【TiDB 使用环境】生产环境dynamic 10S static 0.01S
【复制黏贴 ERROR 报错的日志】
表中1千万数据,三百个分片ddl(省略了部分字段)
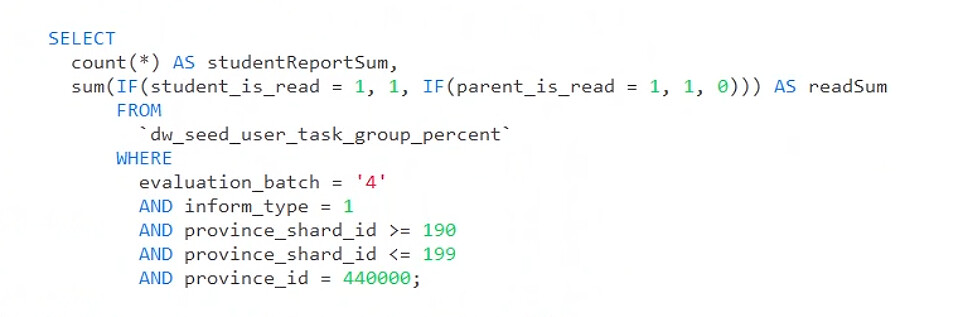
查询sql语句
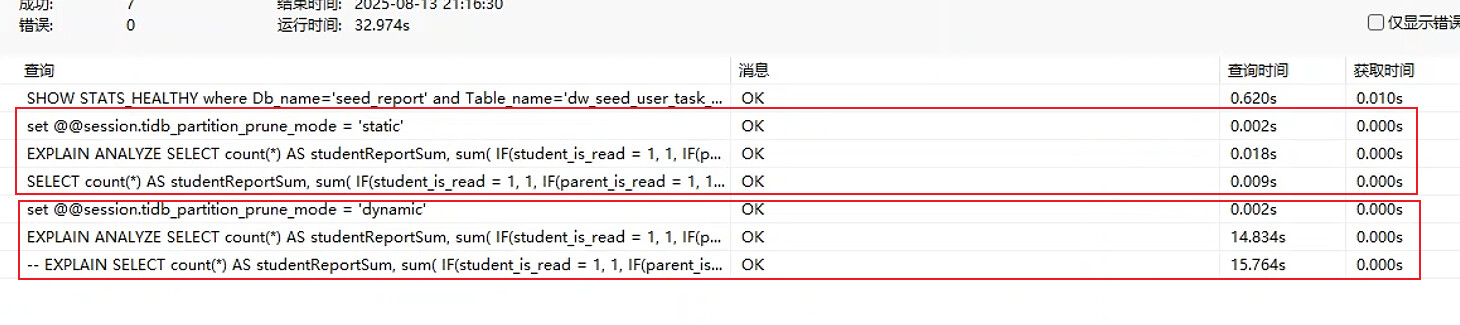
sql执行情况
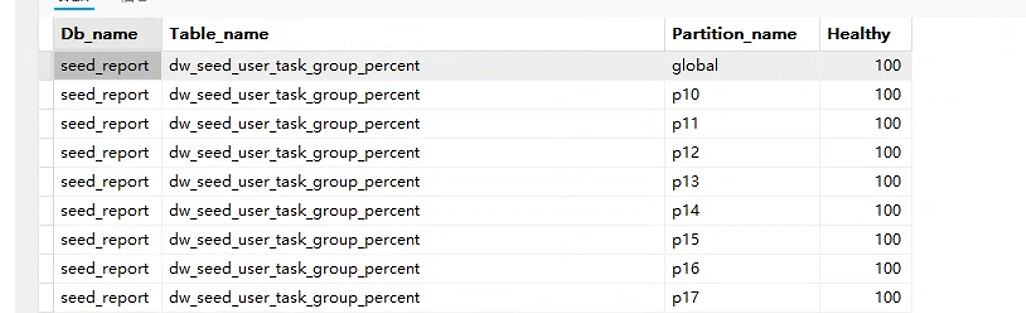
表的健康100
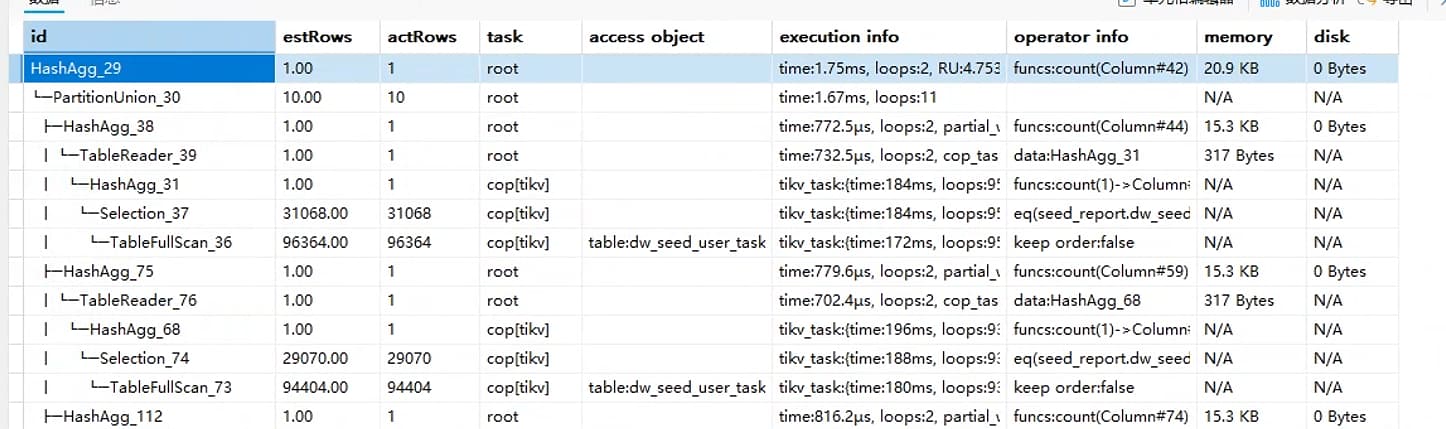
static模式执行计划
dynamic模式执行计划
show stats_meta where table_name like “seed_report”;
lllzd
2025 年8 月 14 日 02:03
5
大概率是统计信息不准确,建议可以考虑下面操作。
1、查看当前统计信息是否健康
2、更新统计信息
查询前执行过更新统计信息,确认执行前后表的健康度都是100,
结果如下状态信息结果.xlsx (13.2 KB)
lllzd
2025 年8 月 14 日 06:15
11
看了你提供的结果,确实统计信息不一致,建议重建统计信息。
1、删除现有统计信息
2、重新分析整表
重建会消耗资源,建议业务低峰期在执行!!!
