7439679 store_id: 9 } peers { id: 7443775 store_id: 14 } peers { id: 7444805 store_id: 1 } peers { id: 7444898 store_id: 3 role: Learner }"] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.017 +08:00] [INFO] [region.rs:441] ["begin apply snap data"] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.024 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:00.085 +08:00] [INFO] [region.rs:488] ["apply new data"] [time_takes=56.582783ms] [region_id=7251415]
[2025/09/06 04:16:00.087 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { peer { id: 7444898 store_id: 3 } } changes { change_type: AddLearnerNode peer { id: 7443775 store_id: 14 role: Learner } } }"] [index=3287216] [term=183] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.087 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65826 version: 74"] [kind=EnterJoint] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.087 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7251415 start_key: region_epoch { conf_ver: 65828 version: 74 } peers { id: 7439679 store_id: 9 } peers { id: 7443775 store_id: 14 role: DemotingVoter } peers { id: 7444805 store_id: 1 } peers { id: 7444898 store_id: 3 role: IncomingVoter }"] ["original region"="id: 7251415 start_key: region_epoch { conf_ver: 65826 version: 74 } peers { id: 7439679 store_id: 9 } peers { id: 7443775 store_id: 14 } peers { id: 7444805 store_id: 1 } peers { id: 7444898 store_id: 3 role: Learner }"] [changes="[peer { id: 7444898 store_id: 3 }, change_type: AddLearnerNode peer { id: 7443775 store_id: 14 role: Learner }]"] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.087 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444805, 7444898, 7439679} }, outgoing: Configuration { voters: {7439679, 7444805, 7443775} } }, learners: {}, learners_next: {7443775}, auto_leave: false }"] [raft_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.091 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 {}"] [index=3287217] [term=183] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.091 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65828 version: 74"] [kind=LeaveJoint] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.091 +08:00] [INFO] [apply.rs:2415] ["leave joint state successfully"] [region="id: 7251415 start_key: region_epoch { conf_ver: 65830 version: 74 } peers { id: 7439679 store_id: 9 } peers { id: 7443775 store_id: 14 role: Learner } peers { id: 7444805 store_id: 1 } peers { id: 7444898 store_id: 3 }"] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.092 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444805, 7444898, 7439679} }, outgoing: Configuration { voters: {} } }, learners: {7443775}, learners_next: {}, auto_leave: false }"] [raft_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.093 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { change_type: RemoveNode peer { id: 7443775 store_id: 14 role: Learner } } }"] [index=3287218] [term=183] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.093 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65830 version: 74"] [kind=Simple] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.093 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7251415 start_key: region_epoch { conf_ver: 65831 version: 74 } peers { id: 7439679 store_id: 9 } peers { id: 7444805 store_id: 1 } peers { id: 7444898 store_id: 3 }"] ["original region"="id: 7251415 start_key: region_epoch { conf_ver: 65830 version: 74 } peers { id: 7439679 store_id: 9 } peers { id: 7443775 store_id: 14 role: Learner } peers { id: 7444805 store_id: 1 } peers { id: 7444898 store_id: 3 }"] [changes="[change_type: RemoveNode peer { id: 7443775 store_id: 14 role: Learner }]"] [peer_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.094 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444805, 7444898, 7439679} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444898] [region_id=7251415]
[2025/09/06 04:16:00.339 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { change_type: AddLearnerNode peer { id: 7444905 store_id: 1 role: Learner } } }"] [index=1547463] [term=47] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:00.339 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65261 version: 98"] [kind=Simple] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:00.339 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7339530 start_key: region_epoch { conf_ver: 65262 version: 98 } peers { id: 7443126 store_id: 9 } peers { id: 7443752 store_id: 2 } peers { id: 7444863 store_id: 3 } peers { id: 7444905 store_id: 1 role: Learner }"] ["original region"="id: 7339530 start_key: region_epoch { conf_ver: 65261 version: 98 } peers { id: 7443126 store_id: 9 } peers { id: 7443752 store_id: 2 } peers { id: 7444863 store_id: 3 }"] [changes="[change_type: AddLearnerNode peer { id: 7444905 store_id: 1 role: Learner }]"] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:00.340 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7443752, 7444863, 7443126} }, outgoing: Configuration { voters: {} } }, learners: {7444905}, learners_next: {}, auto_leave: false }"] [raft_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.407 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { peer { id: 7444905 store_id: 1 } } changes { change_type: AddLearnerNode peer { id: 7443752 store_id: 2 role: Learner } } }"] [index=1547464] [term=47] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.407 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65262 version: 98"] [kind=EnterJoint] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.407 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7339530 start_key: region_epoch { conf_ver: 65264 version: 98 } peers { id: 7443126 store_id: 9 } peers { id: 7443752 store_id: 2 role: DemotingVoter } peers { id: 7444863 store_id: 3 } peers { id: 7444905 store_id: 1 role: IncomingVoter }"] ["original region"="id: 7339530 start_key: region_epoch { conf_ver: 65262 version: 98 } peers { id: 7443126 store_id: 9 } peers { id: 7443752 store_id: 2 } peers { id: 7444863 store_id: 3 } peers { id: 7444905 store_id: 1 role: Learner }"] [changes="[peer { id: 7444905 store_id: 1 }, change_type: AddLearnerNode peer { id: 7443752 store_id: 2 role: Learner }]"] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.407 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444863, 7444905, 7443126} }, outgoing: Configuration { voters: {7443752, 7443126, 7444863} } }, learners: {}, learners_next: {7443752}, auto_leave: false }"] [raft_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.409 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 {}"] [index=1547465] [term=47] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.409 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65264 version: 98"] [kind=LeaveJoint] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.409 +08:00] [INFO] [apply.rs:2415] ["leave joint state successfully"] [region="id: 7339530 start_key: region_epoch { conf_ver: 65266 version: 98 } peers { id: 7443126 store_id: 9 } peers { id: 7443752 store_id: 2 role: Learner } peers { id: 7444863 store_id: 3 } peers { id: 7444905 store_id: 1 }"] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.409 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444863, 7444905, 7443126} }, outgoing: Configuration { voters: {} } }, learners: {7443752}, learners_next: {}, auto_leave: false }"] [raft_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.410 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { change_type: RemoveNode peer { id: 7443752 store_id: 2 role: Learner } } }"] [index=1547466] [term=47] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.410 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65266 version: 98"] [kind=Simple] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.410 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7339530 start_key: region_epoch { conf_ver: 65267 version: 98 } peers { id: 7443126 store_id: 9 } peers { id: 7444863 store_id: 3 } peers { id: 7444905 store_id: 1 }"] ["original region"="id: 7339530 start_key: 3638353936343235323031342E706466 region_epoch { conf_ver: 65266 version: 98 } peers { id: 7443126 store_id: 9 } peers { id: 7443752 store_id: 2 role: Learner } peers { id: 7444863 store_id: 3 } peers { id: 7444905 store_id: 1 }"] [changes="[change_type: RemoveNode peer { id: 7443752 store_id: 2 role: Learner }]"] [peer_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.411 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444863, 7444905, 7443126} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444863] [region_id=7339530]
