看到有日志输出找了一个有提示reion_id和和ledaerID信息的查了一下 信息完全正常。
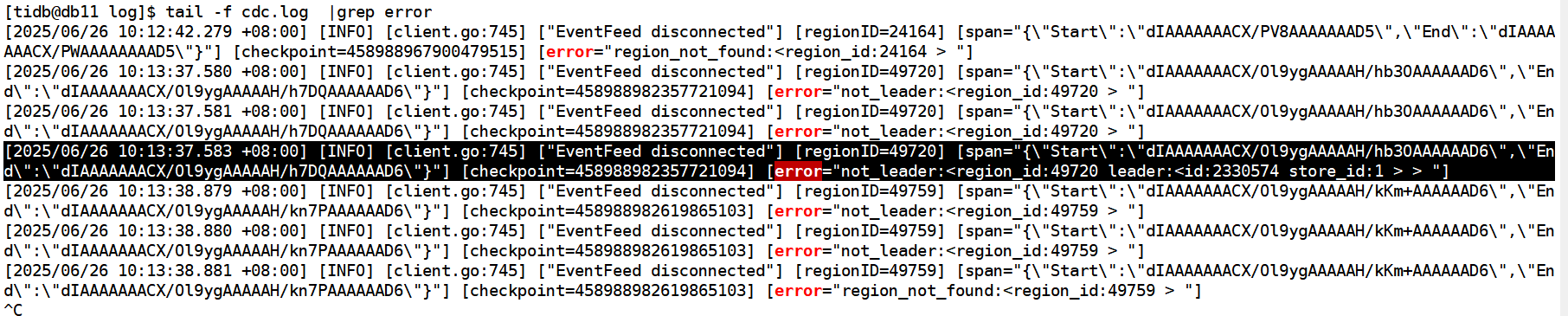
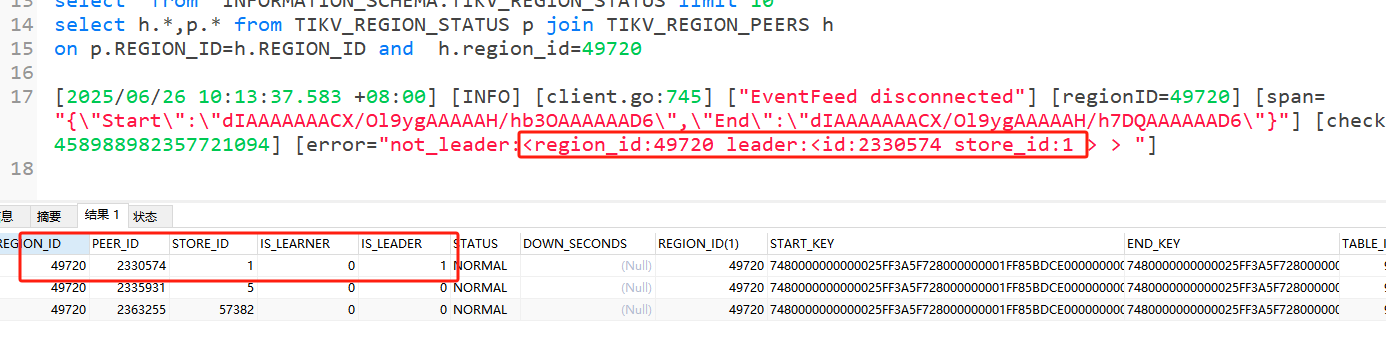
第一个error是昨天下午3点开始
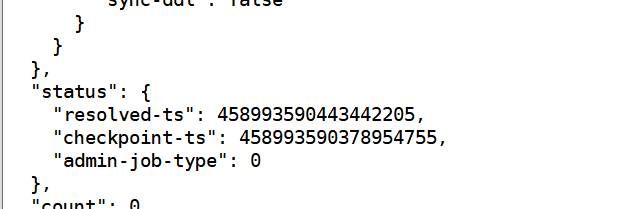
