【TiDB 使用环境】生产环境
【TiDB 版本】v6.5.0
【操作系统】centos8
【集群节点数】3db 6kv
[更新于 2025-09-17]
当天晚上集群又出现了同样的问题,综合排查发现只要一个 kv 节点的磁盘使用率达到了 95%,pd 在 kv 本身正常的情况下就会突然出现巨量的 balance leader,而 leader balance 又不受 store limit 限制,从监控来看是这个行为卡死了 raftstore,体现为 raft log 同步不了,raftstore 繁忙时 coprocessor 读因为有大量 leader transfer 又需要做 read index 更加剧了 raftstore 的负载,导致获取 snapshot 时间边长,又导致 coprocessor duration 变长,同时又因为 db 启动和用户创建连接时需查询系统表,查不动导致 db 连接不上,又因为这个负载不是查询和写入导致的而是 region 调度导致的,所以即使重启 db 节点也无法解决问题。发现是这个原因之后给 kv 加了磁盘把使用率降到 90%,问题后面没有再复现。可能是 95% 是个硬限制?不好说,各位请引以为戒及时扩容
[原帖]
今天凌晨发现使用集群的任务在创建数据库连接位置频繁报错,信息为登录阶段 network timeout,在多个环境测试手动登录发现也连不上,当时检查 dashboard 和 grafana 上 db pd kv 监控未发现负载有明显异常,同时 db 存在还活着的连接一百多个。
最开始怀疑是 db 的问题,于是 tiup restart -R tidb 重启了所有 db 节点, 但 tiup 随后报 tidb 启动超时,tiup display 显示所有 db 节点为 down,但 db 进程本省正常启动且没有快速重启,日志打印至 [INFO] [printer.go:48] ["loaded config"] 后没有下文,为了排除是 pd 的问题,在 db 起不来的情况下重启了 pd 所有节点,发现 db 日志中正常打印了 pd 断开 [2025/09/09 07:25:51.525 +08:00] [ERROR] [base_client.go:144] ["[pd] failed updateMember"] [error="[PD:client:ErrClientGetLeader]get leader from [http://10.120.33.151:2379 http://10.120.33.42:2379 http://10. 120.33.68:2379] error"],并且在 pd 重启后 db 仍然无法启动,暂时没再看 pd 的问题。