[2025/09/06 04:16:01.610 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=241764497] [region_id=7218128]
[2025/09/06 04:16:01.767 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=122589] [size=109069377] [region_id=7218128]
[2025/09/06 04:16:01.945 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=301986966] [region_id=7322408]
[2025/09/06 04:16:02.096 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=138172] [size=100663052] [region_id=7322408]
[2025/09/06 04:16:02.276 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=201324982] [region_id=7404664]
[2025/09/06 04:16:02.371 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=137978] [size=100662856] [region_id=7404664]
[2025/09/06 04:16:02.982 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=187299442] [region_id=1014895]
[2025/09/06 04:16:03.091 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=103951] [size=74832138] [region_id=1014895]
[2025/09/06 04:16:03.474 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=301986387] [region_id=7219466]
[2025/09/06 04:16:03.646 +08:00] [INFO] [peer.rs:312] ["replicate peer"] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:03.646 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:03.646 +08:00] [INFO] [raft.rs:1120] ["became follower at term 0"] [term=0] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:03.646 +08:00] [INFO] [raft.rs:384] [newRaft] [peers="Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }"] ["last term"=0] ["last index"=0] [applied=0] [commit=0] [term=0] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:03.646 +08:00] [INFO] [raw_node.rs:315] ["RawNode created with id 7444911."] [id=7444911] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:03.646 +08:00] [INFO] [raft.rs:1364] ["received a message with higher term from 7431949"] ["msg type"=MsgHeartbeat] [message_term=52] [term=0] [from=7431949] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:03.646 +08:00] [INFO] [raft.rs:1120] ["became follower at term 52"] [term=52] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:03.655 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=129201] [size=100662847] [region_id=7219466]
[2025/09/06 04:16:03.675 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=356298527] [region_id=7221921]
[2025/09/06 04:16:03.909 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=128653] [size=100662979] [region_id=7221921]
[2025/09/06 04:16:04.663 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:04.694 +08:00] [INFO] [snap.rs:263] ["saving snapshot file"] [file=/data0/tikv-data/tikv-20160/snap/rev_7337276_52_1620582_(default|lock|write).sst] [snap_key=7337276_52_1620582]
[2025/09/06 04:16:04.712 +08:00] [INFO] [snap.rs:271] ["saving all snapshot files"] [takes=48.187288ms] [snap_key=7337276_52_1620582]
[2025/09/06 04:16:04.715 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:04.719 +08:00] [INFO] [raft_log.rs:627] ["log [committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0] starts to restore snapshot [index: 1620582, term: 52]"] [snapshot_term=52] [snapshot_index=1620582] [log="committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0"] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:04.719 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7431949, 7440501, 7444841} }, outgoing: Configuration { voters: {} } }, learners: {7444911}, learners_next: {}, auto_leave: false }"] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:04.719 +08:00] [INFO] [raft.rs:2630] ["restored snapshot"] [snapshot_term=52] [snapshot_index=1620582] [last_term=52] [last_index=1620582] [commit=1620582] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:04.719 +08:00] [INFO] [raft.rs:2511] ["[commit: 1620582, term: 52] restored snapshot [index: 1620582, term: 52]"] [snapshot_term=52] [snapshot_index=1620582] [commit=1620582] [term=52] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:04.719 +08:00] [INFO] [peer_storage.rs:578] ["begin to apply snapshot"] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:04.719 +08:00] [INFO] [peer_storage.rs:661] ["apply snapshot with state ok"] [state="applied_index: 1620582 truncated_state { index: 1620582 term: 52 }"] [region="id: 7337276 start_key: 6F53937352E706466 region_epoch { conf_ver: 65334 version: 97 } peers { id: 7431949 store_id: 9 } peers { id: 7440501 store_id: 14 } peers { id: 7444841 store_id: 1 } peers { id: 7444911 store_id: 3 role: Learner }"] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:04.737 +08:00] [INFO] [peer.rs:4734] ["snapshot is persisted"] [region="id: 7337276 start_key: 6F73735F6F52E706466 region_epoch { conf_ver: 65334 version: 97 } peers { id: 7431949 store_id: 9 } peers { id: 7440501 store_id: 14 } peers { id: 7444841 store_id: 1 } peers { id: 7444911 store_id: 3 role: Learner }"] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:04.737 +08:00] [INFO] [region.rs:441] ["begin apply snap data"] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:04.743 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:04.870 +08:00] [INFO] [region.rs:488] ["apply new data"] [time_takes=122.861171ms] [region_id=7337276]
[2025/09/06 04:16:05.001 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { change_type: AddLearnerNode peer { id: 7444916 store_id: 1 role: Learner } } }"] [index=614442] [term=29] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:05.001 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 66173 version: 111"] [kind=Simple] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:05.001 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7390716 start_key: 6F7706466 region_epoch { conf_ver: 66174 version: 111 } peers { id: 7444457 store_id: 2 } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 role: Learner }"] ["original region"="id: 7390716 start_key: 6F737392E706466 region_epoch { conf_ver: 66173 version: 111 } peers { id: 7444457 store_id: 2 } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 }"] [changes="[change_type: AddLearnerNode peer { id: 7444916 store_id: 1 role: Learner }]"] [peer_id=7444566] [region_id=7390716]
