Mwkk
(Ti D Ber A Cla Yr Lb)
1
【TiDB 使用环境】生产环境 /测试/ Poc
【TiDB 版本】
【操作系统】
【部署方式】云上部署(什么云)/机器部署(什么机器配置、什么硬盘)
【集群数据量】
【集群节点数】
【问题复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
ticdc 在做主从集群同步时,延迟一直增加,看日志一直在报 flushLog blocking too long, the redo manager may be stuck ,有什么排查思路吗
WalterWj
(王军 - PingCAP)
2
开了 redo log ?试试关闭看看有没有效果。
看这个日志的意思是刷日志 block 了。
WalterWj
(王军 - PingCAP)
4
TiDBer_wk
(Ti D Ber Os7emy Bg)
5
调大 memory-quota 参数 和 调大 sink-uri 中的 worker-count 参数
写 redo log 慢的话可以调整这里的参数试下。https://docs.pingcap.com/zh/tidb/stable/ticdc-changefeed-config/#consistent
Mwkk
(Ti D Ber A Cla Yr Lb)
6
暂停任务后,发现 changfeed 任务的 ownership 全部为 Processor ,没有 owner ,同步任务停不掉,这样应该如何处理
过一段时间之后也没有选举出 owner 吗?看一下日志有没有报什么错,cdc 是通过 pd 的 etcd 来选举 owner,如果没有 owner 应该有相关日志
Mwkk
(Ti D Ber A Cla Yr Lb)
8
过了20分钟,也没有选举出 owner 。日志搜素什么关键字
Mwkk
(Ti D Ber A Cla Yr Lb)
9
我把 ticdc 组件全部重启了 现在有owener 节点信息了
Mwkk
(Ti D Ber A Cla Yr Lb)
10
归档.zip (6.6 MB)
这是3节点的 cdc 日志信息
WalterWj
(王军 - PingCAP)
12
还有,你存 redo log 的盘是什么盘?ssd 么。
Mwkk
(Ti D Ber A Cla Yr Lb)
14
需要把之前同步至下游的的 changefeed 删除才能重建吧, 不然不是2次写入吗
WalterWj
(王军 - PingCAP)
15
那是的,那你吧 changefeed 删了再试试。
Mwkk
(Ti D Ber A Cla Yr Lb)
16
删changefeed的时候 3个节点就全部变为 processor ,没有 owner 节点了
WalterWj
(王军 - PingCAP)
17
看你之前卡,应该是刷 redo log 超过 31m 了,感觉你刷 redo 的目标盘很烂。如果没有好的硬件不行 redo 就别开了。
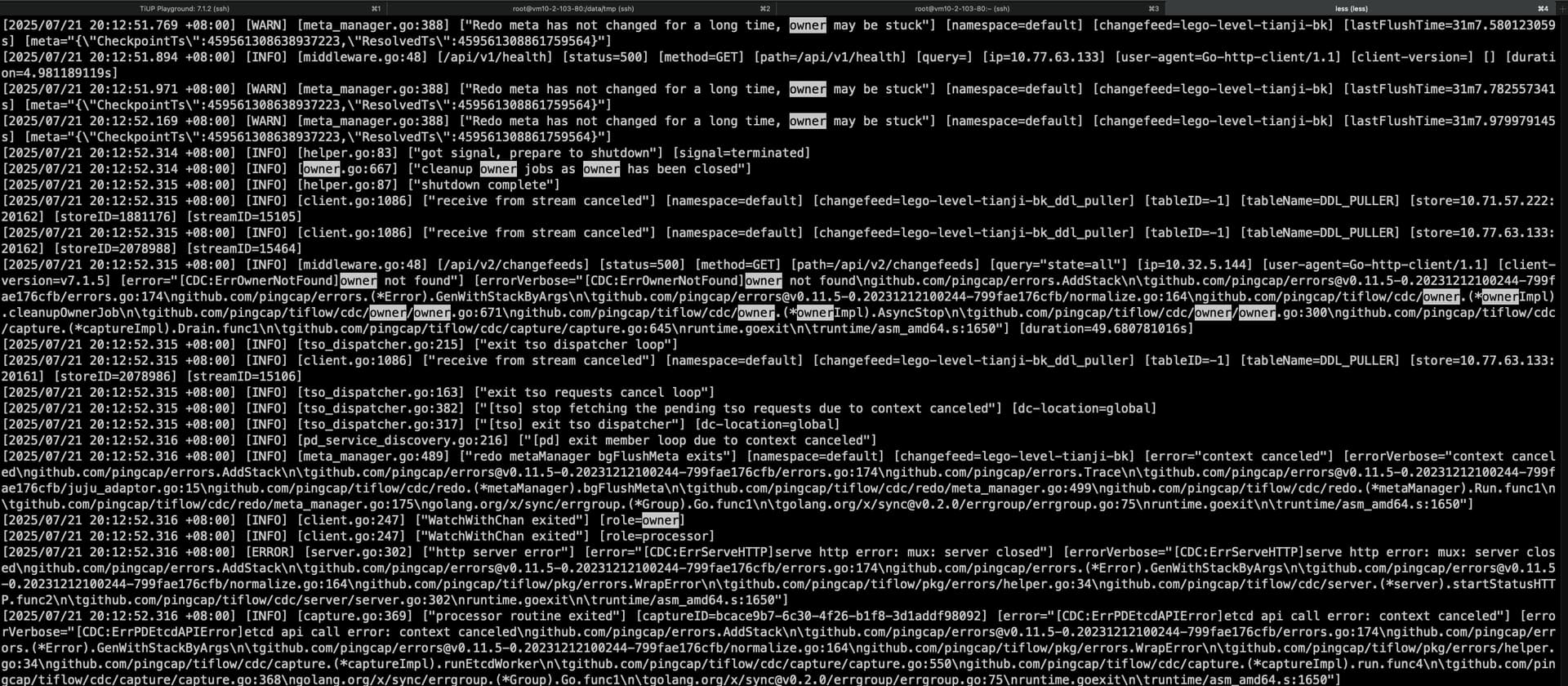
后面看日志有 [2025/07/21 20:12:52.314 +08:00] [INFO] [helper.go:83] [“got signal, prepare to shutdown”] [signal=terminated]
看起来是主动关掉的 cdc 节点,当时应该有 owner 的,看是 222 这个节点 cdc 就是,应该是关闭之后 owner 没选出来?
你要不现在试试删 changefeed 吧。
WalterWj
(王军 - PingCAP)
18