tikv持久化使用的是ceph rbd,在压测juicefs时候,tikv作为meta的lat略高,会影响到读写性能,使用k8s部署了10节点的tikv和3节点的pd,tikv的每个pod的limit在20c、40G内存的情况,还是会出现lat高的问题,版本是7.1
1 个赞
tikv 对磁盘要求比较高,你磁盘性能如何
ssd的盘
你可以发现监控数据,慢是慢到多少
几十到几百,在JUICEFS没有IO时,是0.X.
你现在是怀疑 tikv 是慢的地方,所以你要看 tikv 的监控,要是没部署监控,可以参考这个:https://docs.pingcap.com/zh/tidb-in-kubernetes/dev/monitor-a-tidb-cluster/
1 个赞
kbq exec -n tikv juicefs-tikv-pd-0 – /pd-ctl --pd=“127.0.0.1:2379” store | grep “leader_count”
"leader_count": 33,
"leader_count": 0,
"leader_count": 37,
会出现这个。
[server]
grpc-compression-type = "gzip"
grpc-concurrency = 16
grpc-raft-conn-num = 16
grpc-stream-initial-window-size = "16MB"
grpc-keepalive-time = "3s"
grpc-keepalive-timeout = "1s"
grpc-timeout = "5s"
[readpool.storage]
use-unified-pool = false
high-concurrency = 16
normal-concurrency = 12
low-concurrency = 8
[readpool.coprocessor]
use-unified-pool = true
[storage]
scheduler-worker-pool-size = 12
scheduler-pending-write-threshold = "200MB"
reserve-space = "10GB"
enable-async-apply-prewrite = true
block-cache-size = "18GB"
[raftstore]
store-pool-size = 6
apply-pool-size = 6
raft-log-gc-tick-interval = "500ms"
raft-log-gc-threshold = 32
raft-log-gc-count-limit = 6000
raft-log-gc-size-limit = "64MB"
snap-mgr-gc-tick-interval = "30s"