2025/09/06 04:16:05.005 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444660, 7444457, 7444566} }, outgoing: Configuration { voters: {} } }, learners: {7444916}, learners_next: {}, auto_leave: false }"] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:05.021 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { peer { id: 7444911 store_id: 3 } } changes { change_type: AddLearnerNode peer { id: 7440501 store_id: 14 role: Learner } } }"] [index=1620604] [term=52] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.021 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65334 version: 97"] [kind=EnterJoint] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.021 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7337276 start_key: 6F7706466 region_epoch { conf_ver: 65336 version: 97 } peers { id: 7431949 store_id: 9 } peers { id: 7440501 store_id: 14 role: DemotingVoter } peers { id: 7444841 store_id: 1 } peers { id: 7444911 store_id: 3 role: IncomingVoter }"] ["original region"="id: 7337276 start_key: 6F72E706466 region_epoch { conf_ver: 65334 version: 97 } peers { id: 7431949 store_id: 9 } peers { id: 7440501 store_id: 14 } peers { id: 7444841 store_id: 1 } peers { id: 7444911 store_id: 3 role: Learner }"] [changes="[peer { id: 7444911 store_id: 3 }, change_type: AddLearnerNode peer { id: 7440501 store_id: 14 role: Learner }]"] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.029 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7431949, 7444911, 7444841} }, outgoing: Configuration { voters: {7431949, 7440501, 7444841} } }, learners: {}, learners_next: {7440501}, auto_leave: false }"] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.068 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 {}"] [index=1620605] [term=52] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.068 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65336 version: 97"] [kind=LeaveJoint] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.068 +08:00] [INFO] [apply.rs:2415] ["leave joint state successfully"] [region="id: 7337276 start_key: 6F2E706466 region_epoch { conf_ver: 65338 version: 97 } peers { id: 7431949 store_id: 9 } peers { id: 7440501 store_id: 14 role: Learner } peers { id: 7444841 store_id: 1 } peers { id: 7444911 store_id: 3 }"] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.075 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7431949, 7444911, 7444841} }, outgoing: Configuration { voters: {} } }, learners: {7440501}, learners_next: {}, auto_leave: false }"] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.148 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { change_type: RemoveNode peer { id: 7440501 store_id: 14 role: Learner } } }"] [index=1620606] [term=52] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.149 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65338 version: 97"] [kind=Simple] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.149 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7337276 start_key: 6F7372E706466 region_epoch { conf_ver: 65339 version: 97 } peers { id: 7431949 store_id: 9 } peers { id: 7444841 store_id: 1 } peers { id: 7444911 store_id: 3 }"] ["original region"="id: 7337276 start_key: 6F737466 region_epoch { conf_ver: 65338 version: 97 } peers { id: 7431949 store_id: 9 } peers { id: 7440501 store_id: 14 role: Learner } peers { id: 7444841 store_id: 1 } peers { id: 7444911 store_id: 3 }"] [changes="[change_type: RemoveNode peer { id: 7440501 store_id: 14 role: Learner }]"] [peer_id=7444911] [region_id=7337276]
[2025/09/06 04:16:05.157 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7431949, 7444911, 7444841} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444911] [region_id=7337276]
[2025/09/06 04:16:07.050 +08:00] [INFO] [raft.rs:2341] ["[term 29] received MsgTimeoutNow from 7444457 and starts an election to get leadership."] [from=7444457] [term=29] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.050 +08:00] [INFO] [raft.rs:1550] ["starting a new election"] [term=29] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.050 +08:00] [INFO] [raft.rs:1144] ["became candidate at term 30"] [term=30] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.050 +08:00] [INFO] [raft.rs:1299] ["broadcasting vote request"] [to="[7444660, 7444457]"] [log_index=614467] [log_term=29] [term=30] [type=MsgRequestVote] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.128 +08:00] [INFO] [raft.rs:2212] ["received votes response"] [term=30] [type=MsgRequestVoteResponse] [approvals=2] [rejections=0] [from=7444457] [vote=true] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.128 +08:00] [INFO] [raft.rs:1228] ["became leader at term 30"] [term=30] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.128 +08:00] [INFO] [peer.rs:5387] ["require updating max ts"] [initial_status=128849019102] [region_id=7390716]
[2025/09/06 04:16:07.129 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[peer { id: 7444916 store_id: 1 }, peer { id: 7444457 store_id: 2 role: Learner } change_type: AddLearnerNode]"] [region_id=7390716]
[2025/09/06 04:16:07.129 +08:00] [INFO] [pd.rs:1701] ["succeed to update max timestamp"] [region_id=7390716]
[2025/09/06 04:16:07.131 +08:00] [INFO] [peer.rs:4612] ["there is a pending conf change, try later"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.192 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[peer { id: 7444916 store_id: 1 }, peer { id: 7444457 store_id: 2 role: Learner } change_type: AddLearnerNode]"] [region_id=7390716]
[2025/09/06 04:16:07.195 +08:00] [INFO] [endpoint.rs:338] ["register observe region"] [region="id: 7390716 start_key: 6F7373392E706466 region_epoch { conf_ver: 66174 version: 111 } peers { id: 7444457 store_id: 2 } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 role: Learner }"]
[2025/09/06 04:16:07.195 +08:00] [WARN] [peer.rs:4648] ["failed to propose confchange"] [error="Other(\"[components/raftstore/src/store/util.rs:1002]: [peer { id: 7444916 store_id: 1 }, change_type: AddLearnerNode peer { id: 7444457 store_id: 2 role: Learner }]: before: voters: 7444660 voters: 7444457 voters: 7444566 learners: 7444916, after: voters: 7444660 voters: 7444566 voters: 7444916 voters_outgoing: 7444660 voters_outgoing: 7444457 voters_outgoing: 7444566 learners_next: 7444457, first index 614440, promoted commit index 0\")"]
[2025/09/06 04:16:07.195 +08:00] [INFO] [endpoint.rs:255] ["Resolver initialized"] [pending_data_index=0] [snapshot_index=614468] [observe_id=ObserveId(425044)] [region=7390716]
[2025/09/06 04:16:07.255 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[peer { id: 7444916 store_id: 1 }, peer { id: 7444457 store_id: 2 role: Learner } change_type: AddLearnerNode]"] [region_id=7390716]
[2025/09/06 04:16:07.256 +08:00] [INFO] [peer.rs:4682] ["propose conf change peer"] [kind=EnterJoint] [changes="[peer { id: 7444916 store_id: 1 }, change_type: AddLearnerNode peer { id: 7444457 store_id: 2 role: Learner }]"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.451 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { peer { id: 7444916 store_id: 1 } } changes { change_type: AddLearnerNode peer { id: 7444457 store_id: 2 role: Learner } } }"] [index=614469] [term=30] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.451 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 66174 version: 111"] [kind=EnterJoint] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.451 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7390716 start_key: 6F7373506466 region_epoch { conf_ver: 66176 version: 111 } peers { id: 7444457 store_id: 2 role: DemotingVoter } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 role: IncomingVoter }"] ["original region"="id: 7390716 start_key: 6F73735392E706466 region_epoch { conf_ver: 66174 version: 111 } peers { id: 7444457 store_id: 2 } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 role: Learner }"] [changes="[peer { id: 7444916 store_id: 1 }, change_type: AddLearnerNode peer { id: 7444457 store_id: 2 role: Learner }]"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.480 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444660, 7444566, 7444916} }, outgoing: Configuration { voters: {7444660, 7444457, 7444566} } }, learners: {}, learners_next: {7444457}, auto_leave: false }"] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.480 +08:00] [INFO] [peer.rs:3787] ["notify pd with change peer region"] [region="id: 7390716 start_key: 6F7373392E706466 region_epoch { conf_ver: 66176 version: 111 } peers { id: 7444457 store_id: 2 role: DemotingVoter } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 role: IncomingVoter }"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.492 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[]"] [region_id=7390716]
