tidb 4.0.13版本
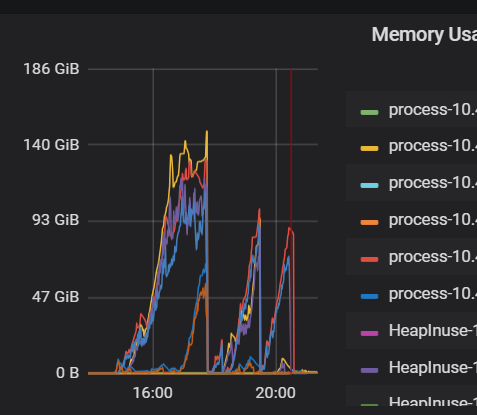
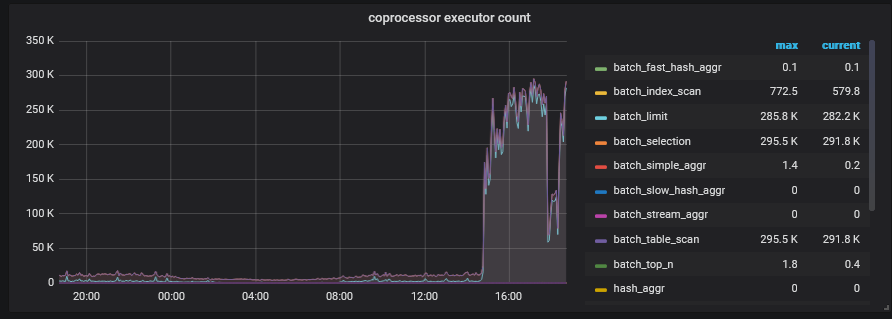
现象:tidb节点内存飙升到140多GB,排查发现【coprocessor executor count】这个监控指标有些异常,但是找不到排查思路。
这是一个老业务的集群,业务平时不会做改动了,已经稳定跑了两年。
tidb 4.0.13版本
现象:tidb节点内存飙升到140多GB,排查发现【coprocessor executor count】这个监控指标有些异常,但是找不到排查思路。
这是一个老业务的集群,业务平时不会做改动了,已经稳定跑了两年。
cop 应该有数据扫的操作
你是 tidb-server 节点内存突增还是 tikv 的高。
如果是 tidb-server 节点内存突增,看下这个节点慢日志有没有内存用的多的 sql 看下增加前后 tidb.log expensive 关键字的日志,里面有记录耗资源高的 sql
tidb内存高,后来我们是把gc时间从24h调整到2h,后来【 coprocessor executor count】指标才下来,然后重启tidb节点内存才没有飙升,之前重启tidb节点一会就又升上来了。
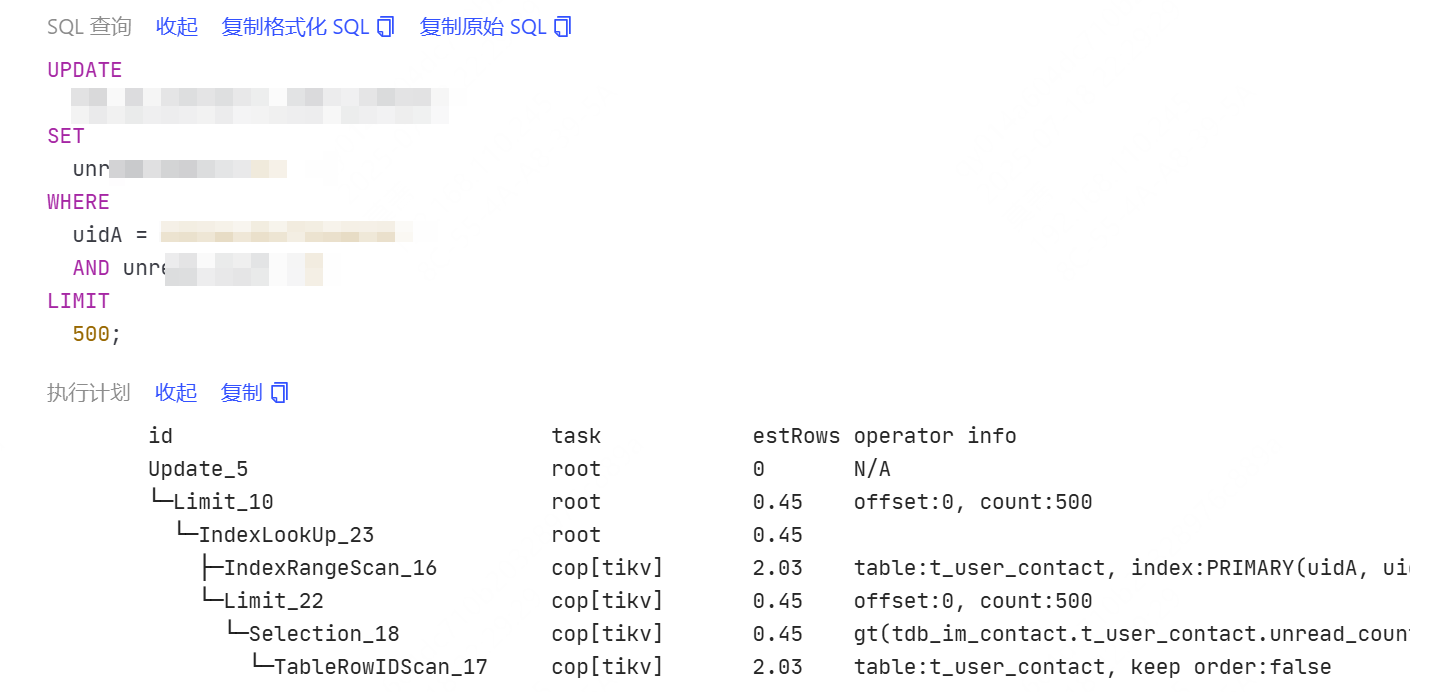
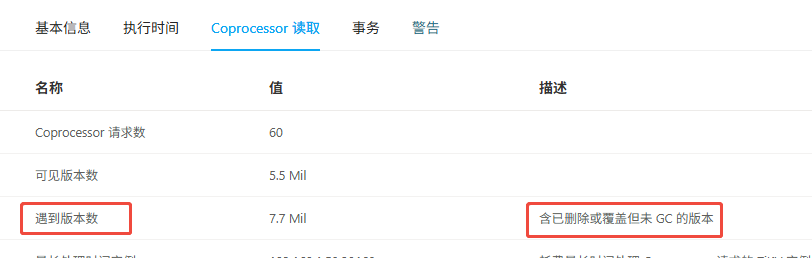
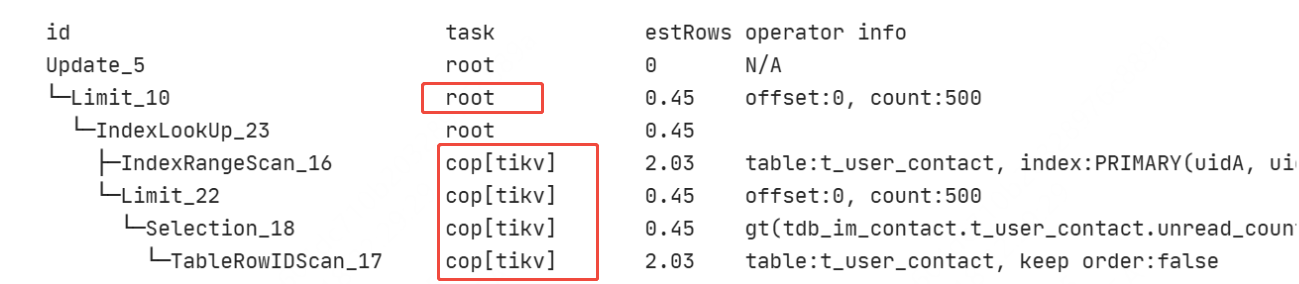