snap-max-write-bytes-per-sec = "300MB"
raft-base-tick-interval = "500ms"
raft-heartbeat-ticks = 2
raft-election-timeout-ticks = 20
raft-max-size-per-msg = "8MB"
raft-max-inflight-msgs = 256
raft-entry-max-size = "8MB"
[coprocessor]
region-max-size = "64MB"
region-split-size = "48MB"
region-max-keys = 640000
region-split-keys = 480000
[pd-client]
pd-retry-interval = "100ms"
pd-retry-max-count = 20
[rocksdb]
max-open-files = 40960
max-background-jobs = 12
max-background-flushes = 6
max-sub-compactions = 6
max-manifest-file-size = "128MB"
create-if-missing = true
db-write-buffer-size = "512MB"
write-buffer-size = "128MB"
max-write-buffer-number = 6
min-write-buffer-number-to-merge = 2
compression-per-level = ["no", "no", "lz4", "lz4", "lz4", "zstd", "zstd"]
bottommost-level-compression = "zstd"
[rocksdb.defaultcf]
compression-per-level = ["no", "no", "lz4", "lz4", "lz4", "zstd", "zstd"]
write-buffer-size = "128MB"
max-write-buffer-number = 6
min-write-buffer-number-to-merge = 2
level0-file-num-compaction-trigger = 2
level0-slowdown-writes-trigger = 16
level0-stop-writes-trigger = 20
max-bytes-for-level-base = "256MB"
max-bytes-for-level-multiplier = 6
target-file-size-base = "64MB"
