【TiDB 使用环境】生产
【TiDB 版本】5.7.25-TiDB-v6.5.1
【操作系统】CentOS 7
【部署方式】机器部署(16C/64G)
【集群数据量】500W+
【集群节点数】3
【问题复现路径】执行Delete操作
【遇到的问题:问题现象及影响】go服务中有一个定时任务,会在每天凌晨执行删除过期数据的操作,SQL如下:DELETE FROM push_alert_history WHERE record_time < DATE_SUB(now(),INTERVAL 7 DAY) LIMIT 500。但是在客户生产环境运行时报错OOM,客户表中数据约有500W条,但是单条数据不大。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】

1 个赞
你这个sql如果删除的很慢,我是能理解的,但是直接oom。就有点奇怪了。
最好是能看看执行计划。
建议尝试一下非事务删除,看是否能运行下去。
https://docs.pingcap.com/zh/tidb/stable/dev-guide-delete-data/#非事务批量删除
另外你6.5.1可能会有些bug导致出现超大的region,也可能导致删除的时候扫描不动。

建议查一下grafana里面这个oversized region count是不是0.
2 个赞
还是得看看更详细的错误信息才能判断
1 个赞
可以抓两个sql看看执行计划,跟内存使用情况
1 个赞
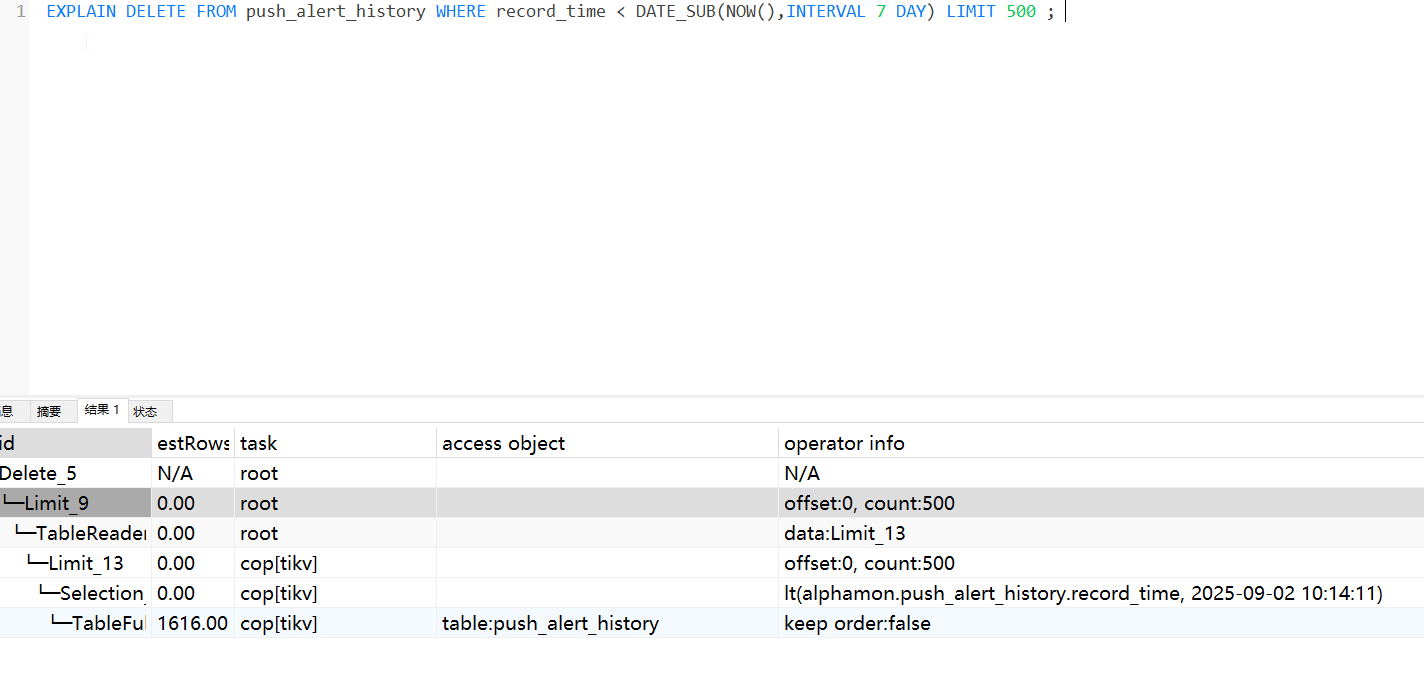
可以看下生产环境的执行计划,dashboard上可查
1 个赞
看执行计划是tablefullscan,没有走索引么?
1 个赞