[2025/09/06 04:16:07.500 +08:00] [INFO] [peer.rs:4682] ["propose conf change peer"] [kind=LeaveJoint] [changes="[]"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.567 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=422462433] [region_id=7218236]
[2025/09/06 04:16:07.601 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[]"] [region_id=7390716]
[2025/09/06 04:16:07.607 +08:00] [INFO] [peer.rs:4612] ["there is a pending conf change, try later"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:07.866 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=117886] [size=100662566] [region_id=7218236]
[2025/09/06 04:16:07.888 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[]"] [region_id=7390716]
[2025/09/06 04:16:07.892 +08:00] [INFO] [peer.rs:4612] ["there is a pending conf change, try later"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:08.660 +08:00] [INFO] [peer_storage.rs:520] ["requesting snapshot"] [request_peer=7444368] [request_index=0] [peer_id=7444511] [region_id=7217841]
[2025/09/06 04:16:09.653 +08:00] [INFO] [io.rs:184] ["build_sst_cf_file_list builds 1 files in cf default. Total keys 138610, total size 100662989. raw_size_per_file 104857600, total takes 992.444367ms"]
[2025/09/06 04:16:09.678 +08:00] [INFO] [snap.rs:916] ["scan snapshot of one cf"] [size=100662989] [key_count=138610] [cf=default] [snapshot=/data0/tikv-data/tikv-20160/snap/gen_7217841_289_9197254_(default|lock|write).sst] [region_id=7217841]
[2025/09/06 04:16:09.678 +08:00] [INFO] [snap.rs:916] ["scan snapshot of one cf"] [size=0] [key_count=0] [cf=lock] [snapshot=/data0/tikv-data/tikv-20160/snap/gen_7217841_289_9197254_(default|lock|write).sst] [region_id=7217841]
[2025/09/06 04:16:09.678 +08:00] [INFO] [snap.rs:916] ["scan snapshot of one cf"] [size=0] [key_count=0] [cf=write] [snapshot=/data0/tikv-data/tikv-20160/snap/gen_7217841_289_9197254_(default|lock|write).sst] [region_id=7217841]
[2025/09/06 04:16:09.681 +08:00] [INFO] [snap.rs:1055] ["scan snapshot"] [takes=1.020364401s] [size=7818471] [key_count=138610] [snapshot=/data0/tikv-data/tikv-20160/snap/gen_7217841_289_9197254_(default|lock|write).sst] [region_id=7217841]
[2025/09/06 04:16:09.694 +08:00] [INFO] [peer.rs:312] ["replicate peer"] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:09.694 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:09.694 +08:00] [INFO] [raft.rs:1120] ["became follower at term 0"] [term=0] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:09.694 +08:00] [INFO] [raft.rs:384] [newRaft] [peers="Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }"] ["last term"=0] ["last index"=0] [applied=0] [commit=0] [term=0] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:09.694 +08:00] [INFO] [raw_node.rs:315] ["RawNode created with id 7444921."] [id=7444921] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:09.701 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=396511169] [region_id=7249928]
[2025/09/06 04:16:09.704 +08:00] [INFO] [raft.rs:1364] ["received a message with higher term from 7443351"] ["msg type"=MsgHeartbeat] [message_term=39] [term=0] [from=7443351] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:09.705 +08:00] [INFO] [raft.rs:1120] ["became follower at term 39"] [term=39] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:09.732 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:09.788 +08:00] [INFO] [snap.rs:452] ["sent snapshot"] [duration=53.357959ms] [size=7818471] [snap_key=7217841_289_9197254] [region_id=7217841]
[2025/09/06 04:16:09.797 +08:00] [INFO] [peer.rs:1921] ["report snapshot status"] [status=Finish] [to="id: 7444368 store_id: 8"] [peer_id=7444511] [region_id=7217841]
[2025/09/06 04:16:09.972 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=138454] [size=100662602] [region_id=7249928]
[2025/09/06 04:16:09.996 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[]"] [region_id=7390716]
[2025/09/06 04:16:09.998 +08:00] [INFO] [peer.rs:4612] ["there is a pending conf change, try later"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:11.157 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:11.195 +08:00] [INFO] [snap.rs:263] ["saving snapshot file"] [file=/data0/tikv-data/tikv-20160/snap/rev_7351569_39_1262558_(default|lock|write).sst] [snap_key=7351569_39_1262558]
[2025/09/06 04:16:11.211 +08:00] [INFO] [snap.rs:271] ["saving all snapshot files"] [takes=54.412403ms] [snap_key=7351569_39_1262558]
[2025/09/06 04:16:11.221 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:11.226 +08:00] [INFO] [raft_log.rs:627] ["log [committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0] starts to restore snapshot [index: 1262558, term: 39]"] [snapshot_term=39] [snapshot_index=1262558] [log="committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0"] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.226 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444649, 7442238, 7443351} }, outgoing: Configuration { voters: {} } }, learners: {7444921}, learners_next: {}, auto_leave: false }"] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.226 +08:00] [INFO] [raft.rs:2630] ["restored snapshot"] [snapshot_term=39] [snapshot_index=1262558] [last_term=39] [last_index=1262558] [commit=1262558] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.226 +08:00] [INFO] [raft.rs:2511] ["[commit: 1262558, term: 39] restored snapshot [index: 1262558, term: 39]"] [snapshot_term=39] [snapshot_index=1262558] [commit=1262558] [term=39] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.226 +08:00] [INFO] [peer_storage.rs:578] ["begin to apply snapshot"] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.226 +08:00] [INFO] [peer_storage.rs:661] ["apply snapshot with state ok"] [state="applied_index: 1262558 truncated_state { index: 1262558 term: 39 }"] [region="id: 7351569 start_key: 6F73735F6F626706466 region_epoch { conf_ver: 65412 version: 102 } peers { id: 7442238 store_id: 9 } peers { id: 7443351 store_id: 2 } peers { id: 7444649 store_id: 14 } peers { id: 7444921 store_id: 3 role: Learner }"] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.268 +08:00] [INFO] [peer.rs:4734] ["snapshot is persisted"] [region="id: 7351569 start_key: 6F7373506466 end_key: 6F7373392E706466 region_epoch { conf_ver: 65412 version: 102 } peers { id: 7442238 store_id: 9 } peers { id: 7443351 store_id: 2 } peers { id: 7444649 store_id: 14 } peers { id: 7444921 store_id: 3 role: Learner }"] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.268 +08:00] [INFO] [region.rs:441] ["begin apply snap data"] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.273 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:11.398 +08:00] [INFO] [region.rs:488] ["apply new data"] [time_takes=123.0721ms] [region_id=7351569]