现在的疑问是,这个集群跑了很久了,gc一直都是24h,然后业务也没做什么变更上线之类,看慢查询的执行计划,不管update还是select,都是IndexLookUp,IndexRangeScan,改了gc时间以后,内存降下来了,执行计划也都是IndexLookUp,IndexRangeScan,搞不懂哪里出了问题,诱因是啥?
另外 从出现问题到结束expensive query总共记录的不到200条,都是update,然后从tidb日志看到的update语句消耗的内存200-300MB,即便是这样算下来也就60GB的内存,但是实际用最大的时候超过140GB了。另外一个疑问就是,这个update为啥需要那么多内存,跟gc时间过长有关系吗?
expensive sql 是 60s 抓一次,并不是实时的。而且 sql 统计内存和系统分配内存也不是完全能对上,低于实际值也正常。
你可以先判断下这个 update 的内存消耗正常么。
比如对应符合条件的数据是不是很多,有没有大字段。
expensive sql 包含正在执行的语句么?dashboard的慢查询是只统计已执行完的语句。
包涵的,1 是超过 60s 二是超过一定扫描量就会记录 expensive sql
看了一些数据应该是没有大字段的,一行数据基本不会超过0.5KB,然后跟业务确认了一下,有些update会匹配到比较多的数据,比如几十万,然后我有疑问update不是加了limit 500了吗,还是会把所有符合条件的数据从tikv拿到tidb吗?
因为是分布式的,不是直接去tikv取500条,而是tikv返回符合条件的数据给tidb,tidb再取前500
针对limit语句是有相关的优化,我记得是下推到tikv了
日志里面DML的多吗