1 个赞
where条件是不是没索引
看下建表语句找找线索,有tiflash吗,
确实没有,只有id是主键
没有,
是的 .
record_time加个索引。。就避免了全表扫描。。节约内存。。
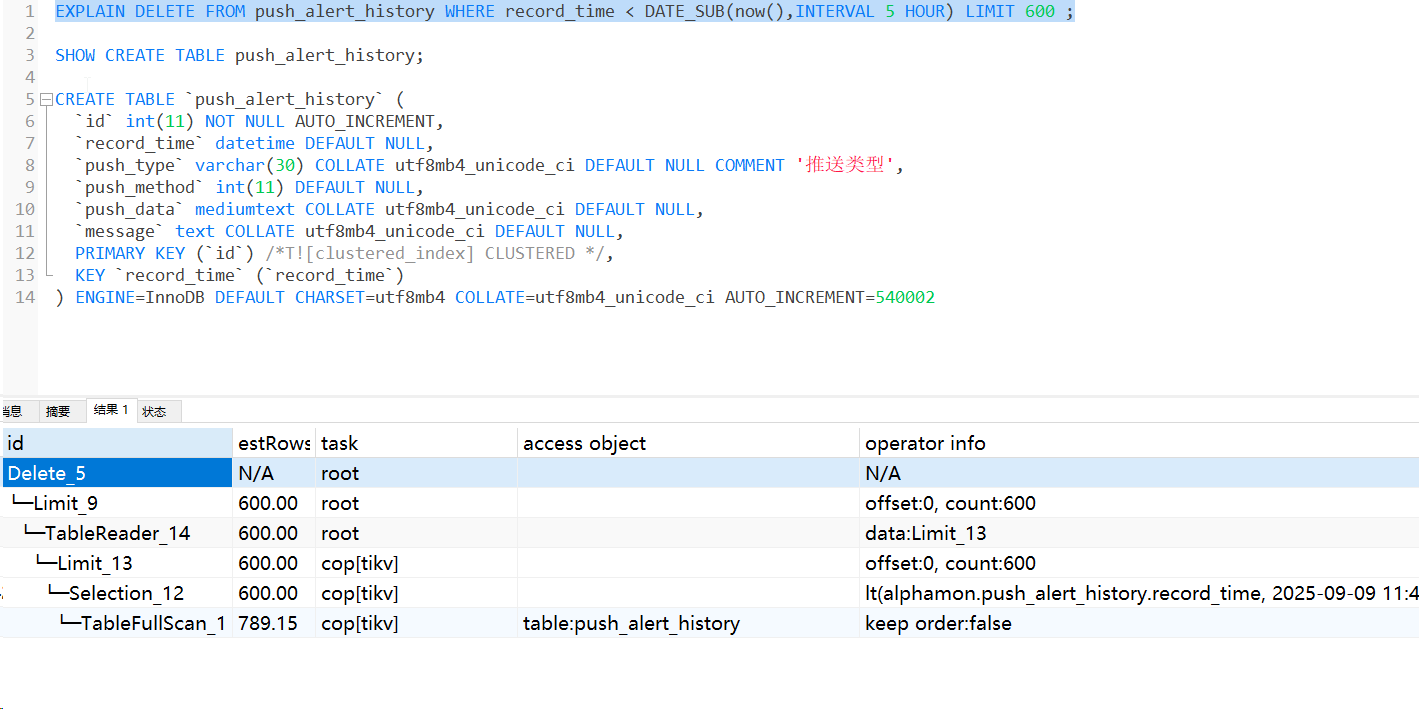
500w 也不是很大的表,这么简单的一条SQL居然也出现OOM了,是不是tidb 节点的内存太小了啊,限制使用的最大内存的参设是不是没有设置啊
这个里面,你直接点进去应该能看到这个1.3g的内存是那个算子用的最多。执行计划的列很多,往后拖应该能看到。
感觉这个执行计划有点问题。limit算子不太应该用这么内存,如果加order by我是能理解的。现在这个1.3g就很难理解用在哪里了。
加个hint走索引看看
根本原因就是,你在定时执行删除数据的时候,没走索引或者事物堆积导致内存暴涨引发oom,此时应该为你的record_time添加索引并考虑分批提交或修改删除逻辑。
感谢老师分享