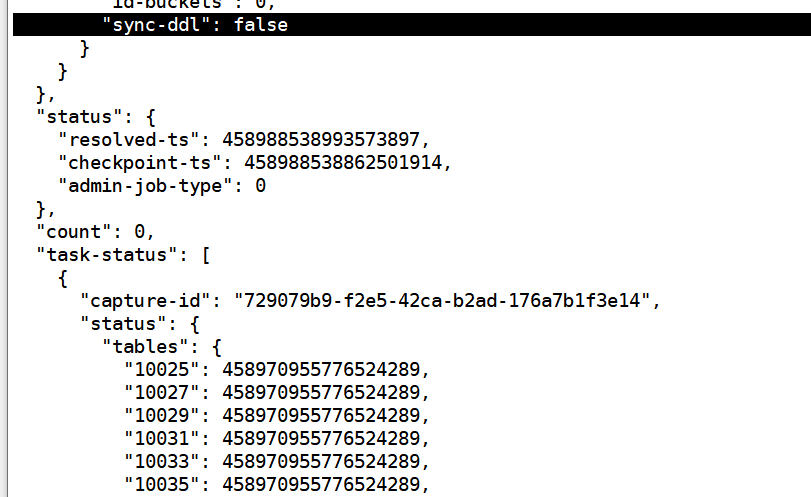
但是看状态他是有在正常同步吧。先这个值有在一直增加
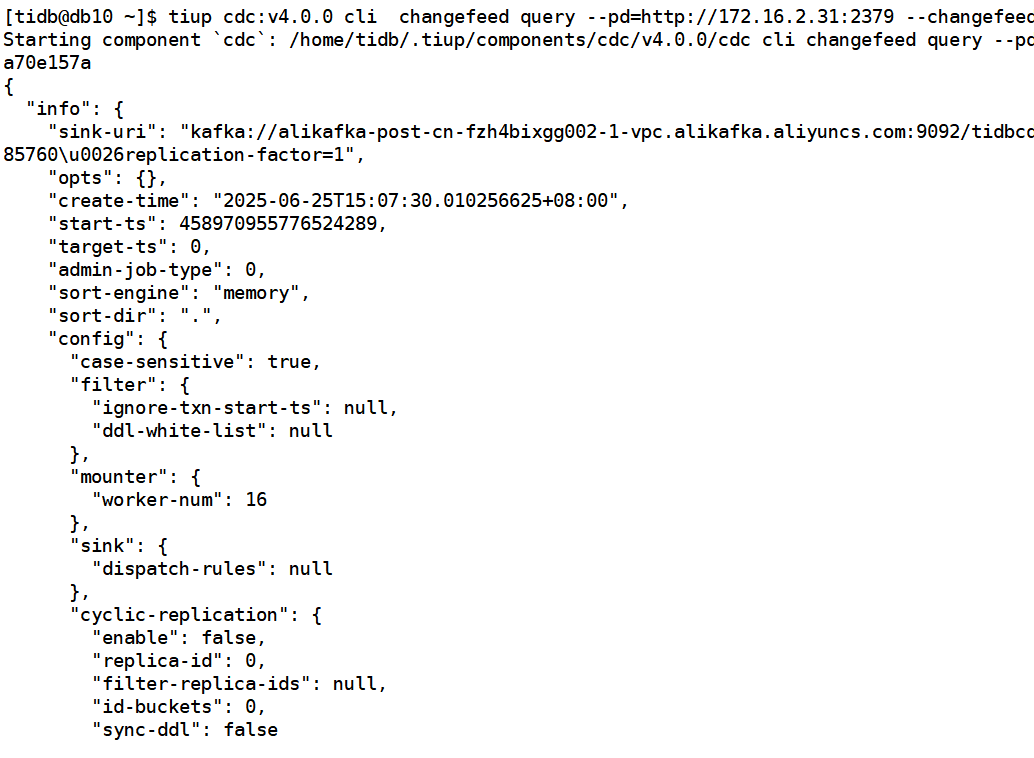
cdc cli changefeed query 看下完整的cdc配置,发出来看看
下游是 kafka 吗?kafka 的版本是多少?
