CAI001
2025 年8 月 6 日 01:49
1
【TiDB 使用环境】开发环境
1、3台服务器混和部署的tidb集群,初始tidb只有两个节点,tiproxy能分别代理到这两个节点,连接数也是均衡的。新加了一个tidb节点进去,已经过了2天了,一个连接数都没打到新节点。集群状态是正常的。
问题1,已解决,缩容后又重新扩了一下可以了。
正常不需要操作的,TiProxy在tidb-server节点扩容后能够自动发现新节点的,也不需要将tidb-server的配置配到tiproxy里面
https://docs.pingcap.com/zh/tidb/stable/tiproxy-overview/
当 TiDB server 进行扩容、缩容操作时,如果使用普通负载均衡器,你需要手动更新 TiDB server 列表,而 TiProxy 能自动发现 TiDB server 列表,无需人工介入
好像是不需要,自动发现。没有这个环境,不好测试
CAI001
2025 年8 月 6 日 02:38
8
tiproxy的配置文件里面已经有新加的tidb节点了,但就是连接打不过去
grafana的tiproxy监控里,包括新增的tidb节点信息嘛?
CAI001
2025 年8 月 6 日 05:54
10
具体哪个指标呢?ping指标是有的,连接数相关指标就没有
那估计就是tipr本身有问题,帮助里明确是不需要做任何干预的
客户端连接数据库是不是连接池,已连接的连接不断开重连是不会打到新的tidb节点上的。
CAI001
2025 年8 月 6 日 09:22
13
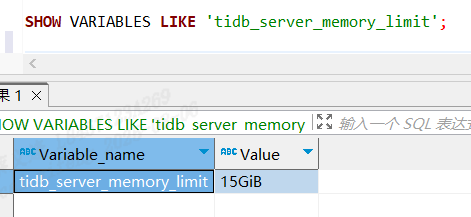
tidb_server_memory_limit 设置为百分比之后就能自动触发GC了
在 TiDB 中,垃圾回收(GC,Garbage Collection )主要用于清理事务提交后不再需要的旧版本数据,保障存储高效利用。若一直未触发 GC ,可能由以下原因导致,可按流程排查:
tidb_gc_enableON(默认开启),若被误设为 OFF ,GC 不会执行。可通过 SHOW VARIABLES LIKE 'tidb_gc_enable'; 检查,若值为 OFF ,执行 SET GLOBAL tidb_gc_enable = ON; 开启(需注意业务影响,可能需在低峰期操作 )。tidb_gc_run_interval10m0s(10 分钟)。若被修改为极大值(如几小时、几天),会导致 GC 很久才触发一次。通过 SHOW VARIABLES LIKE 'tidb_gc_run_interval'; 查看,若不符合预期,用 SET GLOBAL tidb_gc_run_interval = '10m'; 重置为默认合理值 。tidb_gc_life_time10m0s ,表示超过 10 分钟的旧版本数据会被清理。若该值被设得极大(如几天、几周 ),GC 虽会执行,但实际清理动作因数据未到保留时长阈值而 “看似没效果”。用 SHOW VARIABLES LIKE 'tidb_gc_life_time'; 检查,必要时调整(如 SET GLOBAL tidb_gc_life_time = '10m'; ,需评估业务对历史数据访问需求 )。
GC 流程依赖 PD 进行调度和协调(PD 负责维护集群元信息、推进 GC 时机 ),若 PD 集群存在问题,可能阻碍 GC 触发:
PD leader 异常 :PD 以 Raft 协议选主,若 leader 节点故障、网络分区导致 leader 无法正常工作,GC 调度会受牵连。可通过 pd-ctl 工具(如 pd-ctl -u http://<pd-ip>:<pd-port> member )查看 PD 集群成员状态、leader 节点信息,确认是否有 leader 切换频繁、 leader 节点不可达等情况。若 PD 集群不稳定,需排查服务器网络(如网络延迟、丢包 )、PD 进程资源(CPU、内存是否过载 )等问题 。PD 中 GC 相关调度逻辑阻塞 :PD 内部若有其他元数据操作长时间阻塞(如大规模 Region 调度、锁竞争 ),可能影响 GC 任务下发。可结合 PD 日志(默认日志路径可通过 PD 配置文件查看,通常会记录调度、GC 相关关键事件 ),搜索 gc 关键词,排查是否有调度超时、资源等待等报错信息 。
TiKV 节点需和 PD 正常交互,上报数据版本情况、接收 GC 指令 。若通信异常,会导致 GC 无法开展:
网络连通性问题 :检查 TiKV 节点与 PD 节点之间网络是否通畅,可在 TiKV 节点上用 ping、telnet(或 nc ,如 nc -zv <pd-ip> <pd-port> )测试 PD 服务端口(默认 PD 客户端端口 2379 )。若网络不通,排查防火墙规则(是否限制了 TiKV 与 PD 通信 )、网络设备(交换机、路由器是否有 ACL 策略拦截 )等 。TiKV 节点状态异常 :若 TiKV 节点自身进程僵死、资源耗尽(如内存 swap 严重、磁盘 IO 满负载 ),可能无法正常向 PD 上报状态、响应 GC 指令。通过 tiup cluster display <集群名称> 查看 TiKV 节点状态是否为 Up ,结合 TiKV 节点的系统监控(CPU 使用率、内存使用率、磁盘 IO 等 ),判断是否因资源问题导致通信异常 。
无数据更新或极少更新 :若集群中业务操作以只读查询为主,几乎没有事务提交产生新数据版本,旧版本数据也未达到 tidb_gc_life_time 阈值,GC 虽会按间隔执行,但无实际数据可清理,从监控看可能呈现 “未有效触发” 的表象。可模拟一些事务操作(如插入、更新数据后再删除 ),制造数据版本变化,观察后续 GC 是否会清理对应旧版本数据 。长事务或未提交事务 :若存在长时间未提交的事务(事务持续时间超过 tidb_gc_life_time ),会 “保护” 对应数据版本不被 GC 清理(需等事务结束,避免影响事务可见性 )。可通过 SELECT * FROM INFORMATION_SCHEMA.CLUSTER_TRANSACTIONS; 查看集群中长事务情况,若有异常长事务,排查业务代码是否存在事务未正确提交、事务范围过大等问题 。
按照上述步骤逐一排查,基本能定位到 GC 未触发的根源,进而针对性解决,让 GC 正常执行以保障 TiDB 存储健康 。
system
2025 年8 月 15 日 02:48
16
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。