看统计信息和执行计划,静态分区裁剪和动态分区裁剪其实最大的区别是静态分区裁剪没有用到idx_pid_cid_did_sid索引,而动态分区裁剪用到了,实际来看,使用idx_pid_cid_did_sid索引,预计从899933.81行数据中可通过索引过滤出75760.52,但是实际索引执行,是从954280中过滤出了954280行数据,从你的统计信息中看,p190到199,实际才95W的数据,索引过滤出95W数据,那不是全部过滤出来了,然后还要回表?还不是不如全表扫了还。/ … + USE INDEX() */
执行计划看统计信息是正确的,没有用到索引,索引创建正确吗?强制索引后,执行计划怎样的
哈哈,这个耗时长就是因为使用了索引导致的,楼上有解释
麻辣机师
2025 年8 月 15 日 01:21
16
索引的统计信息应该不准吧?从分区的统计信息看,数量和执行计划显示的差不多,动态裁剪的那个显示,扫描后的数据量预估只有7万,但索引扫描的动作,条件中只有分区的条件,无其他条件,按理说这个预估数据量应该=分区数据量总和
麻辣机师
2025 年8 月 15 日 01:26
17
数据库设计感觉也可以考虑这种情况的优化:索引扫描只有分区条件,而且也需要回表,这种情况应该考虑改分区扫描
system
2025 年8 月 22 日 01:26
18
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。