[2025/09/06 04:16:11.496 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { peer { id: 7444921 store_id: 3 } } changes { change_type: AddLearnerNode peer { id: 7444649 store_id: 14 role: Learner } } }"] [index=1262571] [term=39] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.496 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65412 version: 102"] [kind=EnterJoint] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.496 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7351569 start_key: 6F706466 region_epoch { conf_ver: 65414 version: 102 } peers { id: 7442238 store_id: 9 } peers { id: 7443351 store_id: 2 } peers { id: 7444649 store_id: 14 role: DemotingVoter } peers { id: 7444921 store_id: 3 role: IncomingVoter }"] ["original region"="id: 7351569 start_key: 6F7392E706466 region_epoch { conf_ver: 65412 version: 102 } peers { id: 7442238 store_id: 9 } peers { id: 7443351 store_id: 2 } peers { id: 7444649 store_id: 14 } peers { id: 7444921 store_id: 3 role: Learner }"] [changes="[peer { id: 7444921 store_id: 3 }, change_type: AddLearnerNode peer { id: 7444649 store_id: 14 role: Learner }]"] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.505 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7443351, 7442238, 7444921} }, outgoing: Configuration { voters: {7444649, 7442238, 7443351} } }, learners: {}, learners_next: {7444649}, auto_leave: false }"] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.533 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 {}"] [index=1262572] [term=39] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.533 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65414 version: 102"] [kind=LeaveJoint] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.533 +08:00] [INFO] [apply.rs:2415] ["leave joint state successfully"] [region="id: 7351569 start_key: 6F7343330392E706466 region_epoch { conf_ver: 65416 version: 102 } peers { id: 7442238 store_id: 9 } peers { id: 7443351 store_id: 2 } peers { id: 7444649 store_id: 14 role: Learner } peers { id: 7444921 store_id: 3 }"] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.537 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7443351, 7442238, 7444921} }, outgoing: Configuration { voters: {} } }, learners: {7444649}, learners_next: {}, auto_leave: false }"] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:11.612 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=296296762] [region_id=7218128]
[2025/09/06 04:16:11.847 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=122589] [size=109069377] [region_id=7218128]
[2025/09/06 04:16:11.947 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=404811213] [region_id=7322408]
[2025/09/06 04:16:12.163 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=138172] [size=100663052] [region_id=7322408]
[2025/09/06 04:16:12.277 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=301987108] [region_id=7404664]
[2025/09/06 04:16:12.414 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=137978] [size=100662856] [region_id=7404664]
[2025/09/06 04:16:12.493 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[]"] [region_id=7390716]
[2025/09/06 04:16:12.493 +08:00] [INFO] [peer.rs:4612] ["there is a pending conf change, try later"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:12.984 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=241833819] [region_id=1014895]
[2025/09/06 04:16:13.149 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=103951] [size=74832138] [region_id=1014895]
[2025/09/06 04:16:13.458 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { change_type: RemoveNode peer { id: 7444649 store_id: 14 role: Learner } } }"] [index=1262573] [term=39] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:13.458 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65416 version: 102"] [kind=Simple] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:13.458 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7351569 start_key: 6F7373706466 region_epoch { conf_ver: 65417 version: 102 } peers { id: 7442238 store_id: 9 } peers { id: 7443351 store_id: 2 } peers { id: 7444921 store_id: 3 }"] ["original region"="id: 7351569 start_key: 6F7338343330392E706466 region_epoch { conf_ver: 65416 version: 102 } peers { id: 7442238 store_id: 9 } peers { id: 7443351 store_id: 2 } peers { id: 7444649 store_id: 14 role: Learner } peers { id: 7444921 store_id: 3 }"] [changes="[change_type: RemoveNode peer { id: 7444649 store_id: 14 role: Learner }]"] [peer_id=7444921] [region_id=7351569]
[2025/09/06 04:16:13.459 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7443351, 7442238, 7444921} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444921] [region_id=7351569]
[2025/09/06 04:16:13.476 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=406855451] [region_id=7219466]
[2025/09/06 04:16:13.714 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=129201] [size=100662847] [region_id=7219466]
[2025/09/06 04:16:14.451 +08:00] [INFO] [peer.rs:312] ["replicate peer"] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:14.451 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:14.451 +08:00] [INFO] [raft.rs:1120] ["became follower at term 0"] [term=0] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:14.451 +08:00] [INFO] [raft.rs:384] [newRaft] [peers="Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }"] ["last term"=0] ["last index"=0] [applied=0] [commit=0] [term=0] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:14.451 +08:00] [INFO] [raw_node.rs:315] ["RawNode created with id 7444927."] [id=7444927] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:14.451 +08:00] [INFO] [raft.rs:1364] ["received a message with higher term from 7440507"] ["msg type"=MsgHeartbeat] [message_term=92] [term=0] [from=7440507] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:14.451 +08:00] [INFO] [raft.rs:1120] ["became follower at term 92"] [term=92] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:14.493 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[]"] [region_id=7390716]
[2025/09/06 04:16:14.494 +08:00] [INFO] [peer.rs:4612] ["there is a pending conf change, try later"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:14.544 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=400875302] [region_id=7217841]
[2025/09/06 04:16:14.766 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=138610] [size=100662989] [region_id=7217841]
[2025/09/06 04:16:15.082 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=301987878] [region_id=7331699]
[2025/09/06 04:16:15.092 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 {}"] [index=614470] [term=30] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:15.092 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 66176 version: 111"] [kind=LeaveJoint] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:15.092 +08:00] [INFO] [apply.rs:2415] ["leave joint state successfully"] [region="id: 7390716 start_key: 6F73735F6F06466 region_epoch { conf_ver: 66178 version: 111 } peers { id: 7444457 store_id: 2 role: Learner } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 }"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:15.092 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[]"] [region_id=7390716]