target-file-size-multiplier = 1
block-size = "16KB"
block-cache-size = "15GB"
cache-index-and-filter-blocks = true
pin-l0-filter-and-index-blocks = true
bloom-filter-bits-per-key = 10
whole-key-filtering = true
[rocksdb.writecf]
compression-per-level = ["no", "no", "lz4", "lz4", "lz4", "zstd", "zstd"]
write-buffer-size = "256MB"
max-write-buffer-number = 6
min-write-buffer-number-to-merge = 2
level0-file-num-compaction-trigger = 2
level0-slowdown-writes-trigger = 16
level0-stop-writes-trigger = 20
target-file-size-base = "32MB"
max-bytes-for-level-base = "128MB"
block-cache-size = "3GB"
[rocksdb.lockcf]
write-buffer-size = "32MB"
max-write-buffer-number = 4
min-write-buffer-number-to-merge = 2
block-cache-size = "512MB"
[titan]
enabled = false
这只能说明 leader 不均衡,正常不会这样的,还是得看监控

1048576000 bytes (1.0 GB, 1000 MiB) copied, 8.44715 s, 124 MB/s 这个顺序写的速度。在pvc上
看下 grpc、raftio、rocksdb-kv 这几块
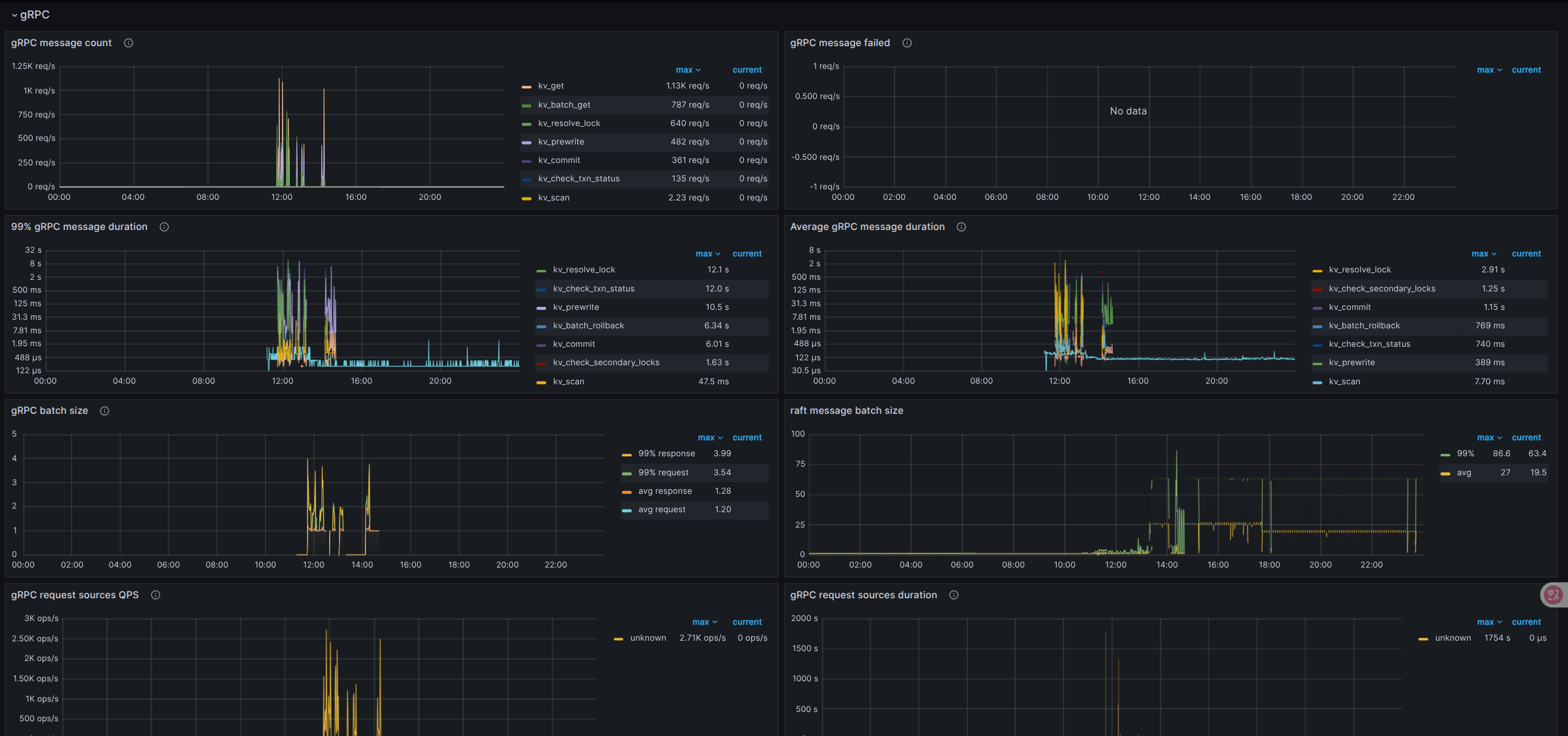
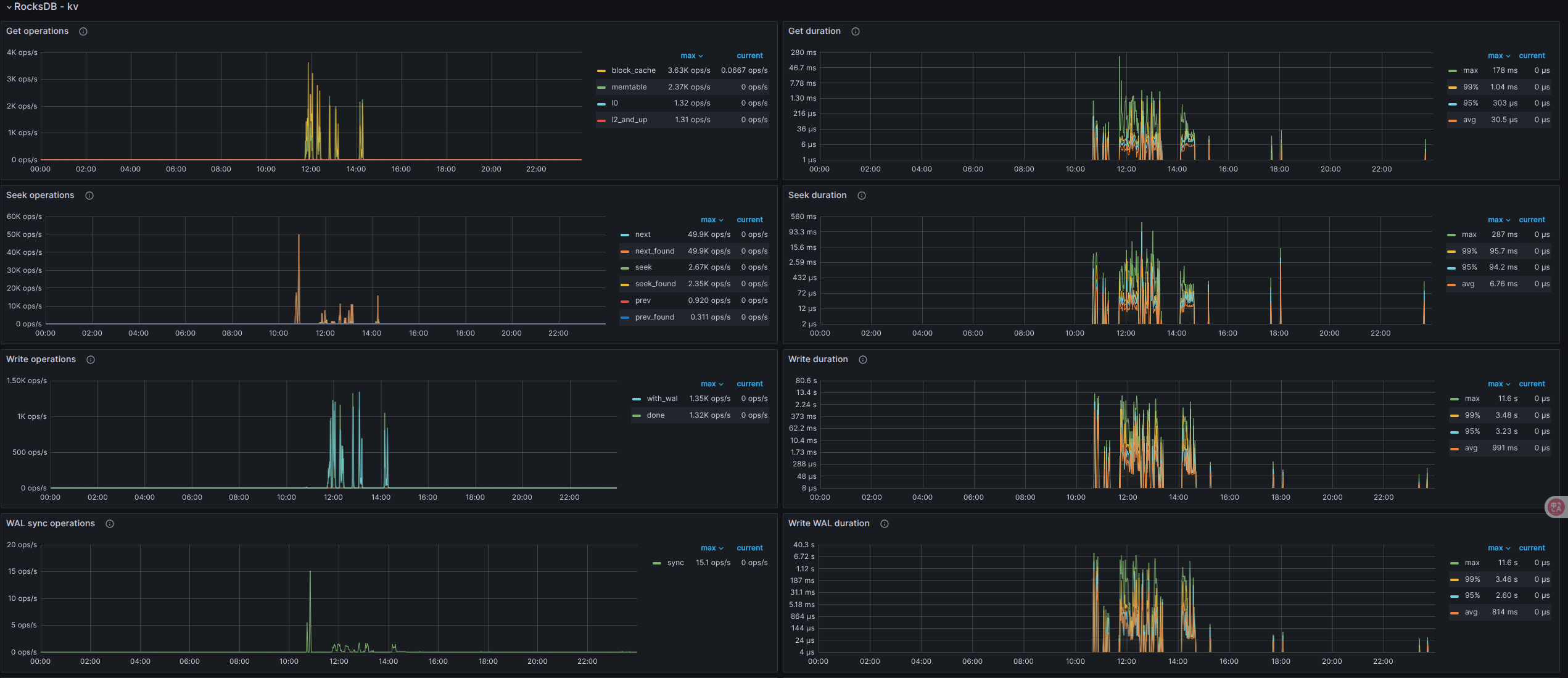
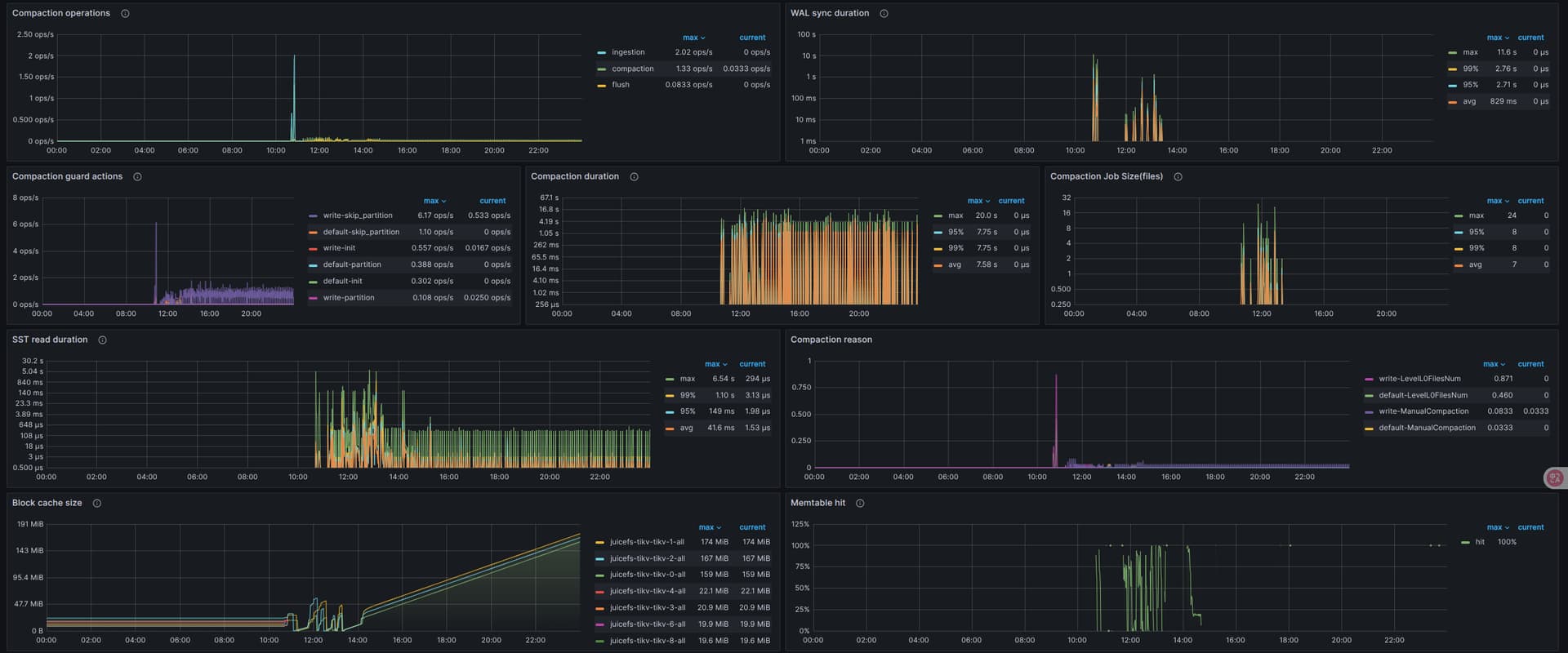
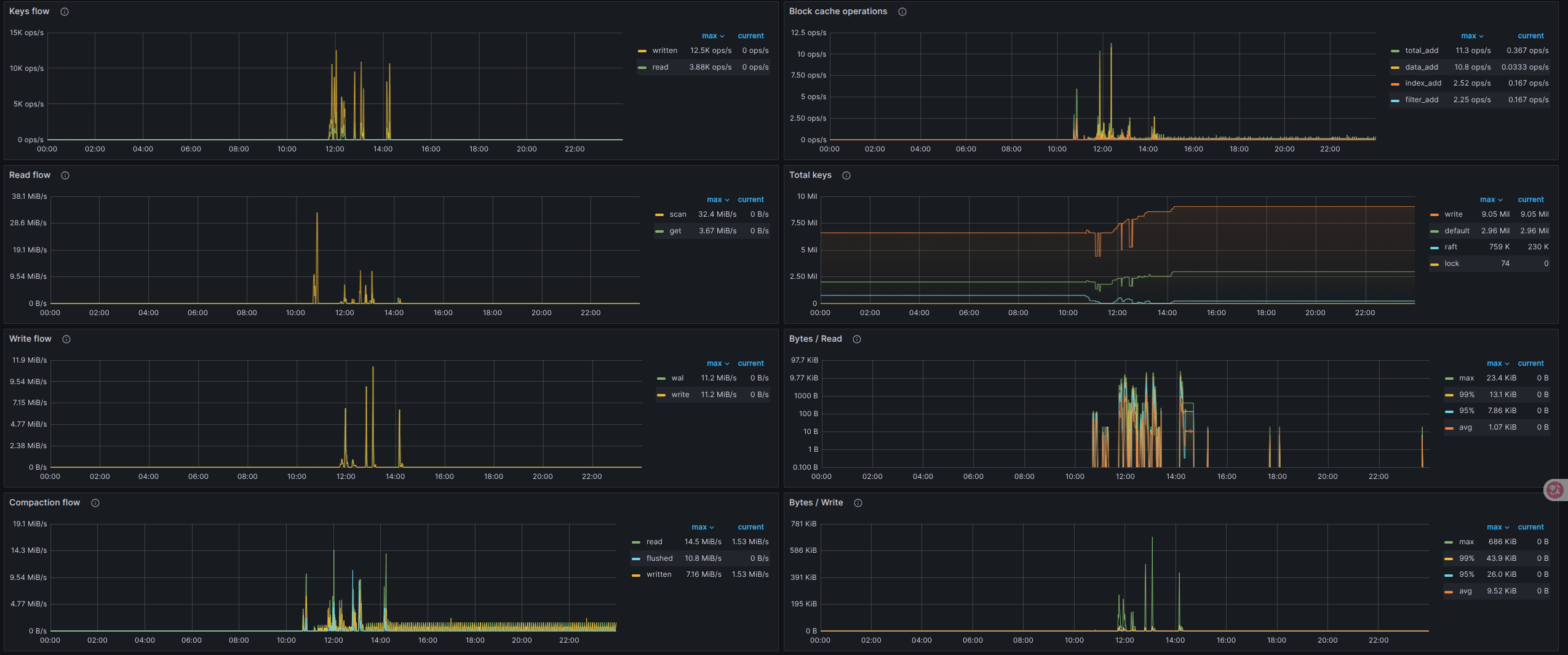

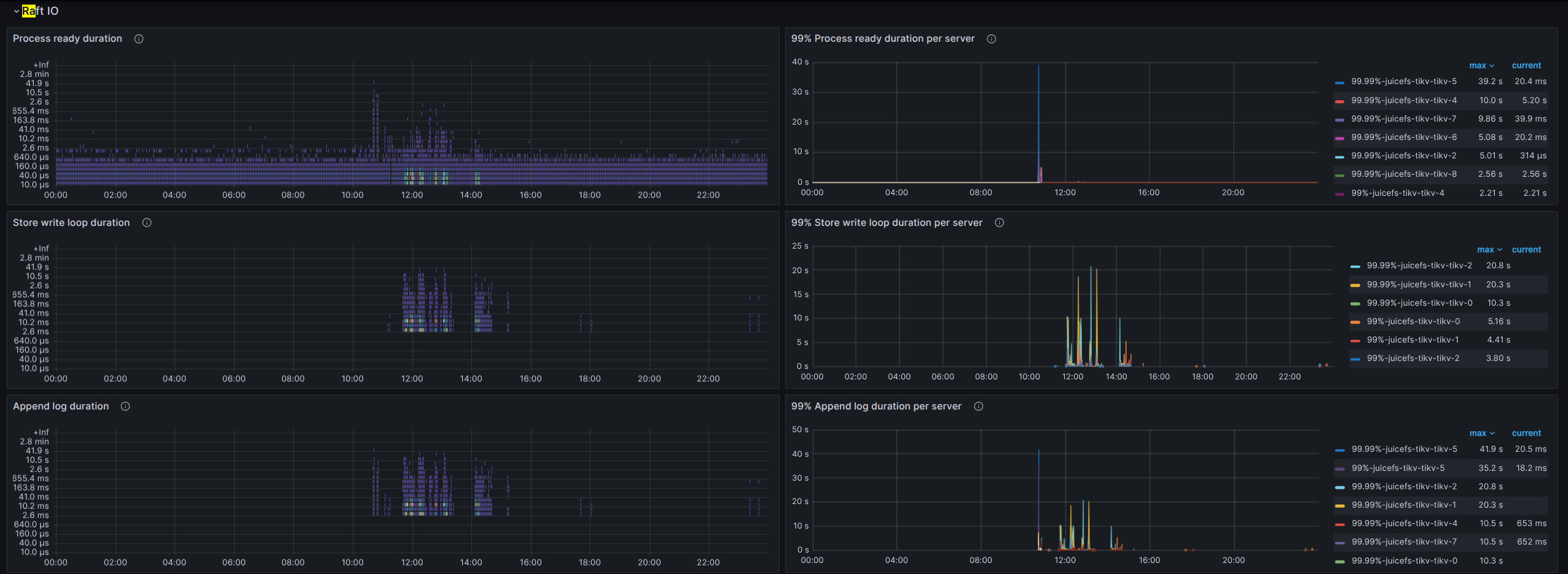
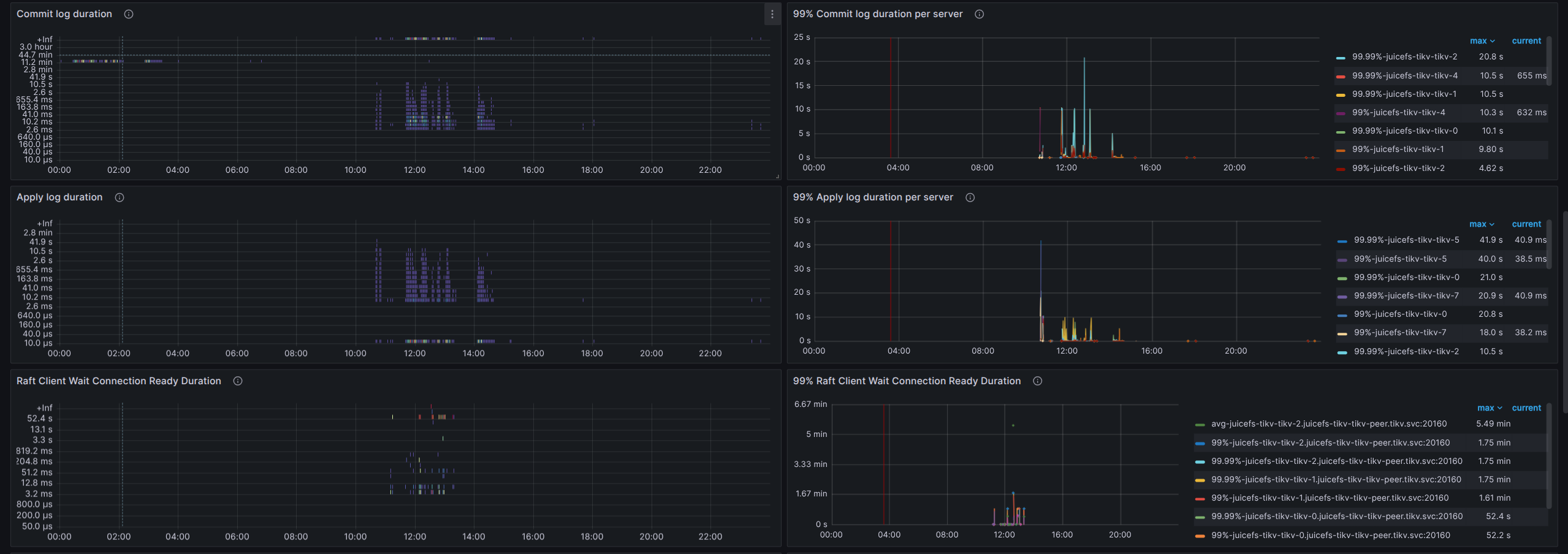
盘不行,建议换好一些的盘,能用本地 nvme 磁盘最好
1 个赞
emmm 多谢 多谢
磁盘性能差些,tikv对磁盘性能要求较高
用全闪会不会好一些
瓶颈在磁盘上?
使用ssd试试
ssd吧。。