因为 db 起不来,就把 db 的日志等级提到了 info 并再次重启 db 节点,发现 db 在启动时输出了以下日志:
[2025/09/09 07:35:20.226 +08:00] [INFO] [coprocessor.go:1080] ["[TIME_COP_WAIT] resp_time:1m0.069574963s txnStartTS:460685170478415880 region_id:360338375 store_addr:10.120.33.148:20160 kv_process_ms:7 kv_wait_ms:0 kv_read_ms:3 processed_versions:224 total_versions:301 rocksdb_delete_skipped_count:19 rocksdb_key_skipped_count:878 rocksdb_cache_hit_count:120 rocksdb_read_count:0 rocksdb_read_byte:0"]
[2025/09/09 07:35:20.354 +08:00] [INFO] [coprocessor.go:1080] ["[TIME_COP_WAIT] resp_time:1m0.079600874s txnStartTS:460685170478415880 region_id:313686217 store_addr:10.120.33.148:20160 kv_process_ms:0 kv_wait_ms:0 kv_read_ms:0 processed_versions:0 total_versions:1 rocksdb_delete_skipped_count:0 rocksdb_key_skipped_count:0 rocksdb_cache_hit_count:15 rocksdb_read_count:0 rocksdb_read_byte:0"]
[2025/09/09 07:36:20.439 +08:00] [INFO] [coprocessor.go:1080] ["[TIME_COP_WAIT] resp_time:1m0.082817939s txnStartTS:460685170478415880 region_id:313686217 store_addr:10.120.33.148:20160 kv_process_ms:0 kv_wait_ms:0 kv_read_ms:1 processed_versions:224 total_versions:225 rocksdb_delete_skipped_count:0 rocksdb_key_skipped_count:448 rocksdb_cache_hit_count:15 rocksdb_read_count:0 rocksdb_read_byte:0"]
这几个 region 根据 id 查询发现都是 mysql db 下的表,具体有下面这些:
user
global_priv
db
tables_priv
columns_priv
GLOBAL_VARIABLES
tidb
help_topic
stats_meta
stats_buckets
gc_delete_range
gc_delete_range_done
stats_feedback
role_edges
default_roles
bind_info
stats_top_n
stats_histograms
由于 db 启动过程中在系统表上的 cop 报 TIME_COP_WAIT,目前我怀疑是因为创建连接时用户相关的认证流程被这个卡住,导致创建连接超时,但时段内 kv 节点又没有什么报警,就只能又重启了所有 kv 节点,kv 节点重启后一分钟左右 db 节点也启动成功,各方面验证可以正常建立连接。
目前排查就直到这个程度,主要疑点就在 kv 在系统表的 cop 时长上,再看一下 db 无法启动时输出的日志:
[2025/09/09 07:36:20.439 +08:00] [INFO] [coprocessor.go:1080] ["[TIME_COP_WAIT] resp_time:1m0.082817939s txnStartTS:460685170478415880 region_id:313686217 store_addr:10.120.33.148:20160 kv_process_ms:0 kv_wait_ms:0 kv_read_ms:1 processed_versions:224 total_versions:225 rocksdb_delete_skipped_count:0 rocksdb_key_skipped_count:448 rocksdb_cache_hit_count:15 rocksdb_read_count:0 rocksdb_read_byte:0"]
