【TiDB 使用环境】测试
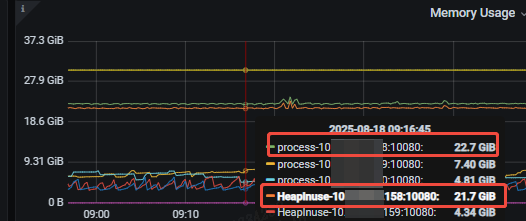

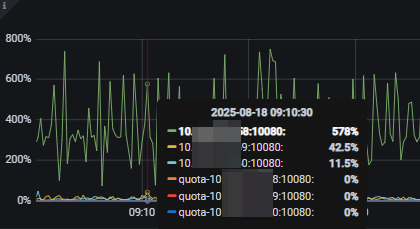
日志没有报错,连接数为1,这个连接内存占用为0,该tidb实例有时候的连接数为0,应该是tiproxy分发策略协调到其他节点了。如何排查这种莫名其妙的高消耗?各位大佬
先问一句,是混合部署么?多个组件部署在一台服务器上。
这台服务器部署了tidb和pd节点。我看服务器的内存消耗都是tidb-server占用的
dashboard里有个top sql的功能可以看是哪些语句用的CPU最高。
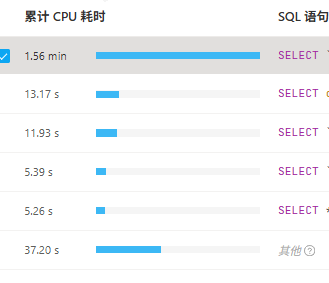
这个是占用最高的,3小时内共CPU累计耗时1.56min。总体来说没有特别高的
SELECT
`t`.`id`,
`t`.`task_key`,
`t`.`type`,
`t`.`state`,
`t`.`step`,
`t`.`priority`,
`t`.`concurrency`,
`t`.`create_time`,
`t`.`target_scope`,
max (`st`.`concurrency`)
FROM
`mysql`.`tidb_global_task` `t`
JOIN `mysql`.`tidb_background_subtask` `st` ON `t`.`id` = `st`.`task_key`
AND `t`.`step` = `st`.`step`
WHERE
`t`.`state` IN (...)
AND `st`.`state` IN (...)
AND `st`.`exec_id` = ?
GROUP BY
`t`.`id`
ORDER BY
priority ASC,
`create_time` ASC,
`id` ASC
这个是分布式执行框架里的,是不是有ddl语句在执行?
https://docs.pingcap.com/zh/tidb/stable/tidb-distributed-execution-framework/#tidb-分布式执行框架-dxf
我看指标图已经持续了三四天了,应该不是ddl语句,ADMIN SHOW DDL JOBS; 命令也没查到有卡住的DDL
看下analyze的时间点,show analyze status,是不是有analyze执行失败的情况,另外调整下analyze的时间观察下cpu有没有明显下降,先排查下是否为analyze的问题
analyze 的时间都在很短时间内完成,耗时最长的3s,大部分都砸1s内完成。没有异常状态的。
通过 dashboard 分析一下内存高的节点的火焰图。参考如下文档
https://docs.pingcap.com/zh/tidb/stable/dashboard-profiling/
像是统计信息和session相关的占用比例较高
可以发一下文件吗?
发不出去 ![]()
重启 tidb server 应该能解决
尽快升级到 853 版本吧。
重启可以应该是可以解决问题
是版本有bug吗?
去 tidb 日志里面,搜索下 memory quota 类似关键字,是不是在频繁触发 tidb 的内存管理。
推测就是 tidb 内存用的多,触发内存管理杀 sql,实际上没有啥 sql 能杀。一直在这个逻辑里面导致 cpu 高。重启释放掉内存即可。
本质问题应该是内存使用不合理或者内存溢出了。