[2025/09/06 04:16:15.093 +08:00] [INFO] [peer.rs:4612] ["there is a pending conf change, try later"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:15.097 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444660, 7444566, 7444916} }, outgoing: Configuration { voters: {} } }, learners: {7444457}, learners_next: {}, auto_leave: false }"] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:15.097 +08:00] [INFO] [peer.rs:3787] ["notify pd with change peer region"] [region="id: 7390716 start_key: 6F737353035392E706466 region_epoch { conf_ver: 66178 version: 111 } peers { id: 7444457 store_id: 2 role: Learner } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 }"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:15.099 +08:00] [INFO] [pd.rs:1508] ["try to change peer"] [changes="[peer { id: 7444457 store_id: 2 role: Learner } change_type: RemoveNode]"] [region_id=7390716]
[2025/09/06 04:16:15.099 +08:00] [INFO] [peer.rs:4682] ["propose conf change peer"] [kind=Simple] [changes="[change_type: RemoveNode peer { id: 7444457 store_id: 2 role: Learner }]"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:15.257 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=138181] [size=100662626] [region_id=7331699]
[2025/09/06 04:16:15.434 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:15.472 +08:00] [INFO] [snap.rs:263] ["saving snapshot file"] [file=/data0/tikv-data/tikv-20160/snap/rev_7245948_213_3795558_(default|lock|write).sst] [snap_key=7245948_213_3795558]
[2025/09/06 04:16:15.478 +08:00] [INFO] [snap.rs:271] ["saving all snapshot files"] [takes=43.609559ms] [snap_key=7245948_213_3795558]
[2025/09/06 04:16:15.478 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:15.483 +08:00] [INFO] [raft_log.rs:627] ["log [committed=3795038, persisted=3795038, applied=3795038, unstable.offset=3795039, unstable.entries.len()=0] starts to restore snapshot [index: 3795558, term: 213]"] [snapshot_term=213] [snapshot_index=3795558] [log="committed=3795038, persisted=3795038, applied=3795038, unstable.offset=3795039, unstable.entries.len()=0"] [raft_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.483 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444538, 7444890, 7444835} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.483 +08:00] [INFO] [raft.rs:2630] ["restored snapshot"] [snapshot_term=213] [snapshot_index=3795558] [last_term=213] [last_index=3795558] [commit=3795558] [raft_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.483 +08:00] [INFO] [raft.rs:2511] ["[commit: 3795558, term: 213] restored snapshot [index: 3795558, term: 213]"] [snapshot_term=213] [snapshot_index=3795558] [commit=3795558] [term=213] [raft_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.483 +08:00] [INFO] [peer_storage.rs:578] ["begin to apply snapshot"] [peer_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.483 +08:00] [INFO] [peer_storage.rs:1018] ["finish clear peer meta"] [takes=26.698µs] [raft_key=1] [apply_key=1] [meta_key=1] [region_id=7245948]
[2025/09/06 04:16:15.483 +08:00] [INFO] [peer_storage.rs:661] ["apply snapshot with state ok"] [state="applied_index: 3795558 commit_index: 3795038 commit_term: 213 truncated_state { index: 3795558 term: 213 }"] [region="id: 7245948 start_key: 6F7372E706466 region_epoch { conf_ver: 65801 version: 67 } peers { id: 7444538 store_id: 1 } peers { id: 7444835 store_id: 8 } peers { id: 7444890 store_id: 3 }"] [peer_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.486 +08:00] [INFO] [apply.rs:3583] ["re-register to apply delegates"] [term=213] [peer_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.486 +08:00] [INFO] [region_info_accessor.rs:294] ["trying to create region but it already exists, try to update it"] [region_id=7245948]
[2025/09/06 04:16:15.486 +08:00] [INFO] [peer.rs:4734] ["snapshot is persisted"] [region="id: 7245948 start_key: 6F73735832393734382E706466 region_epoch { conf_ver: 65801 version: 67 } peers { id: 7444538 store_id: 1 } peers { id: 7444835 store_id: 8 } peers { id: 7444890 store_id: 3 }"] [peer_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.486 +08:00] [INFO] [peer.rs:4793] ["region changed after persisting snapshot"] [region="id: 7245948 start_key: 6F73733734382E706466 region_epoch { conf_ver: 65801 version: 67 } peers { id: 7444538 store_id: 1 } peers { id: 7444835 store_id: 8 } peers { id: 7444890 store_id: 3 }"] [prev_region="id: 7245948 start_key: 6F73735F6F6E706466 region_epoch { conf_ver: 65801 version: 67 } peers { id: 7444538 store_id: 1 } peers { id: 7444835 store_id: 8 } peers { id: 7444890 store_id: 3 }"] [peer_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.487 +08:00] [INFO] [region.rs:441] ["begin apply snap data"] [peer_id=7444890] [region_id=7245948]
[2025/09/06 04:16:15.681 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:15.782 +08:00] [INFO] [region.rs:488] ["apply new data"] [time_takes=99.022639ms] [region_id=7245948]
[2025/09/06 04:16:16.014 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:16.040 +08:00] [INFO] [snap.rs:263] ["saving snapshot file"] [file=/data0/tikv-data/tikv-20160/snap/rev_7265961_150_2925030_(default|lock|write).sst] [snap_key=7265961_150_2925030]
[2025/09/06 04:16:16.044 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { change_type: RemoveNode peer { id: 7444457 store_id: 2 role: Learner } } }"] [index=614959] [term=30] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:16.044 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 66178 version: 111"] [kind=Simple] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:16.045 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7390716 start_key: 6F73735F6F38373238303035392E706466 region_epoch { conf_ver: 66179 version: 111 } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 }"] ["original region"="id: 7390716 start_key: 6F73735F6F373238303035392E706466 region_epoch { conf_ver: 66178 version: 111 } peers { id: 7444457 store_id: 2 role: Learner } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 }"] [changes="[change_type: RemoveNode peer { id: 7444457 store_id: 2 role: Learner }]"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:16.063 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444660, 7444566, 7444916} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444566] [region_id=7390716]
[2025/09/06 04:16:16.063 +08:00] [INFO] [peer.rs:3787] ["notify pd with change peer region"] [region="id: 7390716 start_key: 6F73735F6F3238303035392E706466 region_epoch { conf_ver: 66179 version: 111 } peers { id: 7444566 store_id: 3 } peers { id: 7444660 store_id: 9 } peers { id: 7444916 store_id: 1 }"] [peer_id=7444566] [region_id=7390716]
[2025/09/06 04:16:16.064 +08:00] [INFO] [snap.rs:271] ["saving all snapshot files"] [takes=50.321203ms] [snap_key=7265961_150_2925030]
[2025/09/06 04:16:16.064 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:16.070 +08:00] [INFO] [raft_log.rs:627] ["log [committed=2924554, persisted=2924554, applied=2924554, unstable.offset=2924555, unstable.entries.len()=0] starts to restore snapshot [index: 2925030, term: 150]"] [snapshot_term=150] [snapshot_index=2925030] [log="committed=2924554, persisted=2924554, applied=2924554, unstable.offset=2924555, unstable.entries.len()=0"] [raft_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.070 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444397, 7442004, 7444603} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.070 +08:00] [INFO] [raft_log.rs:627] ["log [committed=2924554, persisted=2924554, applied=2924554, unstable.offset=2924555, unstable.entries.len()=0] starts to restore snapshot [index: 2925030, term: 150]"] [snapshot_term=150] [snapshot_index=2925030] [log="committed=2924554, persisted=2924554, applied=2924554, unstable.offset=2924555, unstable.entries.len()=0"] [raft_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.070 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7444397, 7442004, 7444603} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.070 +08:00] [INFO] [raft.rs:2630] ["restored snapshot"] [snapshot_term=150] [snapshot_index=2925030] [last_term=150] [last_index=2925030] [commit=2925030] [raft_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.070 +08:00] [INFO] [raft.rs:2511] ["[commit: 2925030, term: 150] restored snapshot [index: 2925030, term: 150]"] [snapshot_term=150] [snapshot_index=2925030] [commit=2925030] [term=150] [raft_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.070 +08:00] [INFO] [peer_storage.rs:578] ["begin to apply snapshot"] [peer_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.070 +08:00] [INFO] [peer_storage.rs:1018] ["finish clear peer meta"] [takes=5.804µs] [raft_key=1] [apply_key=1] [meta_key=1] [region_id=7265961]
