老鹰506
(Ti D Ber Uhzt Tfx J)
1
【TiDB 使用环境】生产环境
【TiDB 版本】 7.5.3
【操作系统】CentOS Linux release 7.4.1708 (Core)
【部署方式】云上部署(腾讯云)
【集群数据量】
【集群节点数】
【问题复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
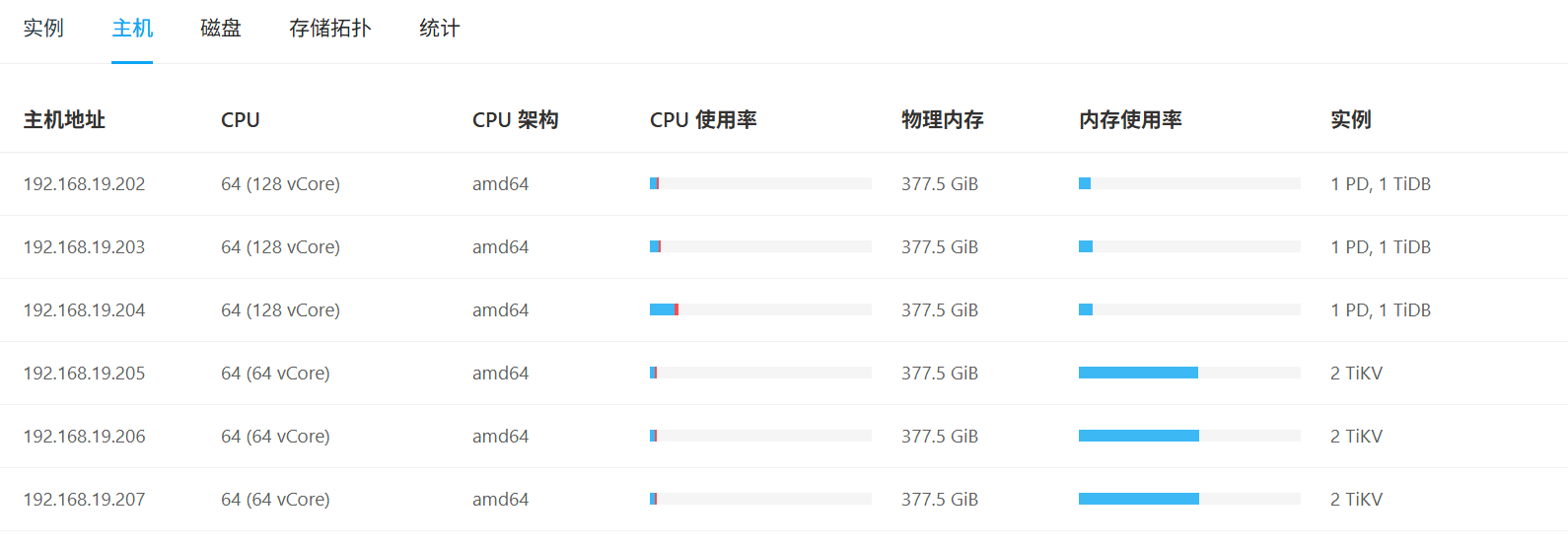
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
目前集群部署在腾讯云,TIKV节点型号 标准型SA5 | SA5.2XLARGE16 8C16G,外加1000GiB 增强型SSD云硬盘
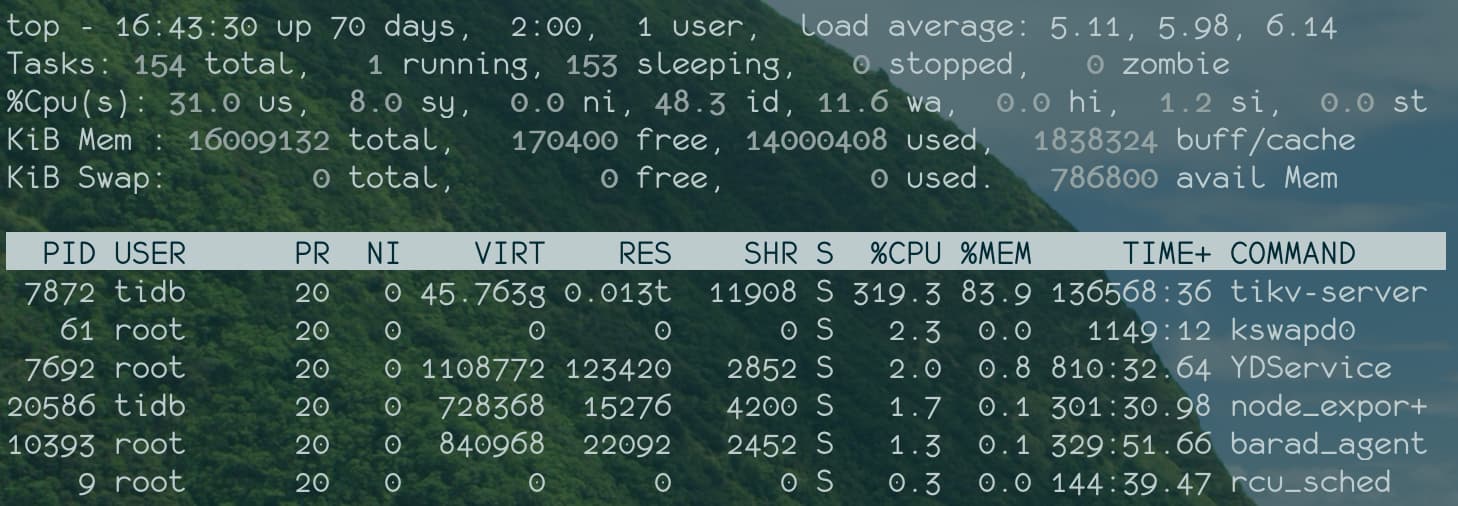
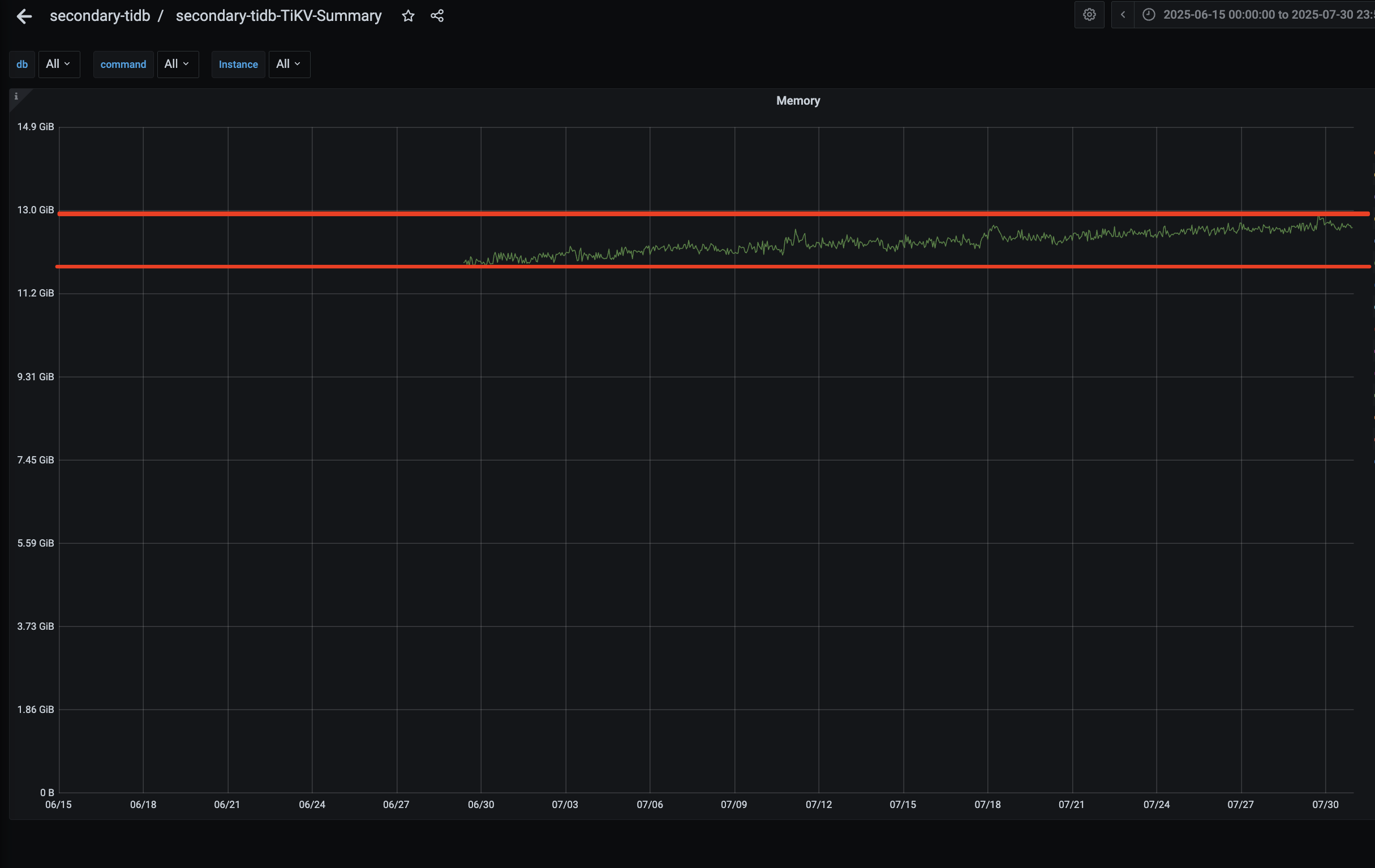
目前收到zabbix主机告警,内存使用超过95%, 登录主机节点top看到的tikv-server常住内存13G,和监控 TiKV-summary 页面的 cluster 中的内存接近13G,是基本吻合的
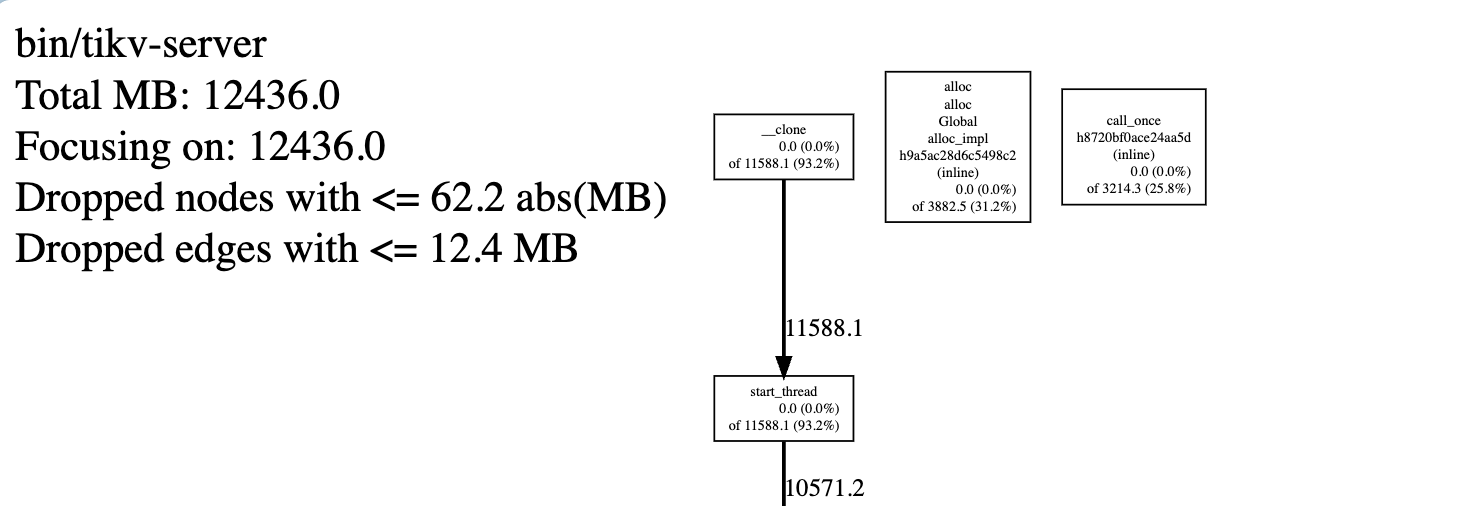
但是 dashboard页面手动分析进行heap的结果显示只有默认的12G;