看一下tidb 有没有频繁 ddl 操作:tidb cdc 实测对于ddl 操作处理极慢。对应的的现象,我猜测一下,ddl 操作导致 tidb cdc 变慢,同时 ddl 操作也会导致 cpu 上升,变慢了,你停下来了,然后ddl 操作完成,你启动了ticdc ,速度变快了,循环往复
也可以考虑下:可能是部分热点region导致cdc延迟,你可以看下能不能先把热点打散下
中间好像是有过DDL操作。有两三次建表重建表相关。这是测试环境。没有什么数据,应该也不会有什么热点数据吧
下游ticdc 只有一个topic和一个分区。
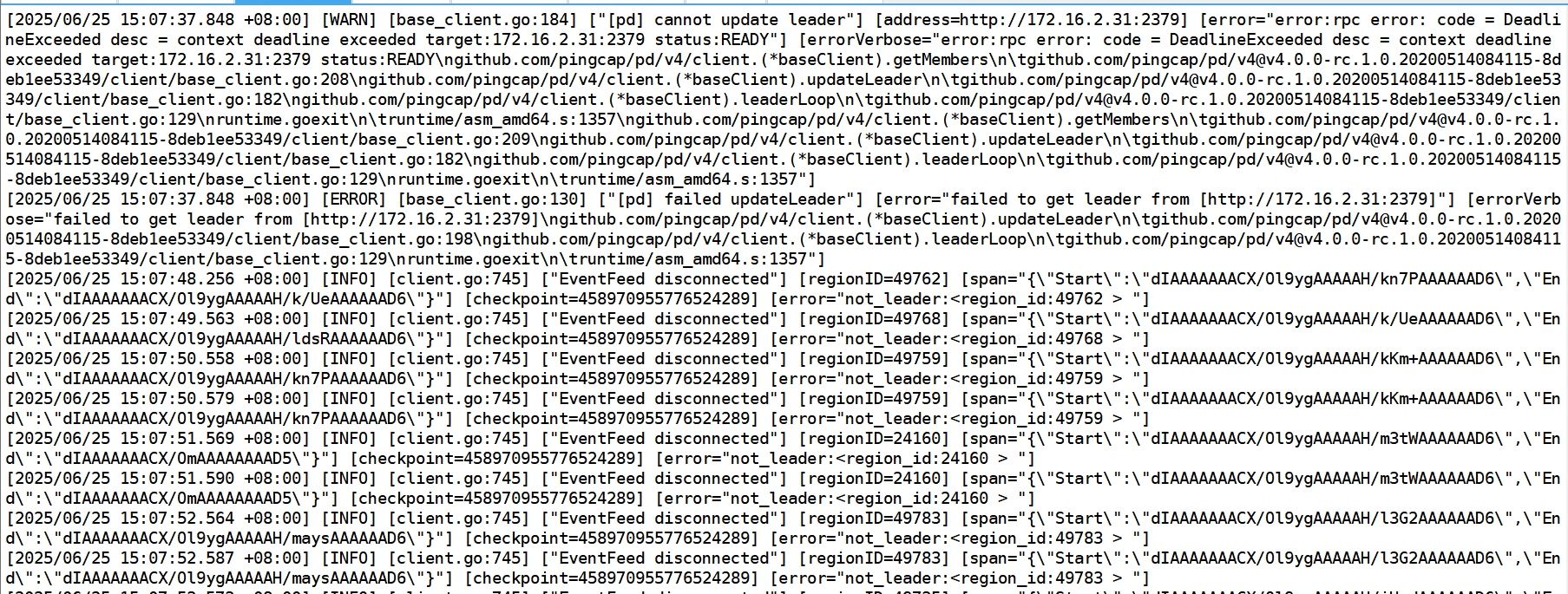
最早的一个报错,说是没有更新pd ledaer 获取leader失败。
[2025/06/25 15:07:37.848 +08:00] [ERROR] [base_client.go:130] [“[pd] failed updateLeader”] [error=“failed to get leader from [http://172.16.2.31:2379]”] [errorVerbose=“failed to get leader from [http://172.16.2.31:2379]\ngithub.com/pingcap/pd/v4/client.(*baseClient).updateLeader\n\tgithub.com/pingcap/pd/v4@v4.0.0-rc.1.0.20200514084115-8deb1ee53349/client/base_client.go:198\ngithub.com/pingcap/pd/v4/client.(*baseClient).leaderLoop\n\tgithub.com/pingcap/pd/v4@v4.0.0-rc.1.0.20200514084115-8deb1ee53349/client/base_client.go:129\nruntime.goexit\n\truntime/asm_amd64.s:1357”]
从日志看,主要表现为找不到某些Region的Leader或者Region不存在。这通常与TiKV集群的状态有关,可能是由于网络问题、节点故障或Region Leader选举等问题导致的。