可以看到虽然 db 上层报 resp_time 有一分钟,但 kv 各项耗时指标都基本为零,反观一个正常的 cop 等待应该与下面这个类似:
[2025/09/09 08:14:23.656 +08:00] [INFO] [coprocessor.go:1080] ["[TIME_COP_WAIT] resp_time:304.795945ms txnStartTS:460685800475983930 region_id:323450017 store_addr:10.120.33.149:20160 kv_process_ms:0 kv_wait_ms:303 kv_read_ms:1 processed_versions:1 total_versions:1 rocksdb_delete_skipped_count:0 rocksdb_key_skipped_count:0 rocksdb_cache_hit_count:11 rocksdb_read_count:0 rocksdb_read_byte:0"] [conn=3849783834006525241]
请问什么因素可能会导致这种情况?
图:问题时段(0350-0740) kv 出现大量未休眠 region
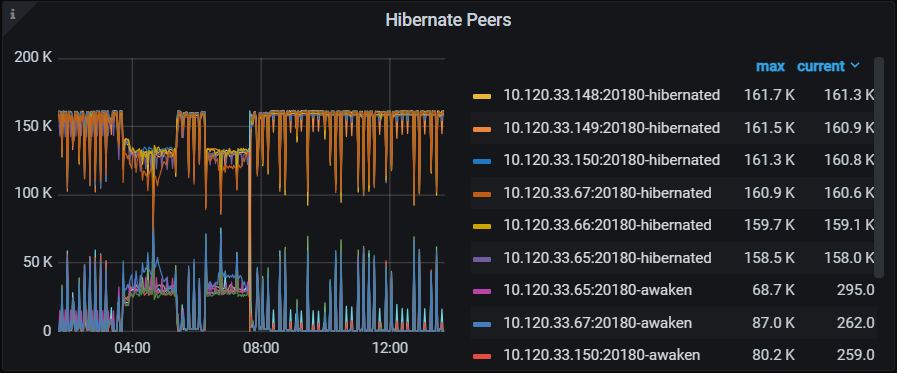
图:问题时段 kv raft store
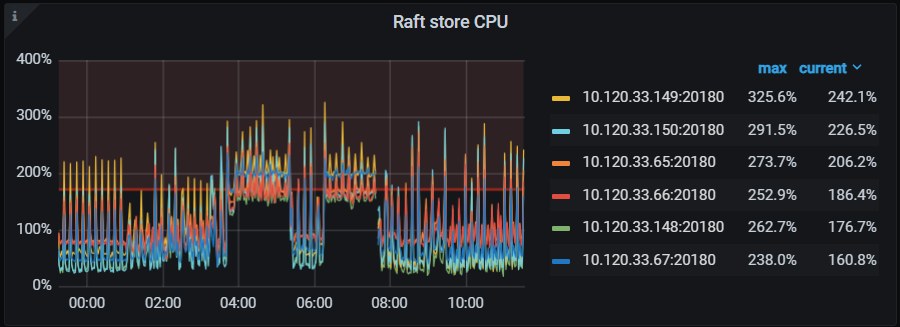
图:raft propose,比较奇怪的是六台 kv 中有一台没有 read 负载,我们所有表都是三副本
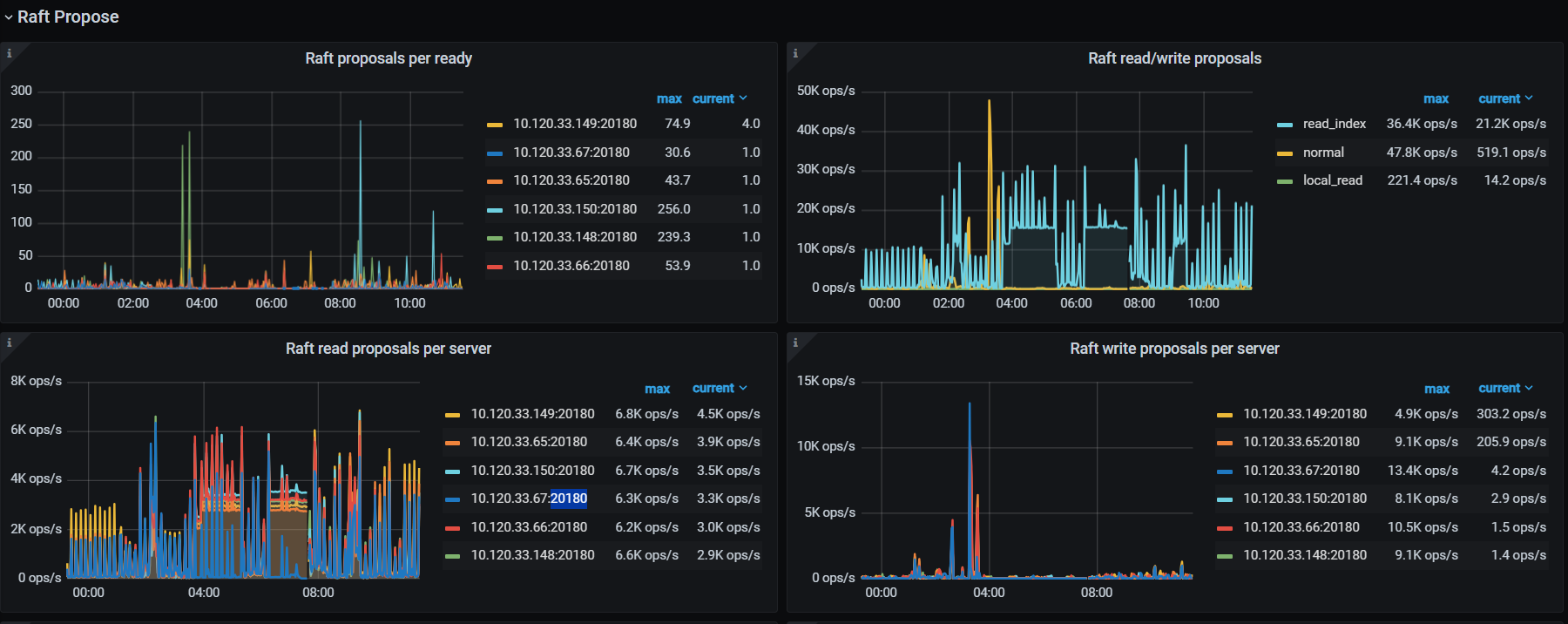
图:db cop duration
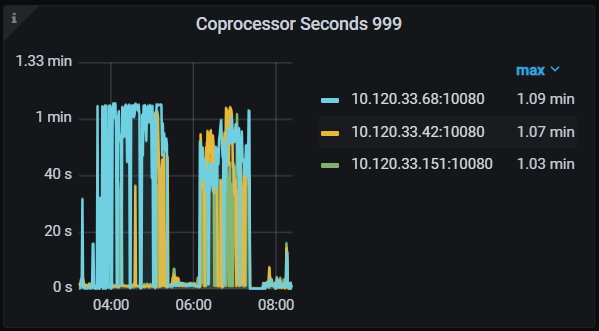
图:kv unified read pool running task,这个也比较有疑点,正好是 raft propose 无负载的那个 kv 有很多 task
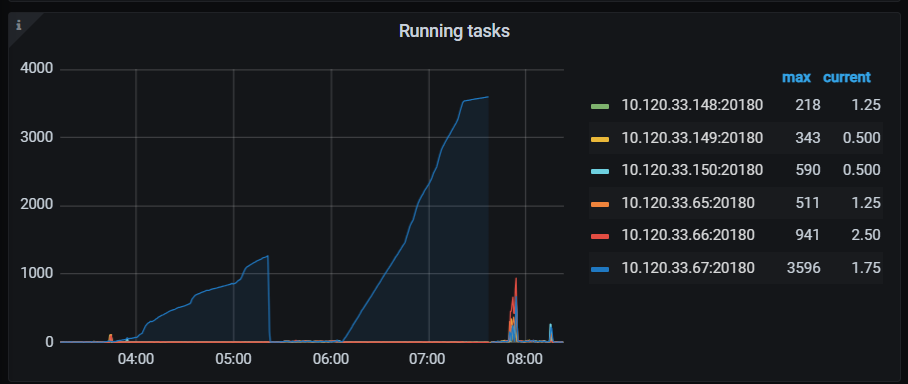
图:kv raft log lag
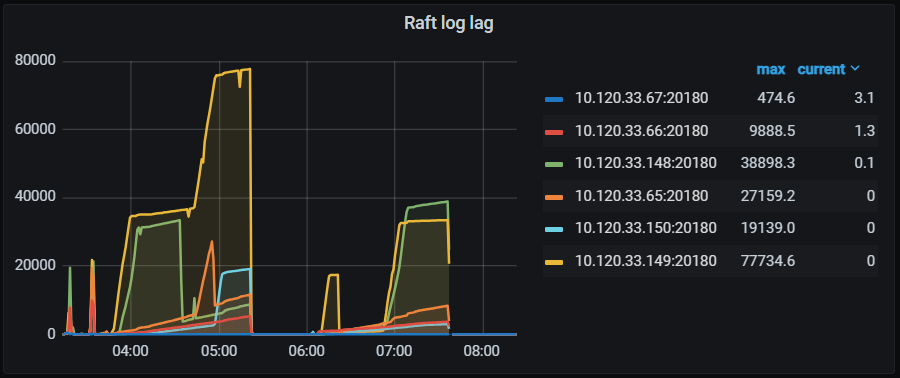
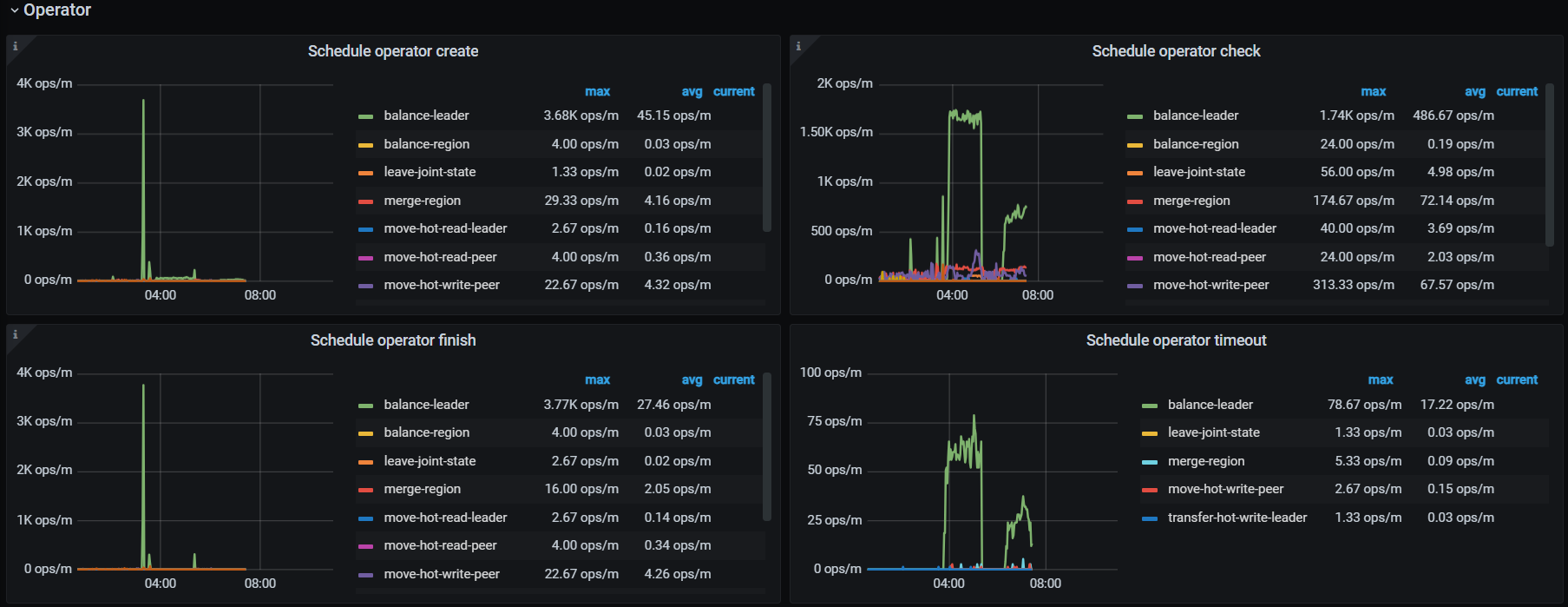
图:pd operator,发现同时间有大量 balance leader 产生且超时