[2025/09/06 04:16:16.070 +08:00] [INFO] [peer_storage.rs:661] ["apply snapshot with state ok"] [state="applied_index: 2925030 commit_index: 2924554 commit_term: 150 truncated_state { index: 2925030 term: 150 }"] [region="id: 7265961 start_key: 6F73735F6F626A72E706466 region_epoch { conf_ver: 65789 version: 79 } peers { id: 7442004 store_id: 1 } peers { id: 7444397 store_id: 3 } peers { id: 7444603 store_id: 8 }"] [peer_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.077 +08:00] [INFO] [region_info_accessor.rs:294] ["trying to create region but it already exists, try to update it"] [region_id=7265961]
[2025/09/06 04:16:16.077 +08:00] [INFO] [peer.rs:4734] ["snapshot is persisted"] [region="id: 7265961 start_key: 6F737313436372E706466 region_epoch { conf_ver: 65789 version: 79 } peers { id: 7442004 store_id: 1 } peers { id: 7444397 store_id: 3 } peers { id: 7444603 store_id: 8 }"] [peer_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.077 +08:00] [INFO] [peer.rs:4793] ["region changed after persisting snapshot"] [region="id: 7265961 start_key: 6F73735F313436372E706466 region_epoch { conf_ver: 65789 version: 79 } peers { id: 7442004 store_id: 1 } peers { id: 7444397 store_id: 3 } peers { id: 7444603 store_id: 8 }"] [prev_region="id: 7265961 start_key: 6F73735F63436372E706466 region_epoch { conf_ver: 65789 version: 79 } peers { id: 7442004 store_id: 1 } peers { id: 7444397 store_id: 3 } peers { id: 7444603 store_id: 8 }"] [peer_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.077 +08:00] [INFO] [apply.rs:3583] ["re-register to apply delegates"] [term=150] [peer_id=7444397] [region_id=7265961]
[2025/09/06 04:16:16.911 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:16.944 +08:00] [INFO] [snap.rs:263] ["saving snapshot file"] [file=/data0/tikv-data/tikv-20160/snap/rev_7297670_92_2489525_(default|lock|write).sst] [snap_key=7297670_92_2489525]
[2025/09/06 04:16:16.967 +08:00] [INFO] [snap.rs:271] ["saving all snapshot files"] [takes=56.364218ms] [snap_key=7297670_92_2489525]
[2025/09/06 04:16:16.968 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:16.973 +08:00] [INFO] [raft_log.rs:627] ["log [committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0] starts to restore snapshot [index: 2489525, term: 92]"] [snapshot_term=92] [snapshot_index=2489525] [log="committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0"] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:16.973 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7438221, 7441402, 7440507} }, outgoing: Configuration { voters: {} } }, learners: {7444927}, learners_next: {}, auto_leave: false }"] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:16.973 +08:00] [INFO] [raft.rs:2630] ["restored snapshot"] [snapshot_term=92] [snapshot_index=2489525] [last_term=92] [last_index=2489525] [commit=2489525] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:16.973 +08:00] [INFO] [raft.rs:2511] ["[commit: 2489525, term: 92] restored snapshot [index: 2489525, term: 92]"] [snapshot_term=92] [snapshot_index=2489525] [commit=2489525] [term=92] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:16.973 +08:00] [INFO] [peer_storage.rs:578] ["begin to apply snapshot"] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:16.973 +08:00] [INFO] [peer_storage.rs:661] ["apply snapshot with state ok"] [state="applied_index: 2489525 truncated_state { index: 2489525 term: 92 }"] [region="id: 7297670 start_key: 6F73735F63833373939362E706466 region_epoch { conf_ver: 65070 version: 85 } peers { id: 7438221 store_id: 14 } peers { id: 7440507 store_id: 8 } peers { id: 7441402 store_id: 2 } peers { id: 7444927 store_id: 3 role: Learner }"] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:16.976 +08:00] [INFO] [peer.rs:4734] ["snapshot is persisted"] [region="id: 7297670 start_key: 6F73733833373939362E706466 region_epoch { conf_ver: 65070 version: 85 } peers { id: 7438221 store_id: 14 } peers { id: 7440507 store_id: 8 } peers { id: 7441402 store_id: 2 } peers { id: 7444927 store_id: 3 role: Learner }"] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:17.130 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=314571146] [region_id=7390716]
[2025/09/06 04:16:17.288 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=137978] [size=100662724] [region_id=7390716]
[2025/09/06 04:16:19.343 +08:00] [INFO] [peer.rs:312] ["replicate peer"] [peer_id=7444932] [region_id=7217664]
[2025/09/06 04:16:19.343 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:19.343 +08:00] [INFO] [raft.rs:1120] ["became follower at term 0"] [term=0] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:19.343 +08:00] [INFO] [raft.rs:384] [newRaft] [peers="Configuration { incoming: Configuration { voters: {} }, outgoing: Configuration { voters: {} } }"] ["last term"=0] ["last index"=0] [applied=0] [commit=0] [term=0] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:19.343 +08:00] [INFO] [raw_node.rs:315] ["RawNode created with id 7444932."] [id=7444932] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:19.343 +08:00] [INFO] [raft.rs:1364] ["received a message with higher term from 7442424"] ["msg type"=MsgHeartbeat] [message_term=329] [term=0] [from=7442424] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:19.343 +08:00] [INFO] [raft.rs:1120] ["became follower at term 329"] [term=329] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:19.703 +08:00] [INFO] [size.rs:202] ["Run size checker"] [policy=Scan] [threshold=150994944] [size=402951182] [region_id=7249928]
[2025/09/06 04:16:19.910 +08:00] [INFO] [split_check.rs:590] ["update approximate size and keys with accurate value"] [bucket_size=0] [bucket_count=0] [keys=138454] [size=100662602] [region_id=7249928]
[2025/09/06 04:16:20.238 +08:00] [INFO] [region.rs:441] ["begin apply snap data"] [peer_id=7444397] [region_id=7265961]
[2025/09/06 04:16:20.500 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:20.519 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:20.548 +08:00] [INFO] [snap.rs:263] ["saving snapshot file"] [file=/data0/tikv-data/tikv-20160/snap/rev_7217664_329_9929520_(default|lock|write).sst] [snap_key=7217664_329_9929520]
[2025/09/06 04:16:20.553 +08:00] [INFO] [snap.rs:271] ["saving all snapshot files"] [takes=34.113063ms] [snap_key=7217664_329_9929520]
[2025/09/06 04:16:20.553 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:20.553 +08:00] [INFO] [region.rs:488] ["apply new data"] [time_takes=51.48651ms] [region_id=7265961]
