tidb小白
(Ti D Ber Emsp S Ckm)
1
【TiDB 使用环境】生产环境
【TiDB 版本】8.5.1
【操作系统】centos
【遇到的问题:问题现象及影响】sql超过资源限制,被这个给停止了,提示RU不够用。针对这些参数,我有很多疑问。
1、为什么同一个账号,有的sql,执行时间几个小时,RC等待时间都达到了几个小时,SQL也能正常执行完(见图二),却没因这个参数被提前结束掉呢?
2、为啥有的sql,使用的RU过多,会报错:Exceeded resource group quota limitation;而图一被结束掉的那个sql,又没提示这个呢?
3、如果按图一日志显示,该如何去查根因sql是哪一条呢?可能当时慢查询有很多条,怎么知道具体是哪一条sql导致的呢?好像图一这种情况,也不会记录到慢查询的dashboard里。
4、根据监控,查询图三的RU,能看到,当时RU总消耗,高峰期也才5千多。这个RU我设置最大是2万;那么就又引申一个问题,RU是每秒回填速率,但是dashboard上只能看到一段时间的总RU;即使有了这个dashboard,我也无法判断,这个RU给的够不够。只能当业务受损,发现sql执行报错,我才能知道,RU不够了?
【其他附件:截图/日志/监控】
图一:
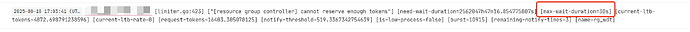
图二:
图三:
xfworld
(魔幻之翼)
2
慢查询 有专门的记录,开启了就可以查到的,而且是按照时间记录的。
RU 的问题只能慢慢测试了,先解决慢查询的问题吧,这样可以缓解 RU 受波动的情况
应该就是不很准确
图表都是rate平均的,实际最高ru应该比图表要高不少
tidb小白
(Ti D Ber Emsp S Ckm)
5
是的,所以这个图表,对于我判断RU够不够用,作用不大,只能等业务发现sql执行不了是由于RU不够导致的,我这边才知道是RU不够了  。所以这个RU使用起来,不是很方便
。所以这个RU使用起来,不是很方便
tidb小白
(Ti D Ber Emsp S Ckm)
6
谢谢大佬,这几篇文章我也看过了。但是有些慢sql,可能并不是他本身慢,可能是由于RU不够用了,所以在执行sql的时候,它需要等待RU的回填,才导致它也慢了;这样定位根因SQL就变得更困难了
优化吧,按照执行时间,内存等倒序优化
既然都已经等待ru回填,怎么会最高值才5000,没达到2万
lllzd
(时光旅行者)
8
回答你的问题。
1、 ”等待时间长”不等于 “消耗RU超限终止“。
2、 取决于你使用的资源管控模式和错误类型。
3、 这类被“运行时中止的SQL,不会进入慢查询日志,需查 statement_summary 或者events_statements_history。
4、 你看到的是“平均RU”,而问题出在“瞬时峰值”或“单个查询配额。