问题1、为何这两个数据相差挺大
问题2、从监控上看内存是在持续增长的,而且整张超过了 memory-usage-limit配置的12G(默认是16G的75%)
zhanggame1
(Ti D Ber G I13ecx U)
2
tikv内存设置是这个参数 先设置为你希望最大内存一半看看
老鹰506
(Ti D Ber Uhzt Tfx J)
3
这个参数不应该是TIKV实例的内存使用上线么, Tikv底层是用RocksDB,RocksDB多个CF之间共享 block cache ,所以我个人理解 block cache只是tikv 实例整体内存的一部分。
目前storage.block-cache.capacity 默认的基础上我调小了这个,确实整体实例内存使用下降了。
但是实际上 tikv实例的内存还是会超过 memory-usage-limit 设置的值。
所以实际情况 tikv实例内存上限到底是以那个为准呢 
小龙虾爱大龙虾
(Minghao Ren)
4
1、13/16=0.8125,所以你的监控是怎么监控的,不是把 page/cache 也算进去了吧
2、Heap 部分只是通常软件中内存消耗比较大的部分,程序占用内存还有 Stack 等等其他部分
3、持续上涨问题,建议你再观察一段时间
zhanggame1
(Ti D Ber G I13ecx U)
5
storage.block-cache.capacity 设置好了,就有个上限值
比如一个服务器部署2个tikv,设置好了参数,内存占用一年也没变
老鹰506
(Ti D Ber Uhzt Tfx J)
6
1、整体监控是zabbix监控的主机内存(使用超过90%),然后也看了tidb的监控(TIKV-summary中cluster 分类的memory 可以看到tikv实例的内存使用,这里是达到了13G) 13G也是超过 memory-usage-limit默认的12G
3、7.5.3 两个集群从新增都一直在缓慢上涨, 另外一个测试集群是8.1.0的,它有上涨,但是也有释放,所以内存整体维持在一个值波动
老鹰506
(Ti D Ber Uhzt Tfx J)
7
一个服务器部署多个TIKV实例的情况下,文档说的是内存取决是 capacity*5/3 ; 但是我是一个服务器只部署了一个tikv实例
另外了解下 你 377.5GiB的内存, storage.block-cache.capacity 和 memory-usage-limit 配置的值分别是多少?
zhanggame1
(Ti D Ber G I13ecx U)
8
我理解是文档中的memory-usage-limit参数并没有用,实际上就是storage.block-cache.capacity决定的,我们数据量就100G左右,内存设置无所谓