[2025/09/06 04:16:20.559 +08:00] [INFO] [raft_log.rs:627] ["log [committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0] starts to restore snapshot [index: 9929520, term: 329]"] [snapshot_term=329] [snapshot_index=9929520] [log="committed=0, persisted=0, applied=0, unstable.offset=1, unstable.entries.len()=0"] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.559 +08:00] [INFO] [region.rs:441] ["begin apply snap data"] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.559 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7442424, 7440593, 7443844} }, outgoing: Configuration { voters: {} } }, learners: {7444932}, learners_next: {}, auto_leave: false }"] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.559 +08:00] [INFO] [raft.rs:2630] ["restored snapshot"] [snapshot_term=329] [snapshot_index=9929520] [last_term=329] [last_index=9929520] [commit=9929520] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.559 +08:00] [INFO] [raft.rs:2511] ["[commit: 9929520, term: 329] restored snapshot [index: 9929520, term: 329]"] [snapshot_term=329] [snapshot_index=9929520] [commit=9929520] [term=329] [raft_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.559 +08:00] [INFO] [peer_storage.rs:578] ["begin to apply snapshot"] [peer_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.559 +08:00] [INFO] [peer_storage.rs:661] ["apply snapshot with state ok"] [state="applied_index: 9929520 truncated_state { index: 9929520 term: 329 }"] [region="id: 7217664 start_key: 6F73735F6F6466 region_epoch { conf_ver: 82062 version: 85 } peers { id: 7440593 store_id: 14 } peers { id: 7442424 store_id: 9 } peers { id: 7443844 store_id: 1 } peers { id: 7444932 store_id: 3 role: Learner }"] [peer_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.559 +08:00] [INFO] [peer.rs:4734] ["snapshot is persisted"] [region="id: 7217664 start_key: 6F73735F6F626A5F43035302E706466 region_epoch { conf_ver: 82062 version: 85 } peers { id: 7440593 store_id: 14 } peers { id: 7442424 store_id: 9 } peers { id: 7443844 store_id: 1 } peers { id: 7444932 store_id: 3 role: Learner }"] [peer_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.560 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:20.621 +08:00] [INFO] [region.rs:488] ["apply new data"] [time_takes=59.77616ms] [region_id=7297670]
[2025/09/06 04:16:20.621 +08:00] [INFO] [region.rs:441] ["begin apply snap data"] [peer_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.622 +08:00] [INFO] [snap.rs:670] ["set_snapshot_meta total cf files count: 3"]
[2025/09/06 04:16:20.623 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { peer { id: 7444927 store_id: 3 } } changes { change_type: AddLearnerNode peer { id: 7438221 store_id: 14 role: Learner } } }"] [index=2489526] [term=92] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.624 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65070 version: 85"] [kind=EnterJoint] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.624 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7297670 start_key: 6F73735F313536333833373939362E706466 region_epoch { conf_ver: 65072 version: 85 } peers { id: 7438221 store_id: 14 role: DemotingVoter } peers { id: 7440507 store_id: 8 } peers { id: 7441402 store_id: 2 } peers { id: 7444927 store_id: 3 role: IncomingVoter }"] ["original region"="id: 7297670 start_key: 6F73735F6F62673939362E706466 region_epoch { conf_ver: 65070 version: 85 } peers { id: 7438221 store_id: 14 } peers { id: 7440507 store_id: 8 } peers { id: 7441402 store_id: 2 } peers { id: 7444927 store_id: 3 role: Learner }"] [changes="[peer { id: 7444927 store_id: 3 }, change_type: AddLearnerNode peer { id: 7438221 store_id: 14 role: Learner }]"] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.624 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7441402, 7444927, 7440507} }, outgoing: Configuration { voters: {7438221, 7441402, 7440507} } }, learners: {}, learners_next: {7438221}, auto_leave: false }"] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.629 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 {}"] [index=2489527] [term=92] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.629 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65072 version: 85"] [kind=LeaveJoint] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.629 +08:00] [INFO] [apply.rs:2415] ["leave joint state successfully"] [region="id: 7297670 start_key: 6F73735362E706466 region_epoch { conf_ver: 65074 version: 85 } peers { id: 7438221 store_id: 14 role: Learner } peers { id: 7440507 store_id: 8 } peers { id: 7441402 store_id: 2 } peers { id: 7444927 store_id: 3 }"] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.630 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7441402, 7444927, 7440507} }, outgoing: Configuration { voters: {} } }, learners: {7438221}, learners_next: {}, auto_leave: false }"] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.634 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { change_type: RemoveNode peer { id: 7438221 store_id: 14 role: Learner } } }"] [index=2489528] [term=92] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.634 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 65074 version: 85"] [kind=Simple] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.634 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7297670 start_key: 6F737706466 region_epoch { conf_ver: 65075 version: 85 } peers { id: 7440507 store_id: 8 } peers { id: 7441402 store_id: 2 } peers { id: 7444927 store_id: 3 }"] ["original region"="id: 7297670 start_key: 6F706466 region_epoch { conf_ver: 65074 version: 85 } peers { id: 7438221 store_id: 14 role: Learner } peers { id: 7440507 store_id: 8 } peers { id: 7441402 store_id: 2 } peers { id: 7444927 store_id: 3 }"] [changes="[change_type: RemoveNode peer { id: 7438221 store_id: 14 role: Learner }]"] [peer_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.635 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7441402, 7444927, 7440507} }, outgoing: Configuration { voters: {} } }, learners: {}, learners_next: {}, auto_leave: false }"] [raft_id=7444927] [region_id=7297670]
[2025/09/06 04:16:20.666 +08:00] [INFO] [region.rs:488] ["apply new data"] [time_takes=42.065188ms] [region_id=7217664]
[2025/09/06 04:16:20.668 +08:00] [INFO] [apply.rs:1612] ["execute admin command"] [command="cmd_type: ChangePeerV2 change_peer_v2 { changes { peer { id: 7444932 store_id: 3 } } changes { change_type: AddLearnerNode peer { id: 7440593 store_id: 14 role: Learner } } }"] [index=9929521] [term=329] [peer_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.668 +08:00] [INFO] [apply.rs:2204] ["exec ConfChangeV2"] [epoch="conf_ver: 82062 version: 85"] [kind=EnterJoint] [peer_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.668 +08:00] [INFO] [apply.rs:2385] ["conf change successfully"] ["current region"="id: 7217664 start_key: 6F7373E706466 region_epoch { conf_ver: 82064 version: 85 } peers { id: 7440593 store_id: 14 role: DemotingVoter } peers { id: 7442424 store_id: 9 } peers { id: 7443844 store_id: 1 } peers { id: 7444932 store_id: 3 role: IncomingVoter }"] ["original region"="id: 7217664 start_key: 6F73735F635302E706466 region_epoch { conf_ver: 82062 version: 85 } peers { id: 7440593 store_id: 14 } peers { id: 7442424 store_id: 9 } peers { id: 7443844 store_id: 1 } peers { id: 7444932 store_id: 3 role: Learner }"] [changes="[peer { id: 7444932 store_id: 3 }, change_type: AddLearnerNode peer { id: 7440593 store_id: 14 role: Learner }]"] [peer_id=7444932] [region_id=7217664]
[2025/09/06 04:16:20.669 +08:00] [INFO] [raft.rs:2646] ["switched to configuration"] [config="Configuration { voters: Configuration { incoming: Configuration { voters: {7442424, 7443844, 7444932} }, outgoing: Configuration { voters: {7442424, 7440593, 7443844} } }, learners: {}, learners_next: {7440593}, auto_leave: false }"] [raft_id=7444932] [region_id=7217664]